大数据生态圈里的一致性算法
大数据生态圈中,保证一致性的方式举不胜举
- Hadoop 用 ZooKeeper(Zab,即支持事务顺序的 Paxos)
- Elasticsearch 用 Hash 路由算法(而非一致性 Hash)
- Cassandra 用 Gossip 闲话算法
- Redis 用 Raft 选举算法
他们各有什么区别,为什么会如此选型?
Paxos 选举算法
Paxos 是最先解决拜占庭将军问题的算法,利用过半选举的机制,保证了集群数据副本的一致性(微服务中服务注册与发现的场景,其实已经不再适用了)
Raft 选举算法
Redis 使用 Raft 实现了自己的分布式一致性。Raft 本身和 Paxos 并没有场景上的区别。更多的是,协议上的简化、Term 概念的强化、Log 只会从 Leader 到 Follower 单向同步,使得实现起来会很方便
Zab 原子广播协议
Hadoop 偏向于离线的海量数据处理,利用 ZooKeeper 来保证数据副本的一致性,是最为合适的
Hash 路由算法
Elasticsearch 集群接收到为文档创建索引的请求时,需要选择在哪一个 shard(完整且独立的 Lucene 索引实例)上对文档进行索引。Elasticsearch 采用的是 djb2 哈希算法(俗称 times33),对要索引文档默认或指定的 key 进行哈希 hash(key),然后再对 Elasticsearch 集群中 shard 的数量 n 进行取模,即 $hash(key) \, mod \, n$
一致性 Hash
用于对数据存储进行负载均衡的算法。最新的进展,是在去年 Google 发表的一篇 有界负载的一致性 Hash 算法的论文。该算法保证了负载均衡一致性和稳定性的同时,在均匀性方面做出了实质性地改进。同时,Consistent Hashing with Bounded Loads 算法 也在 HaProxy 开源项目中得以应用,有效减少了其 8 倍的缓存带宽
Gossip 闲话算法
Gossip 主要被 Cassandra 用于实现其分布式一致性。因为 Cassandra 框架,更看重 去中心化 和 容错 的特性,在不违背 CAP 定理的情况下,能够接受 最终一致性
实战一致性算法
分布式存储
Key-value Store
架构思考
HashMap
HashMap 的数据是存在内存里的,一旦进程重启,会有丢数据的风险。同时,数据流一旦到了 TB / PB 级别,会存在硬件方面的瓶颈。另外,需要考虑 Key 相同的情况下,需要处理覆盖的问题
Berkeley DB
实际上是一个增强版的 HashMap,从一个简单的键值对存储,进化到可以管理并行访问、支持事务、数据同步等
Kyoto Cabinet
HashTable 和 B+ Tree 的结合,不过在到达一定数量级,性能下降比较厉害
LevelDB / HBase
利用 LSM Tree 实现了读写分离、顺序写入等功能
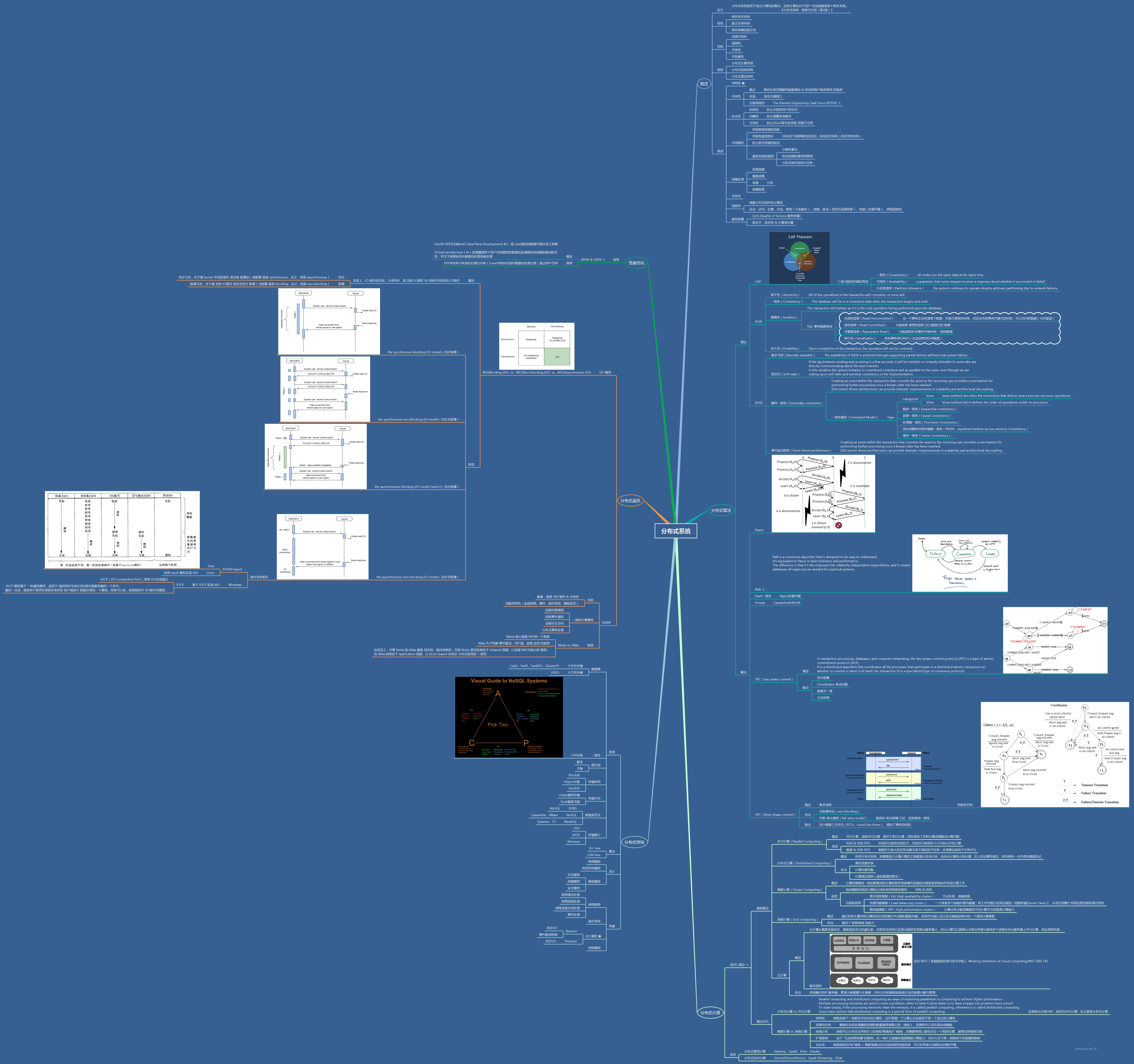
知识树
参考资料
Book
- 《分布式系统:原理与范型(第2版)》
- 《分布式系统:概念与设计(原书 第5版)》
- 《大规模分布式存储系统:原理解析与架构实战》
- 《分布式数据库:管理系统实践》
- 《分布式数据库系统原理(第3版)》
- 《Distributed systems for fun and profit》
Blog
Paper
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| 大数据 | |
| 算法 | |
| 数据库 |