搜索引擎 Elasticsearch
Elasticsearch 是什么?
Elasticsearch™ 是一款基于 Lucene 的搜索引擎,不但稳定、可靠、快速,同时具备良好的水平扩展能力
特性
- 功能丰富,且开箱即用
- 横向可扩展性
- 分片机制更好地解决热点问题
- 多副本有效保证了高可用
- 精确的熔断器机制
- 社区庞大,生态完善
主要概念
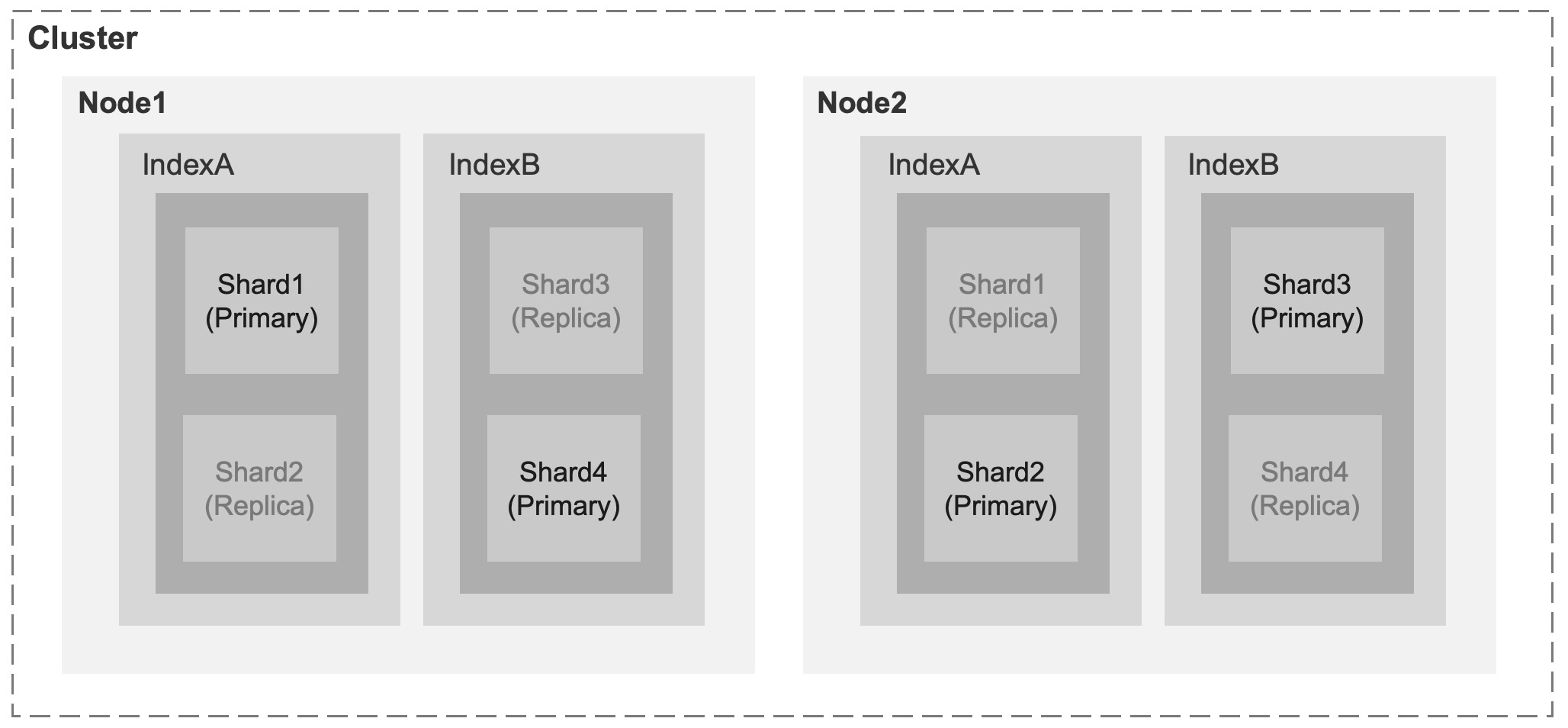
Cluster 集群
在一个分布式系统里面,可以通过多个 Elasticsearch 节点组成一个集群。集群中会动态选举出一个主节点,保证了 Elasticsearch 集群不存在单点故障
在同一子网内,只需要将进程设置为相同的集群名,Elasticsearch 就会把这些集群名相同的进程自动组成一个集群。集群中各节点间的通讯和数据负载均衡,全部都由 Elasticsearch 自动管理
Node 节点
每一个 Elasticsearch 进程称为一个 Node 节点。在测试环境中,可以在一台服务器上运行多个 Elasticsearch 进程;但生产环境中,则建议每台服务器只运行一个 Elasticsearch 进程
Index 索引
Elasticsearch 中的索引是文档数据存储的地方,相当于是传统关系数据库中的 DataBase 概念。更多逻辑上的对应关系,如下表所示:
| Relational DB | HBase | Elasticsearch | 说明 |
|---|---|---|---|
| Database | NameSpace | Template | 一组索引的模板配置 |
| Table | Table | Index | 索引 |
| Row | RowKey | Document | 文档,和 Lucene 概念一致 |
| Column + Value | Cell | Field | 如果将文档理解为 JSON,那么 Field 就是字段和值 |
| - | - | Term | 检索的基本单位,相当于是文本中的一个词 |
| - | - | Token | Term 内容、类型,以及 Term 在文本中的起始及偏移 |
Shard 分片
Elasticsearch 会把一个索引拆分为多个更细粒度的索引,并称之为 Shard
完成分片之后,就可以把各个 Shard 分配到不同的节点中去。同时,Elasticsearch 会确保两个相同的 Shard 不会同时存在于一个 Node 上
Replica 副本
Elasticsearch 的每一个 Shard 分片都可以有多个副本,而每一个副本也都是分片的完整拷贝。如此设计的好处是,既可以提升查询速度,也能提高系统的容错性
一旦 Elasticsearch 的某个节点数据损坏或者服务不可用的时候,那么就可以用其他节点来代替故障的节点,以达到高可用的目标
Recovery 故障恢复
Elasticsearch 的 Recovery 代表的是数据恢复或者称之为数据重新分布
当 Elasticsearch 集群中,有节点加入或退出时,它会根据机器负载对索引分片进行重新分配
River 数据源
River 代表的是一个数据源,这也是同步数据到 Elasticsearch 的一个方法
主要流程是读取 River 中的数据,再将其索引到 Elasticsearch 中,并以插件方式对外提供服务。官方支持的 River 类型有 CouchDB、RabbitMQ、Twitter、Wikipedia 等
Gateway 时空门
Gateway 是 Elasticsearch 索引的持久化存储方式,Elasticsearch 默认会先把索引存放到内存中去,当内存满了的时候再持久化到硬盘里。之后,当 Elasticsearch 集群重启时,就会从 Gateway 中读取索引数据
Gateway 支持多种存储媒介,包括本地文件系统(默认)、分布式文件系统、HDFS 和 S3 云存储服务 等
discovery.zen 节点发现
discovery.zen 是 Elasticsearch 的自动节点发现机制,支持基于配置(静态配置中设置的主机列表)与基于文件(定时加载外部文件中的主机列表)两种模式
集群会以广播的方式去寻找存在的 Node 节点,然后再通过多播协议来进行节点之间的通信,同时也支持点对点(P2P,Point 2 Point)的交互操作
Transport 通讯机制
Transport 是 Elasticsearch 内部的节点或者集群与客户端之间的交互方式,默认会使用 TCP 协议完成通讯
架构图
环境部署
单机版
下载
首先从官方的下载页面上,找到适合自己操作系统的安装包(这里我们以 MacOS 为例)
1 | $ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-darwin-x86_64.tar.gz |
解压
1 | $ tar zxvf elasticsearch-7.9.1-darwin-x86_64.tar.gz |
环境变量
1 | $ vim ~/.bashrc |
启动
1 | $ elasticsearch |
校验
1 | $ curl -XGET 'http://localhost:9200/_cluster/health' | python -m json.tool |
1 | { |
可视化
本地 Kibana
1 | # 下载 |
Kubernetes 版
安装 Helm Charts
1 | $ helm repo add bitnami https://charts.bitnami.com/bitnami |
校验
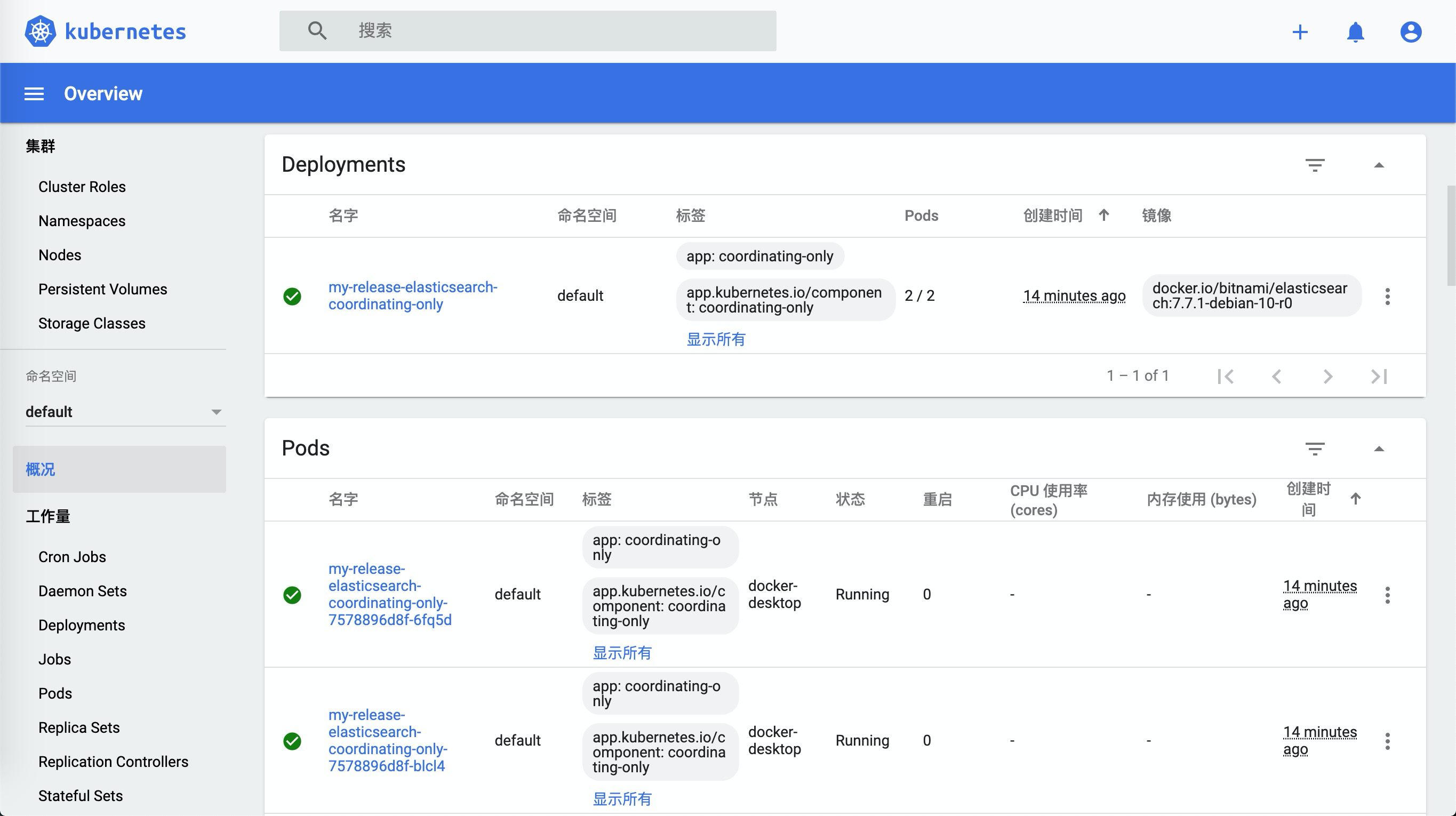
端口转发
1 | $ kubectl port-forward --namespace default svc/my-release-elasticsearch-coordinating-only 9200:9200 & |
1 | $ curl http://127.0.0.1:9200/ |
可视化
Kibana on Kubernetes
1 | $ helm repo add elastic https://helm.elastic.co |
实用技巧
写入数据
创建 Document
1 | POST yuzhouwan/_doc/ |
1 | { |
1 | { |
指定 Document ID
1 | POST yuzhouwan/_doc/1 |
1 | { |
1 | { |
再次写入相同 Doc ID 的记录后,会更新 _version
1 | { |
查询数据
匹配所有索引
1 | GET _search |
1 | { |
指定索引
指定某一个索引
1 | GET /yuzhouwan/_search |
1 | { |
指定多个索引
1 | GET /yuzhouwan01,yuzhouwan02/_search |
通配符匹配多个索引
1 | GET /yuzhouwan*/_search |
控制展示数量
由于默认只会展示 10 个匹配结果,所以需要设置 size 参数来调整
1 | GET /yuzhouwan/_search?size=100 |
1 | { |
1 | GET /yuzhouwan/_search |
1 | { |
指定返回字段
1 | GET /yuzhouwan/_search |
1 | { |
范围查询
1 | GET /yuzhouwan/_search |
1 | { |
聚合查询
Group Count
对 end_time 字段进行 group 分组,再进行 count 计数,并过滤
1 | GET /yuzhouwan/_search |
1 | { |
1 | { |
过滤查询
数组长度
1 | POST yuzhouwan/_doc/ |
1 | { |
1 | GET /yuzhouwan/_search |
1 | { |
删除数据
1 | POST yuzhouwan/_delete_by_query |
1 | { |
清理缓存
1 | # 查看缓存情况 |
索引
获取索引
1 | # 查看所有索引 |
1 | yellow open yuzhouwan jslqKujdSUu6LTymB3Lq9A 1 1 1 0 10kb 10kb |
获取 Mapping
1 | # 获取指定索引的 mapping |
更新 Mapping
1 | PUT /yuzhouwan/_mapping |
1 | { |
自动创建索引
默认的,action.auto_create_index 参数为 true,意味着任何索引都可以随着数据写入而被自动创建。反之,如果设置为 false 这不允许任何的索引被自动创建
1 | PUT _cluster/settings |
1 | { |
+*day*,-* 意味着除了满足 *day* 正则表达式的索引,不允许其他任何索引的自动创建
1 | PUT _cluster/settings |
1 | { |
TimeZone
1 | $ vim attack_alarm.json |
1 | { |
1 | $ curl -XPOST -H 'Content-Type: application/json' http://localhost:9200/yuzhouwan_201609/attack_alarm/_search -d @attack_alarm.json |
如果在构建 date 字段相关的查询是,可以直接传入 yyyy-MM-dd HH:mm:ss,SSS 格式的字符串,避免 +08:00 时区带来的困扰。也可以在程序中,将日期中的 local 时区去掉,从而使得日期和 Elasticsearch 本身的默认时区 +00:00 一致,具体写法如下
1 | QueryBuilders.rangeQuery(params.get("timeField")) |
Hot-warm
Elasticsearch 5.x 引入的新特性,可以通过 node.attr.box_type 参数,将 Elasticsearch 集群中部分高资源的节点配置为 hot,以存放需要频繁访问的数据,再将部分低资源的节点配置为 warm,以存放大量低频访问的数据。随后,在摄入业务数据的时候,可以通过设置 Index 索引的 index.routing.allocation.require.box_type 配置项,来指定数据具体存放在 hot 还是 warm 节点上。默认,可以将 Index 设置为 hot,在满足一定条件后,手动或通过 Curator 工具自动将冷数据设置为 warm
合并索引
1 | POST _reindex |
1 | { |
合并 Segment
通过合并 Shard 下的 Segment 数量来解决小文件的问题,具体命令如下:
1 | # 指定某一个索引 |
Shrink
介绍
Elasticsearch 5.x 引入的新特性,可以将一个索引中的 Shard 分片进行合并。而且其利用了操作系统的硬链接,使得该操作的完成可以控制在毫秒级。当然,如果操作系统不支持硬链接的话,则仍然需要拷贝 Segment 文件
使用
1 | POST /yuzhouwan_source_index/_shrink/yuzhouwan_target_index |
1 | { |
Rollup
介绍
Elasticsearch 6.6 引入的新特性,可以通过启动 Rollup 任务的形式,对现有的 Index 索引进行 Rollup,以生成预聚合的新索引
使用
命令行
1 | PUT _rollup/job/yuzhouwan |
1 | { |
Kibana
- 测试数据集
1 | PUT _template/yuzhouwan_by_hour |
1 | { |
1 | POST yuzhouwan_by_hour_2020020200/_doc/1 |
1 | { |
1 | POST yuzhouwan_by_hour_2020020201/_doc/1 |
1 | { |
- 设置 Rollup 任务的名称,选择哪些 Index 被 Rollup,以及指定被 Rollup 后的新 Index 名称
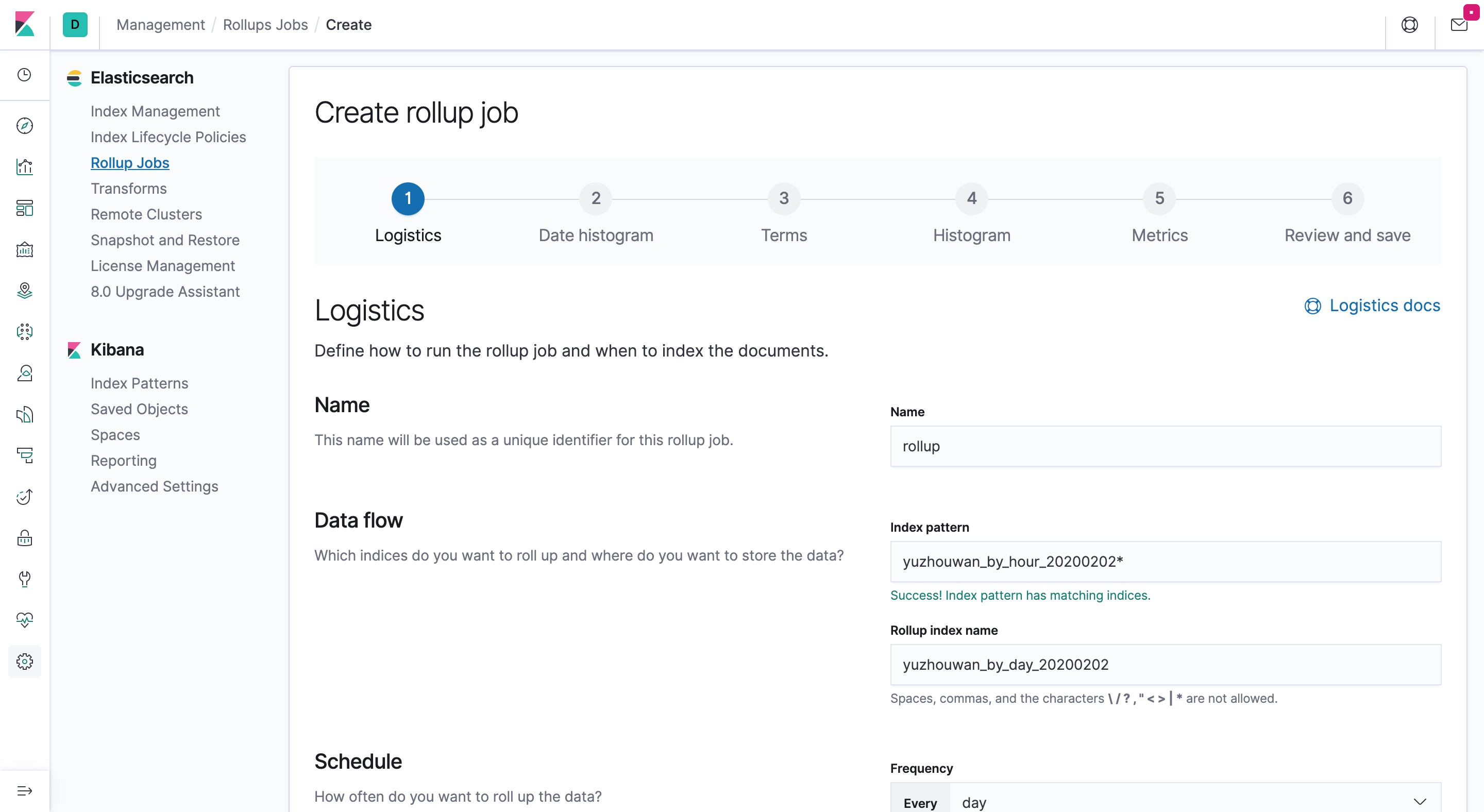
- 设置执行周期、批处理的大小、延迟多久执行
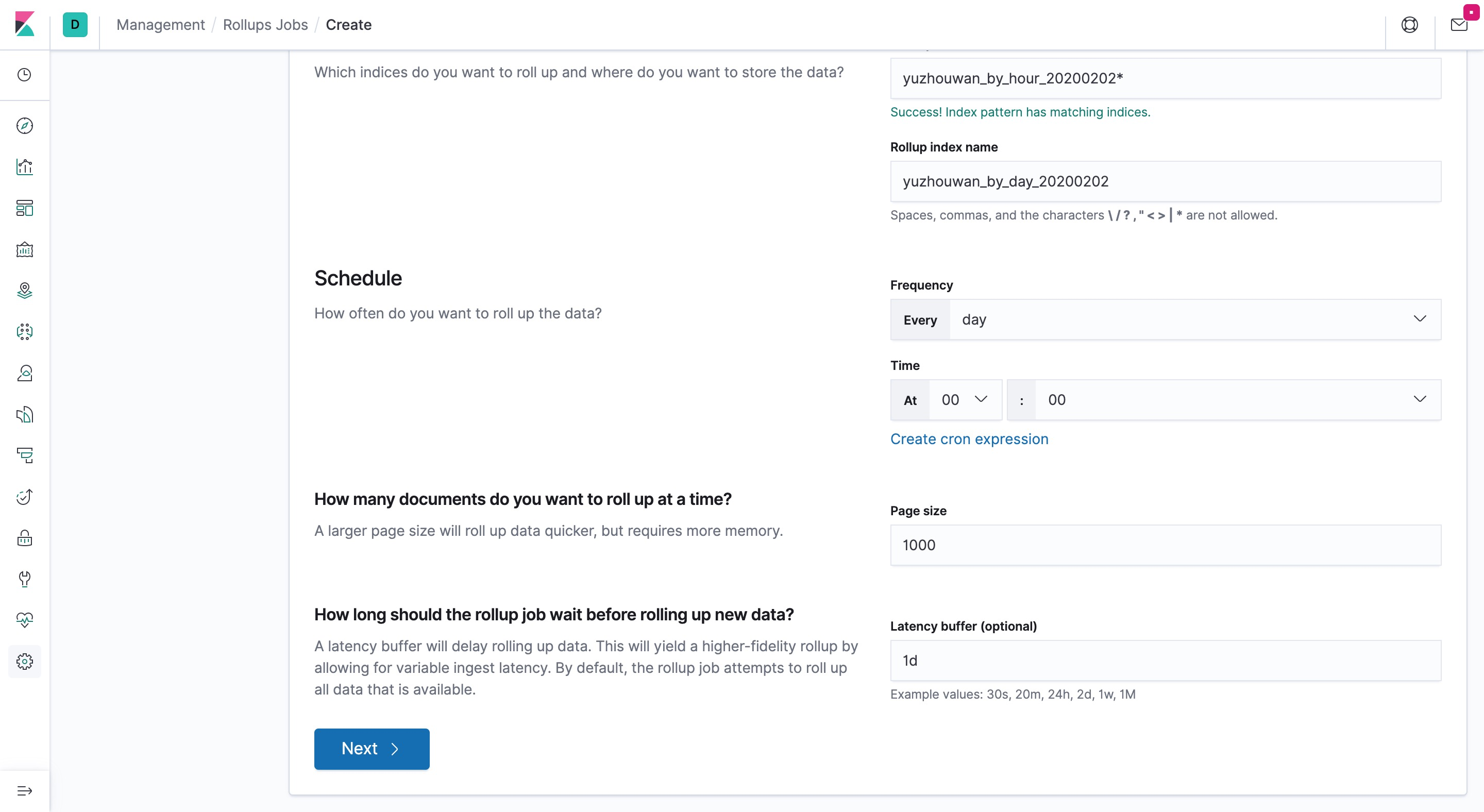
- 指定时间维度和 Rollup 的聚合粒度
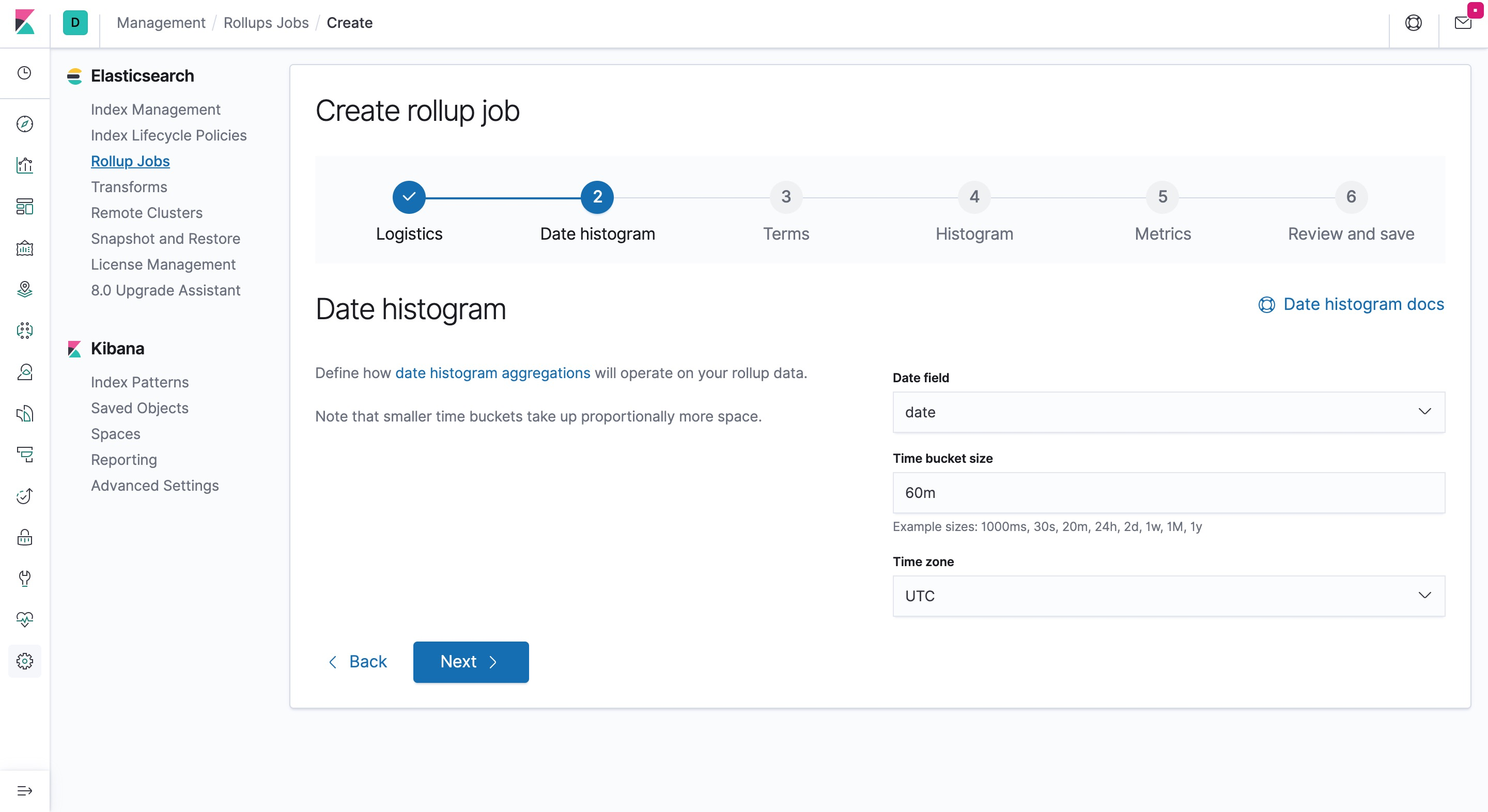
- 选择会被聚合查询的字段
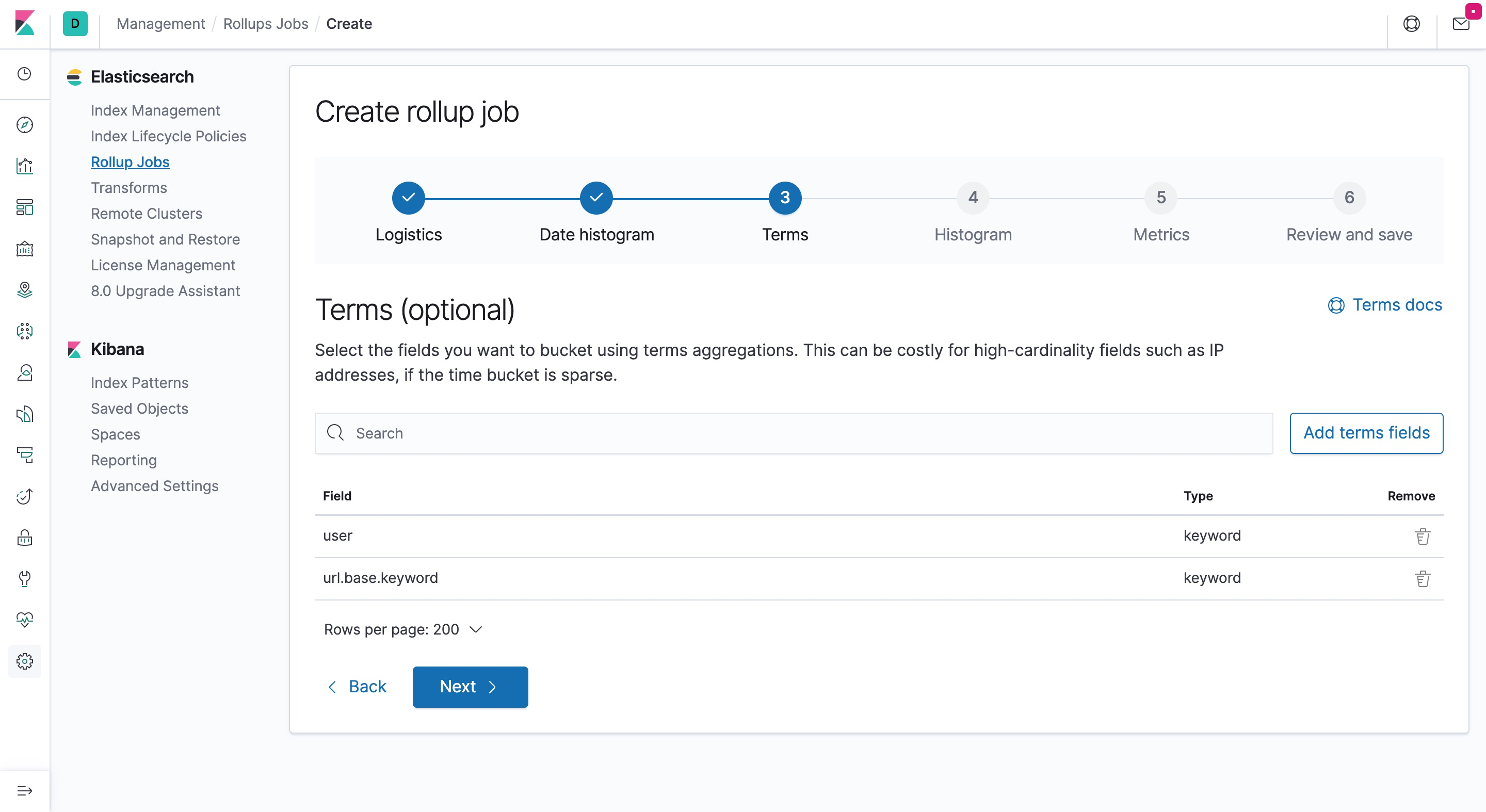
- 选择会被用来作为直方图展示的数值型字段
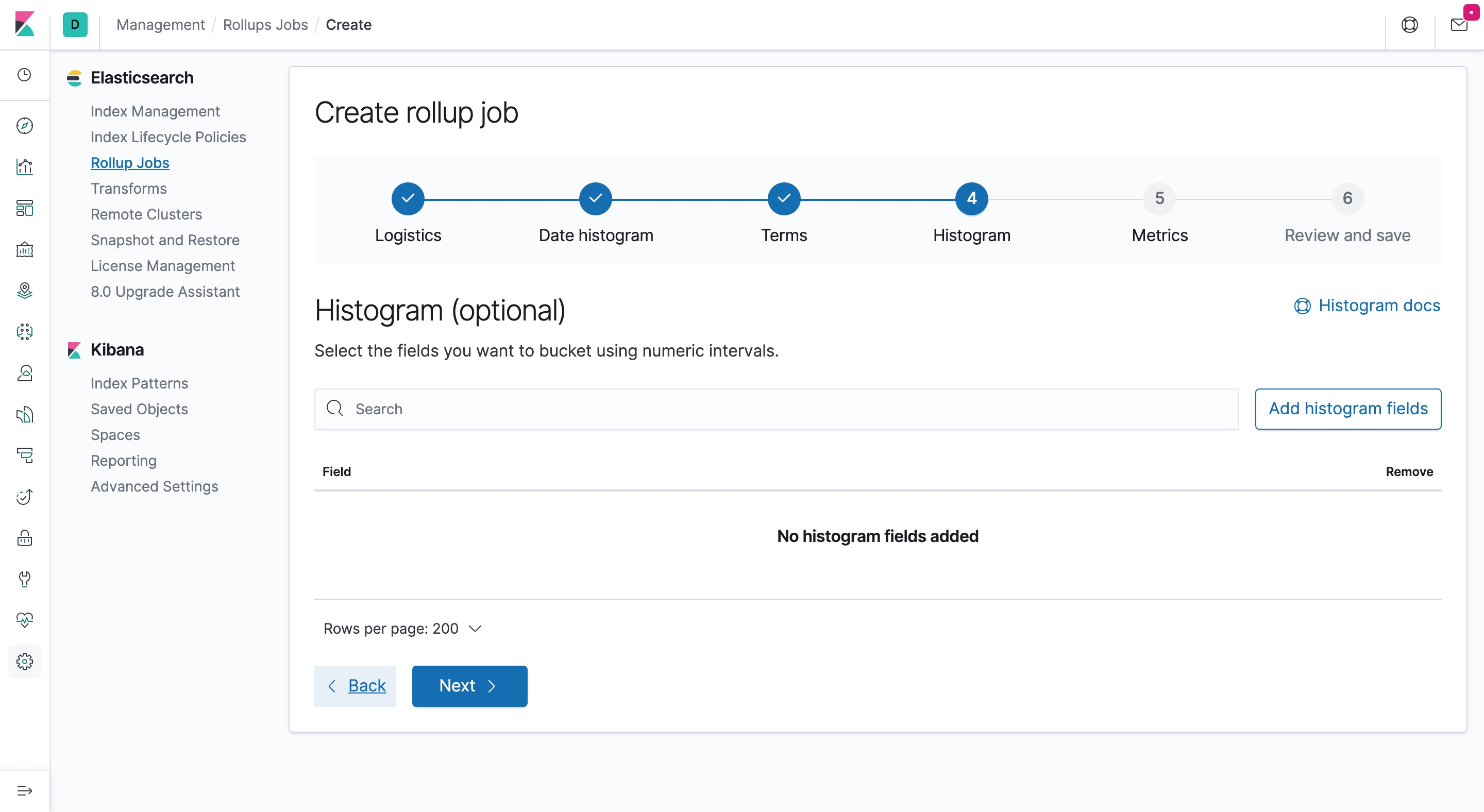
- 选择 Rollup 的时候,需要做预聚合计算的字段
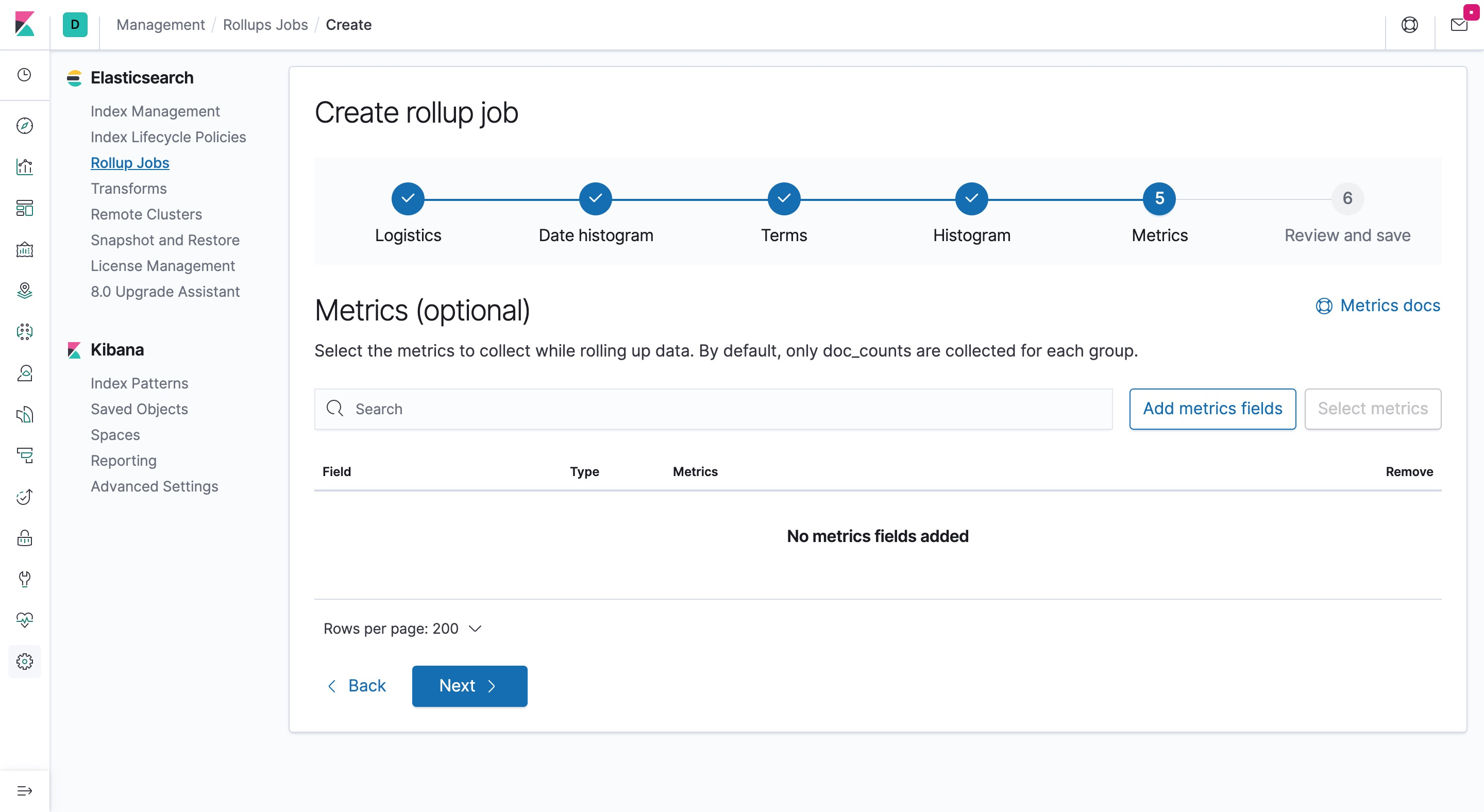
- 最终配置完成
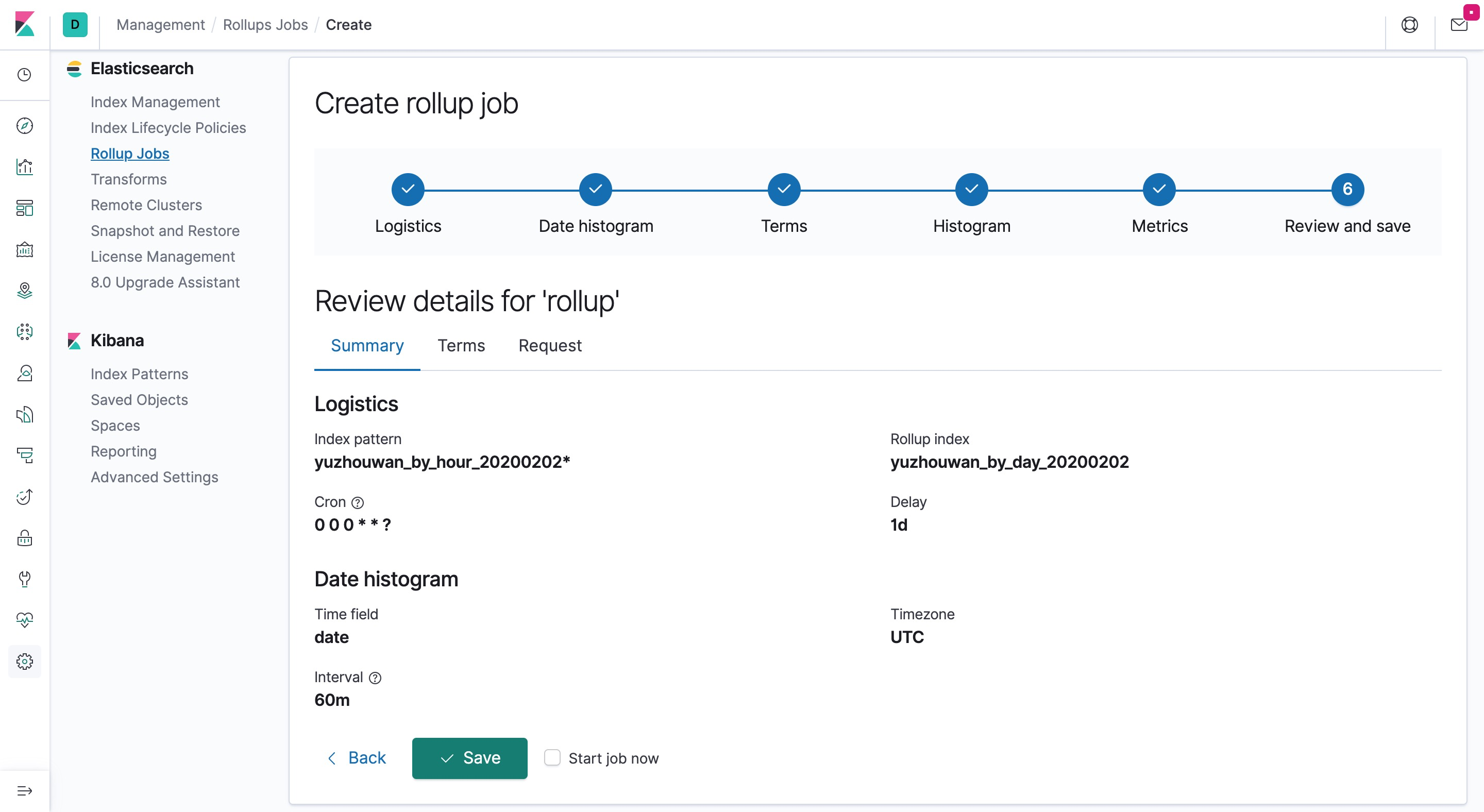
- 查看 Rollup 任务列表
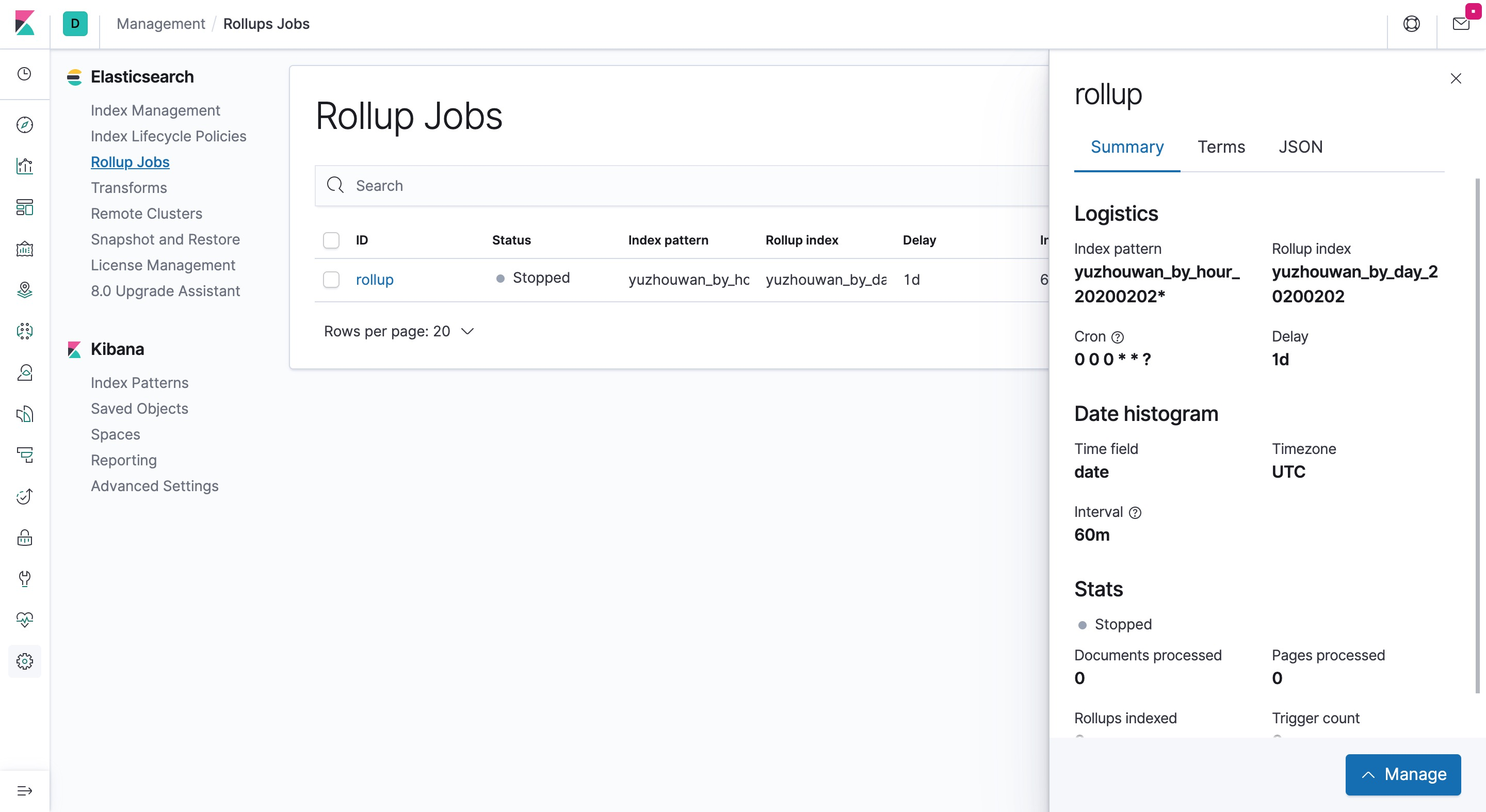
- 启停 Rollup 任务
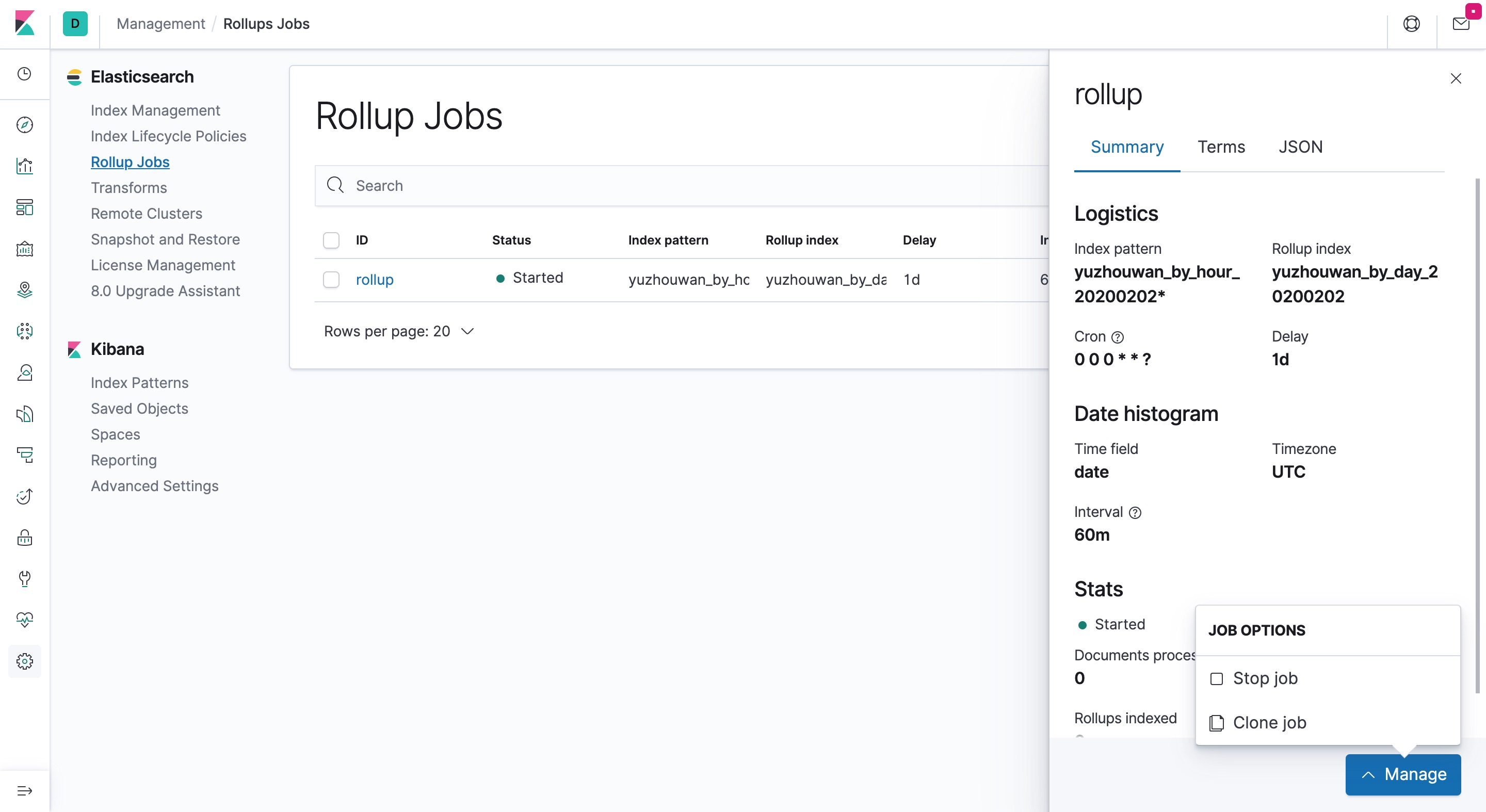
- 等价于通过命令行配置 Rollup 任务
1 | { |
局限性
截止到 Elasticsearch 7.9.1 版本,也只支持对 Date、Histogram 和 Terms 三种字段类型进行 Rollup 操作,且聚合算子也只有 max、min、sum、avg 和 count 五种
模板
创建模板
1 | $ vim template_yuzhouwan_day.json |
1 | { |
1 | $ curl -XPUT -H 'Content-Type: application/json' localhost:9200/_template/template_yuzhouwan_day -d @template_yuzhouwan_day.json |
获取模板
1 | $ curl -XGET localhost:9200/_template/template_yuzhouwan_day |
删除模板
1 | $ curl -XDELETE localhost:9200/_template/template_yuzhouwan_day |
插件
1 | $ bin/elasticsearch-plugin install analysis-icu |
集群状态
1 | $ curl -XGET 'http://localhost:9200/_nodes/stats/_all' |
熔断机制
Elasticsearch 熔断器在接收到请求后,会评估出可能耗费的内存大小,如果超过了单机所能处理的最大内存限制时,就会拒绝请求,并返回异常。熔断机制通过一个总控熔断器和多个子类熔断器(字段数据加载、聚合请求计算需要的内存、请求本身的大小、加载后未释放的 Lucene Segment,以及内联脚本编译次数),对内存消耗进行控制,避免了 OOM 问题。相关的配置均属于集群层面,所以我们可以通过修改 config/elasticsearch.yml 配置文件或者调用 PUT /_cluster/settings 接口中进行设置
基于磁盘容量的负载均衡
Elasticsearch 在决定是向某一个节点分配新的 Shard,还是主动从该节点重新分配 Shard 之前,会先考虑节点上的可用磁盘空间。该特性通过 cluster.routing.allocation.disk.threshold_enabled 参数进行控制,默认是开启的。相关行为主要通过三个阀值进行控制:当磁盘使用率达到 85% 的时候,就不再往该节点分配新的 Shard;当磁盘使用率达到 90% 的时候,将触发负载均衡,将 Shard 重定向到其他空闲节点上;而当磁盘使用率达到 95% 的时候,将会给所有的索引加上 read-only 的锁。此时,数据将无法写入,需要显示地将 index.blocks.read_only_allow_delete 参数设置为 false 才可以解除只读锁。具体的操作方法,详见下文 “踩过的坑 - blocked by: [FORBIDDEN/12/index read-only / allow delete (api)]”
整合其他框架
Elasticsearch + Kafka 整合
详见:我的另一篇博客《Apache Kafka 分布式消息队列框架》
Elasticsearch + Flume 整合
详见:Flume 官网文档
Elasticsearch + IK 中文分词
安装
详见:IK 官网文档
中文分词器比对表
| 分词器 | 分词粒度 | 出错情况 | 支持处理字符 | 新词识别 | 词性标注 | 认证方法 | 接口 |
|---|---|---|---|---|---|---|---|
| BosonNLP | 多选择 | 无 | 识别繁体字 | 有 | 有 | Token | RESTful |
| IKAnalyzer | 多选择 | 无 | 兼容韩文日文 | 有 | 无 | 无 | Jar |
| NLPIR | 多选择 | 中文间隔符 | 未知 | 有 | 有 | 无 | 多语言接口 |
| SCWS | 多选择 | 无 | 未知 | 有 | 有 | 无 | PHP、Cli |
| 结巴分词 | 多选择 | 无 | 识别繁体字 | 有 | 有 | 无 | Python |
| 盘古分词 | 多选择 | 无 | 识别繁体字 | 有 | 无 | 无 | 无 |
| 庖丁解牛 | 多选择 | 无 | 是 | 有 | 无 | 无 | Jar |
| 搜狗分词 | 小 | 字符长度过大 | 识别繁体字 | 未知 | 有 | 无 | 上传文档 |
| 腾讯文智 | 小 | 空白字符 | 未知 | 有 | 中文词性 | Signature | RESTful |
| 新浪云 | 大 | 无 | 未知 | 有 | 有 | 创建仓库 | RESTful |
| 语言云 | 适中 | 无 | 识别繁体字 | 有 | 有 | Token | RESTful |
技术内幕
Elasticsearch 和 Lucene 的本质是什么,为什么会选型 Elasticsearch?
本质
Lucene 是基于 Java 的全文检索库,而 Elasticsearch 是一款功能丰富的分布式搜索引擎
区别
Lucene
需要为分布式、高可用性和实时写入(索引建立 -> 可检索)等特性,进行额外的编码工作
Elasticsearch
具备分布式、实时分发、实时搜索、易用性(Multi-tenancy 多租户 / Gateway 备份)、高可用性(各节点组成对等的网络结构,方便故障转移)等特性
进一步思考
Solr、Lucene 作为全文检索系统,和 Elasticsearch 这种搜索引擎又有什么本质的区别?
搜索引擎,包含网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术 等等
全文检索,即文本全文检索,包括信息的存储、组织、表现、查询、存取等各个方面,其核心为文本信息的索引和检索
为什么 Elasticsearch 集群使用 Hash 路由,而不是 Paxos,这两个算法有什么区别,各自最适的应用场景在哪里?
Hash 路由,主要用于解决数据均衡分布的问题。而 Paxos 主要用于保证分布式数据副本的一致性
Elasticsearch 中的 Hash Router 会对每次请求的 _id 属性(即 Document ID,默认的 Elasticsearch 会自动为每一个 Document 分配一个长度为 20 的 UUID 字符串,也可以指定其他的字段)进行 Hash 操作,再对 Shard 数量进行取模
实际上,二者根本不是一个层面上的概念,更应该拿 Elasticsearch 的 Gossip + Bully 选举机制来和 Paxos 进行比较。下文会有对 Gossip + Bully 选主算法的详细说明,这里就多介绍了
(更多相关内容详见,我的另外两篇博客《大数据生态圈的一致性算法》和《ZooKeeper 原理与优化》)
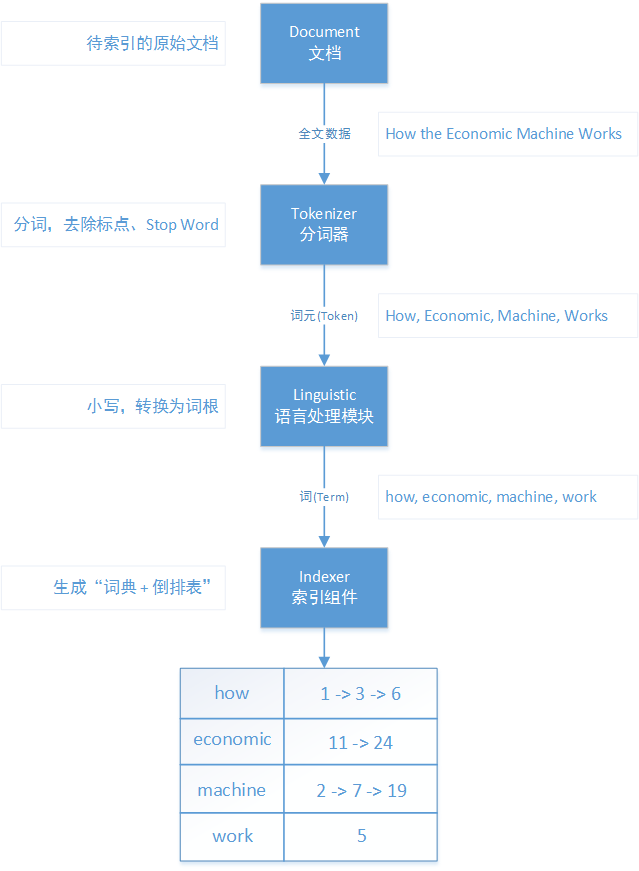
Elasticsearch 倒排索引的原理
图解
已经有太多的书和博客来介绍,这里就不班门弄斧了,就简单画个图来帮助理解“倒排索引”的流程吧
Lucene 4 实现的 DocValues 特性,为什么可以加速聚合运算?
DocValues 是什么?
Lucene 在构建倒排索引时,额外建立的一个有序的、基于 Document -> Field Value 的映射列表
场景
- 对字段进行排序或聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
用法
可以通过 doc_values 字段控制 DocValues 特性是否开启。默认地,会对除了 analyzed strings 之外的所有字段启用(即数字、地理坐标、日期、IP 和 not_analyzed 字符类型)
1 | PUT yuzhouwan_index |
1 | { |
原理
倒排索引建立的是 KeyWord -> Document 的映射关系,以便在文本检索时,通过类似 Hash 算法,来快速定位到 KeyWord,再从索引中获取到包含该 KeyWord 的 Document ID 集合。虽然,该方法保证了高效的检索,但在对数据做聚合运算时,却需要将所有出现了 KeyWord 的 Document 加载到内存中,很容易导致进程的内存溢出问题
针对该问题,DocValues 便应运而生了。其会对开启了该特性的字段,额外构建一个 Document -> Field Value 的正排索引。此时,聚合操作的流程就变成了,先找到 KeyWord 的 Document,再从 DocValues 中加载 Document 对应的 Filed Value 到内存中进行运算即可。同时,如果 Field Value 占用的内存远小于节点的可用内存,则会自动常驻在内存中,进而保证了性能;反之,则会序列化到磁盘中,避免出现 OOM 问题。另外,因为其列式存储的特性,使得压缩效率也很高
进一步思考
设置 stored=”true” 属性同样会构建正排索引,它和 DocValues 又有何不同?
主要区别在于,前者是行式存储,而后者是列式存储;且前者直接存储字段原始值,而后者会进行分词
Elasticsearch 5.0 内核迁移为 Lucene 6.x,是如何利用 Block K-d Tree 来解决 深度分页 问题?
Elasticsearch 2.x 现状
使用 form + size 或者 scroll 的方式效率很低
算法简介
K-d Tree,利用 方差 + 中位数 分割数据入 二叉树,再利用 二叉查找 + 递归溯源 的方式来查找数据。而 Block K-d Tree 则是一组 K-d Tree,解决了多维空间数据搜索,较高的空间利用率,高性能的查询和更新。使得 Elasticsearch 处理数值型数据和高维数据的性能提高了约 30%,同时存储空间大小节约了约 60%
缺点
在搜索过程中,N 个节点、K 维 的 K-d Tree 最坏的时间复杂度为:$T_{worst} = O(K*N^{1-\frac{1}{K}})$,所以其无法很好地处理高维数据;
而 Block K-d Tree 虽然在插入性能方面比 K-d Tree 提升了几个数量级,但是如果系统使用的是非 SSD 硬盘,则可能会出现严重的毛刺现象
源码阅读
环境搭建
1 | # Lucene |
Lucene
基本概念
索引(Index)
在 Lucene 中一个索引是放在一个文件夹中的,同一文件夹中的所有的文件构成一个 Lucene 索引
段(Segment)
一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以进行合并。从文件名来看,_0、_1 或者 _N 开头的一组文件用于表示属于某一个段,segments.gen 和 segments_N 文件则保存了 Segment 相关的元数据信息
文档(Document)
文档是创建索引的基本单位,不同的文档会保存在不同的段中,即一个段可以包含多个文档。新写入的文档会单独保存在一个新生成的段中,在随后的段合并操作中,不同的文档才合并到同一个 Segment 中
域(Field)
一个文档包含不同类型的信息,分别存在不同的域中,也就是文档的字段
词典(Term Directory)
字段内容经过分词、归一化、还原词根等处理之后,得到的所有单词的集合
词(Term)
词是索引的最小单位,本质上是词法分析和语言处理后的一个字符串
实践
下载 Lucene
1 | $ wget http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/8.6.2/lucene-8.6.2.tgz |
构造需要被索引的数据
1 | $ vim blog.txt |
创建索引文件
1 | $ java -classpath 'demo/lucene-demo-8.6.2.jar:core/lucene-core-8.6.2.jar' org.apache.lucene.demo.IndexFiles -docs blog.txt |
检索文件
1 | $ java -classpath 'demo/lucene-demo-8.6.2.jar:core/lucene-core-8.6.2.jar:queryparser/lucene-queryparser-8.6.2.jar' org.apache.lucene.demo.SearchFiles |
目录结构
1 | $ tree -L 2 index |
编程
1 | // index |
Tips: Full code is here.
文件格式
概览
| 名称 | 文件后缀 | 简要描述 |
|---|---|---|
Segments File |
segments_N | Stores information about a commit point |
Lock File |
write.lock | The Write lock prevents multiple IndexWriters from writing to the same file. |
Segment Info |
.si | Stores metadata about a segment |
Compound File |
.cfs、.cfe | An optional “virtual” file consisting of all the other index files for systems that frequently run out of file handles. |
Fields |
.fnm | Stores information about the fields |
Field Index |
.fdx | Contains pointers to field data |
Field Data |
.fdt | The stored fields for documents |
Term Dictionary |
.tim | The term dictionary, stores term info |
Term Index |
.tip | The index into the Term Dictionary |
Frequencies |
.doc | Contains the list of docs which contain each term along with frequency |
Positions |
.pos | Stores position information about where a term occurs in the index |
Payloads |
.pay | Stores additional per-position metadata information such as character offsets and user payloads |
Norms |
.nvd、.nvm | Encodes length and boost factors for docs and fields |
Per-Document Values |
.dvd、.dvm | Encodes additional scoring factors or other per-document information. |
Term Vector Index |
.tvx | Stores offset into the document data file |
Term Vector Data |
.tvd | Contains term vector data. |
Live Documents |
.liv | Info about what documents are live |
Point values |
.dii、.dim | Holds indexed points, if any |
正排索引
segments_N保存了此 Index 包含多少个 Segment,每个 Segment 包含多少 Document.fnm保存了此 Segment 包含了多少个 Field,每个 Field 的名称及索引方式.fdx和.fdt保存了此 Segment 包含的所有 Document,各个 Document 包含了哪些 Field,以及每个 Field 保存了哪些信息.tvx和.tvd保存了此 Segment 包含多少 Document,各个 Document 包含了多少 Field,每个 Field 包含了多少 Term,每个 Term 字符串的位置信息等
倒排索引
.tim保存了 Term Directory,并以字典序保存 Term,方便进行高效的二分查找( $O(\log_2^n)$).tip保存了 Term 到 Term Directory 的倒排索引。这里使用的数据结构是 FST(Finite State Transducers,有限状态传感器),构建了一个 Term 的前缀树,不仅压缩了存储空间,还提高了查询速度( $O(len(str))$)![Term to Term Directory Inverted Index]()
(图片来源:easynosql.com™,该网站已故障,侵删谢谢) .doc保存了倒排表(即每个 Term 到 Document ID 的列表),同时也保存了 Document 中 Term 出现的频率
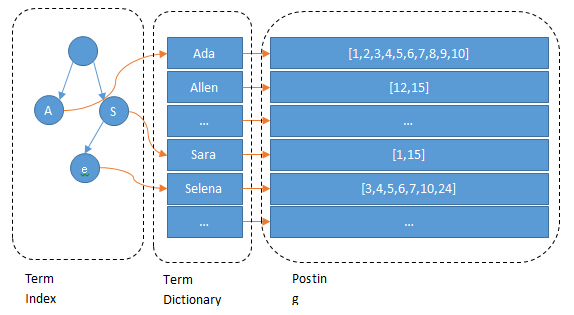
全文检索
.pos保存了倒排表中每个 Term,以及在 Document 中的位置.nvd和.nvm保存 Field 得分信息
列式存储
.dvd和.dvm保存 DocValues 信息,用以加速聚合排序等查询
Document 模块
功能
定义 Document 和各种相关的数据类型
主体
org.apache.lucene.document.Document
由 Field 组成的文档记录的
org.apache.lucene.document.Field
Document 中的一个字段
Codecs 模块
功能
基础数据结构和编码压缩算法的实现,包括 skipList,docValue 等
Analysis 模块
功能
词法分析,并输出索引的最小单位 Term
主体
org.apache.lucene.analysis.Analyzer
分析器会对内容进行过滤,分词,转换等,把过滤之后的数据交给 IndexWriter 进行索引
Index 模块
功能
创建索引
主体
org.apache.lucene.index.IndexWriter
索引写操作的核心类
addDocument
将 Document 添加到索引中
updateDocument
更新 Document,等同于 delete by term + add document 两个操作的组合,并确保了其原子性
deleteDocument
删除 Document,支持 delete by term 和 delete by query
prepareCommit
二阶段提交的第一步
commit
二阶段提交的第二步,成功之后会生成一个 segment_N 文件新的 N 值,也只有 commit 成功之后,数据才可以被检索到
rollback
prepareCommit 或者 commit 任何一个操作失败之后,都会回滚到提交前的状态
maybeMerge
触发一次 MergePolicy 的执行,不满足条件的情况下,并不会执行 merge 操作
forceMerge
强制触发一次 merge 操作
org.apache.lucene.index.SegmentInfos
getLastCommitGeneration(org.apache.lucene.store.Directory)
获取索引目录下最近一次的 commit 号,以定位最大的 segment_N 文件
org.apache.lucene.index.Term
Term 是文本检索的基本单元,一个 Term 由 KeyValue 组成,Key 为需要检索的字段名称,Value 为字段的值
配置
wait_for_active_shards
集群中至少有多少存活的 Shard 才执行写入操作,可以设置为
all表示需要主 Shard 和所有的副 Shard 均存活才执行写操作,默认值:1(即只需要主 Shard 存活即可写入)
Store 模块
功能
读写索引
主体
org.apache.lucene.store.Directory
IndexWriter 通过获取 Directory 的一个具体实现,在 Directory 指向的位置中操作索引
FSDirectory
表示一个存储在文件系统中的索引的位置
ByteBuffersDirectory
表示一个存储在内存当中的索引的位置
Parser 模块
功能
查询的语法分析
Search 模块
功能
搜索索引
主体
org.apache.lucene.search.IndexSearcher
以只读的方式打开一个索引,并进行检索
search
从索引中检索 Document
org.apache.lucene.search.Query
封装查询请求
TermQuery
最基本的 Term 查询
BooleanQuery
可以组合多个查询条件
PointRangeQuery
数值区间查询,可以通过
IntPoint#newRangeQuery、LongPoint#newRangeQuery、FloatPoint#newRangeQuery和DoublePoint#newRangeQuery等方式进行创建PrefixQuery
前缀查询
FuzzyQuery
模糊查询
WildcardQuery
通配符查询
RegexpQuery
正则表达式查询
MultiFieldQueryParser
多值查询
TopDocs
TopN 查询
Similarity 模块
功能
相关度打分
Geo 模块
功能
空间查询
Elasticsearch
Transport 模块
功能
保障了集群内各节点之间可以进行网络通讯
主体
org.elasticsearch.cli.Command#main
org.elasticsearch.cli.EnvironmentAwareCommand#execute
org.elasticsearch.bootstrap.Elasticsearch#execute
org.elasticsearch.bootstrap.Bootstrap
org.elasticsearch.node.Node
org.elasticsearch.transport.TransportService
connectToNode
连接集群中的其他 Node 节点
sendRequest
发送请求
registerRequestHandler
注册 TransportRequestHandler,用于处理接收到的请求
org.elasticsearch.transport.Transport
org.elasticsearch.transport.netty4.Netty4Transport(transport-netty4 模块)
org.elasticsearch.transport.netty4.Netty4MessageChannelHandler
配置
transport.port
Transport 服务绑定的端口范围,默认值为
9300-9400transport.type
控制 Transport 通讯时的网络类型,默认值为
netty4transport.compress
控制是否针对 Request 请求和 Response 返回结果进行压缩,默认值为
false
流程
Command 完成 Elasticsearch 进程的启动,随后依次初始化 Bootstrap、Node、Transport 和 TransportService 并启动。节点间通讯的消息处理,最终由 Netty4MessageChannelHandler 进行处理。该 Handler 的注册操作,则会在 Netty4Transport 中完成
Zen Discovery 模块
功能
可以让 Elasticsearch 节点自动互相发现,并组成一个集群,且能通过选举机制找到一个 Master 节点
配置
node.master
如果设置为 true,则可以参与到 Master 选举过程中,默认值为
truenode.data
如果设置为 true,则可以存储数据,并处理与数据相关的 CRUD、查询和聚合等操作,默认值为
true排列组合
node.master和node.data这两个参数的结果,如下表所示:
| data: true | data: false | |
|---|---|---|
| master: true | 既是种子节点,又是数据节点 | 单纯的种子节点 |
| master: false | 单纯的数据节点 | 最简单的协调节点 |
node.ingest
如果设置为 true,则可以创建一个 ingest pipeline 任务,对未被索引到 Index 之前的 Document 数据进行预处理,例如设置某一些字段值或者增加一个新字段(如记录摄入时间的新字段)。考虑到可能会增加机器的负载,生产环境中,最好将 Master 节点和 Node 节点上的这个功能关闭,默认值为
truexpack.ml.enabled
如果设置为 true,则可以处理 Elasticsearch 机器学习的接口请求,默认值为
truenode.ml
如果设置为 true,则可以运行机器学习相关的任务,默认值为
truediscovery.seed_hosts
提供一组可以成为 Master 的种子节点的 IP 地址,如果未指定端口号,将会自动使用
transport.port的配置值(默认 9300)discovery.seed_providers
另一种提供种子节点 IP 地址的方式,指定一个存放 IP 地址的文件,可以动态加载,避免集群扩缩容时需要重启 Elasticsearch 进程的问题
discovery.find_peers_interval
Discovery 机制的周期频率,默认值为
1s
流程
Elasticsearch 将集群内的节点分为了四种类型,分别是 Master-eligible node、Data node、Ingest node 和 Machine learning node。Master 选举只会在 Master-eligible 种子节点之间进行,触发条件为:
- 当前 Master-eligible 节点不是 Master 节点
- 当前 Master-eligible 节点与其它的节点通信后发现不存在 Master
- 寻找 clusterStateVersion 比自己高的 Master-eligible 的节点,向其发送选票
- 如果 clusterStatrVersion 一样,则计算自己能找到的 Master-eligible 节点中(包括自己)ID 最小的一个节点,向该节点发送选票
- 如果一个节点收到过半的选票,并且它也向自己投票了,那么该节点成为 Master 节点
成功从 Master-eligible 节点中选举出 Master 节点之后,那么这个 Master 节点将会负责集群(集群信息、集群健康、集群状态、集群配置、所有分片、节点关闭、集群路由)和索引(索引的创建与删除、索引 Template 和 Mapping 的创建删除与更新、索引 Warmer 创建删除与获取、索引的打开与关闭)相关的所有请求
其他
Bully
Bully 算法会假定所有节点都有一个惟一的 ID,并可以依据 ID 对集群内节点进行排序,而拥有最高 ID 的那个节点则会成为 Master 节点
Gossip
Gossip 本质上就是一个并行的图广度优先遍历搜索算法,可以借助一个动图来直观感受一下:
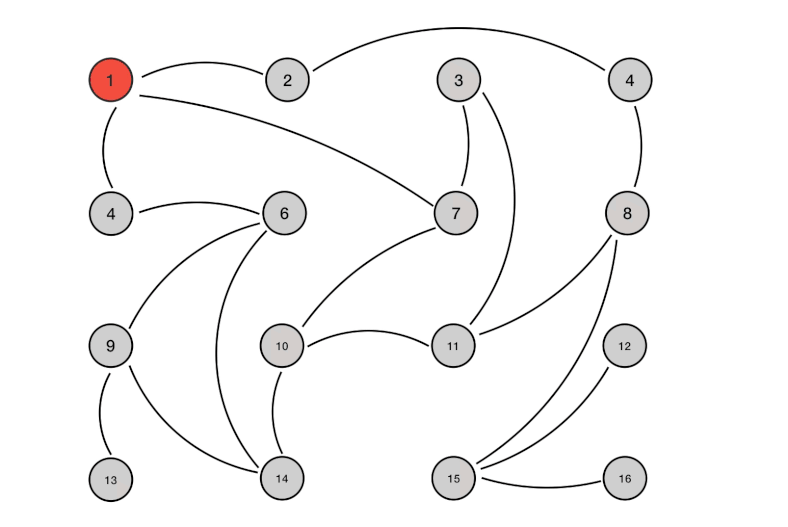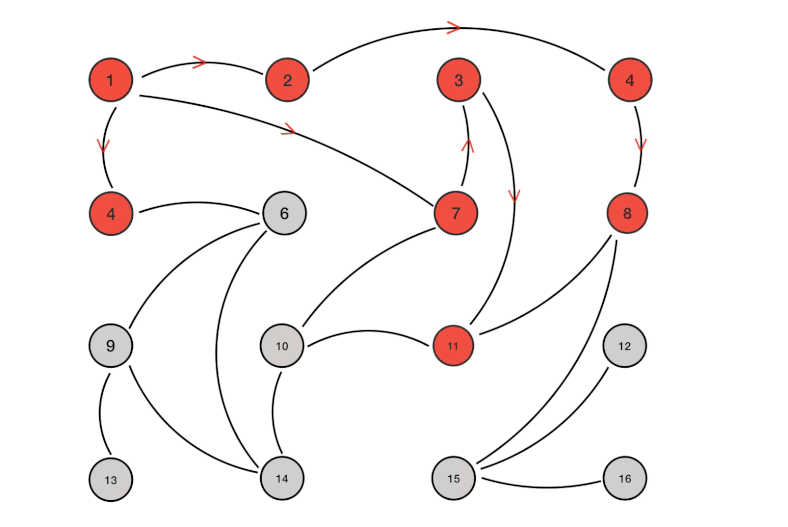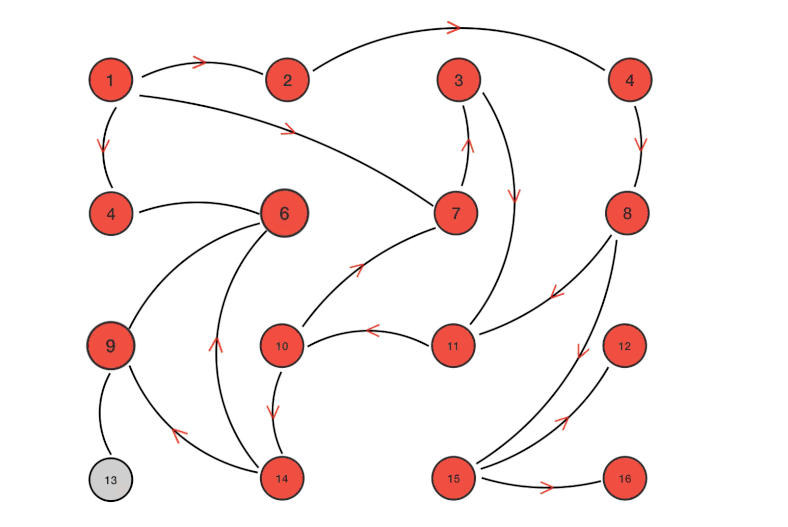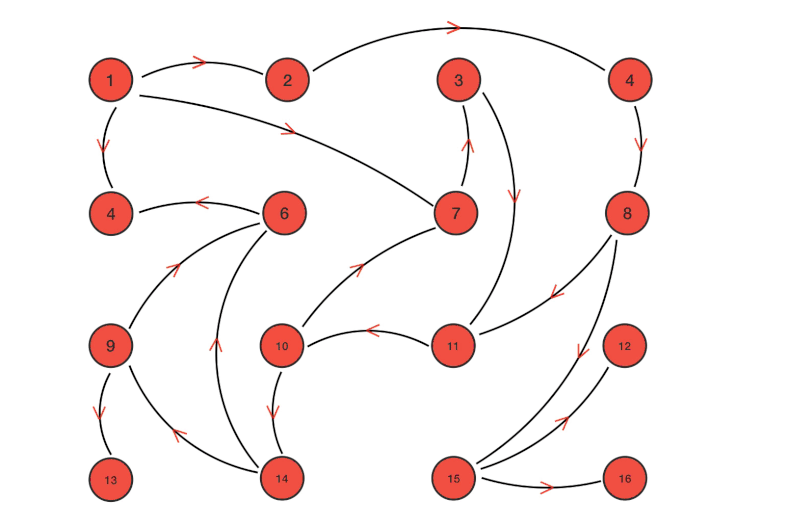
单播 vs 组播 vs 广播
| 网络模型 | 优点 | 缺点 | |
|---|---|---|---|
| 单播(unicast) |  |
点对点通讯可以保证低响应延迟 | 服务端流量消耗较大 |
| 组播(multicast) |  |
共享数据流可以减少带宽负载 | 无纠错机制,发生丢包或错包之后,很难弥补 |
| 广播(broadcast) |  |
网络设备简单可以减少布网和维护的成本 | 无法提供定制化服务,且客户端的网络带宽将成为瓶颈 |
数据写入
流程
因为 Elasticsearch 内所有节点都默认属于 Coordinating 节点,这意味着每个节点都有能力处理任何一种请求
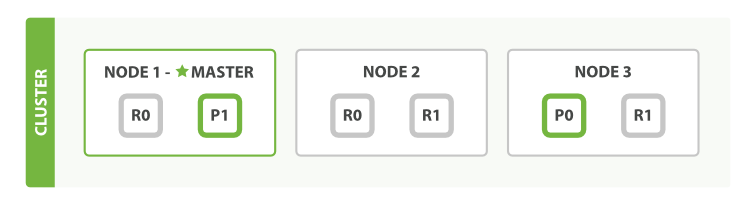
这里我们以单 Index、两 Shard、三 Replication、三 Node 的 Elasticsearch 集群为例
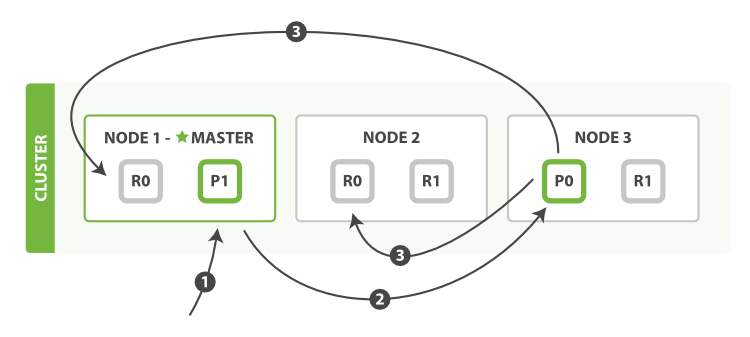
- 客户端向
NODE 1发送新建、索引或者删除请求 - 节点使用 Document 的
_id确定 Document 属于 Shard 0。请求会被转发到NODE 3,因为分片 0 的主分片目前被分配在NODE 3上 NODE 3在主分片上面执行请求。如果成功了,它将请求并行转发到NODE 1和NODE 2的副本分片上。一旦所有的副本分片都成功返回,Node 3将向协调节点报告成功,随后协调节点再向客户端反馈请求成功
而内部持久化到磁盘的流程和 HBase 很像,所以还可以借鉴 HBase 的概念进行理解:
| HBase | Elasticsearch |
|---|---|
| MemStore | IndexBuffer |
| HFile | Segment |
| WAL | Translog |
| Compaction | Merge |
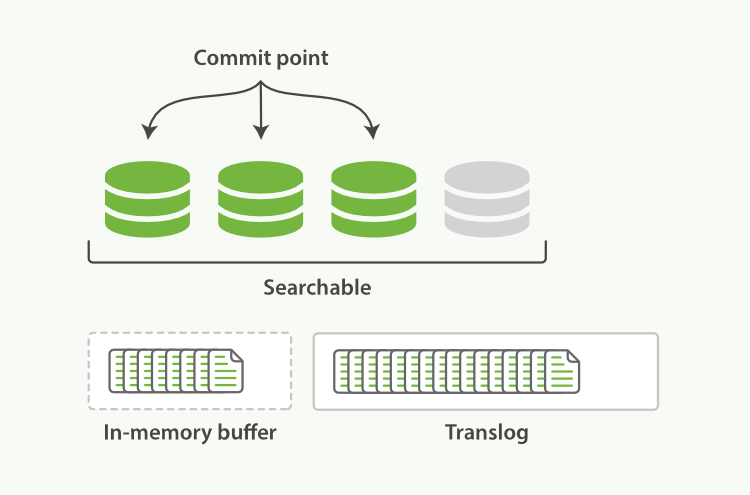
写入的数据都会先存放在 Buffer 中,以保证写入的效率。之后,每隔一段时间(默认 5s,最小 100ms),Elasticsearch 会批量将 Buffer 中的数据,Sync 到磁盘上的 Segment 中。此时,Segment 处于打开状态,可以被查询检索到。而为了确保数据不会丢失,Elasticsearch 会将每一个事务操作都记录到 Translog 中。每次 Sync 操作只会清空 Buffer 中的数据,并不会清空 Translog 中的事务日志。只有写入一段时间后,进行全量 Sync 操作的时候,才会将 Translog 清空(默认是 Translog 达到 512M 或者 12 小时之后)
数据查询
流程
和数据写入不同的是,数据查询是可以在主分片或者其任意副本分片上,完成文档检索的。同时,为了保证负载均衡,每次请求的时候,还会轮询地去查询副本分片
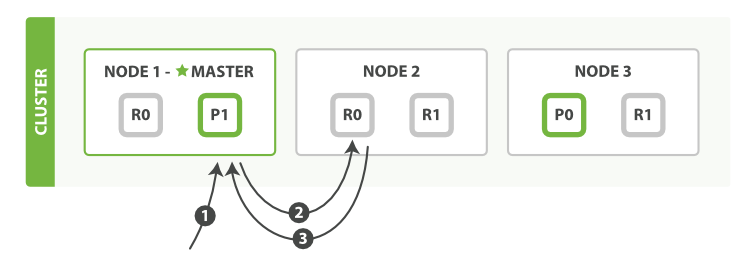
这里我们仍然以单 Index、两 Shard、三 Replication、三 Node 的 Elasticsearch 集群为例
- 客户端向
NODE 1发送查询请求 - 节点使用 Document 的
_id来确定 Document 属于 Shard0。而所有节点上都存在着 Shard0的副本分片。这种情况下,它将请求转发到NODE 2 NODE 2将文档返回给NODE 1,然后将文档返回给客户端
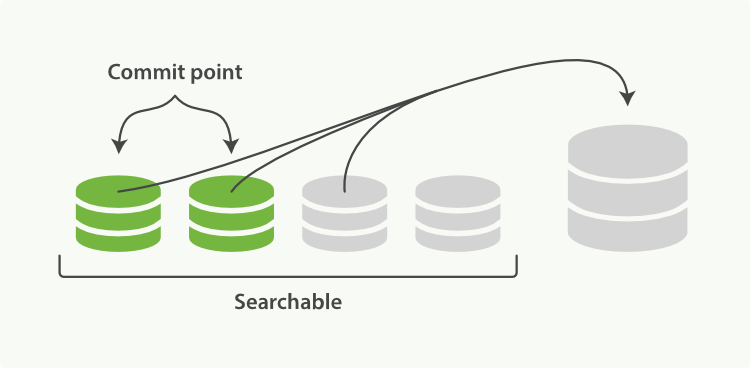
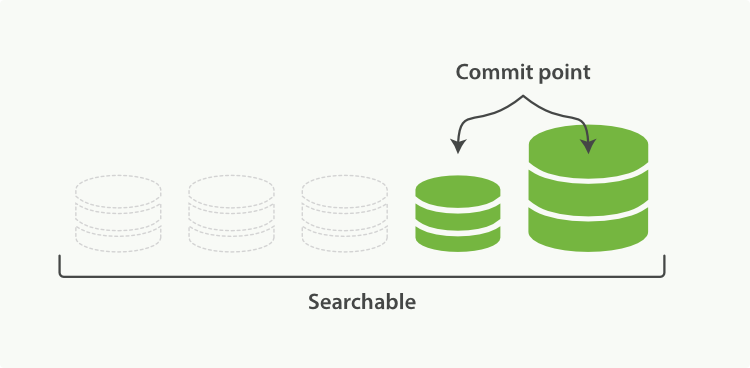
段合并
流程
为了避免 Segment 小文件过多,Elasticsearch 会定时进行 Segment 合并操作。因为段合并需要消耗大量的磁盘 IO 和 CPU,所以为了不影响正常的集群运行,Elasticsearch 会进行严格的限流,默认 20MB/s
熔断器
功能
熔断器(Circuit Breaker)用于防止 OOM 异常,以增强集群稳定性。更多介绍,详见上文 “使用技巧 - 熔断机制” 小节
配置
Parent Circuit Breaker
indices.breaker.total.use_real_memory
是否通过
ManagementFactory.getMemoryMXBean().getHeapMemoryUsage().getUsed()的方式获取更加精准的内存使用指标,默认值为trueindices.breaker.total.limit
父熔断器限制内存使用的比例,默认值为
70%(上一个参数use_real_memory为false) 或95%(反之为true)
Field Data Circuit Breaker
indices.breaker.fielddata.limit
字段数据熔断器,限制内存中加载的 Field 只能占到总内存的比例,默认值为
40%indices.breaker.fielddata.overhead
用来和字段数据估计值相乘的常数,默认值为
1.03
Request Circuit Breaker
indices.breaker.request.limit
请求熔断器,主要限制的是请求在执行过程中的可能会消耗的内存(例如,用于在请求期间计算聚合的内存),默认值为
60%indices.breaker.request.overhead
用来和请求内存消耗的估计值相乘的常数,默认值为
1
In Flight Requests Circuit Breaker
network.breaker.inflight_requests.limit
飞行中请求熔断器,则是作用于尚未开始执行的请求,主要限制的是,请求本身的内容长度,会在 HTTP 层面上对所有当前活跃的传入请求的内存大小进行限制,默认值为
100%(这意味着可能会在父熔断器允许的范围内将内存耗尽)network.breaker.inflight_requests.overhead
用来和飞行中请求内存消耗的估计值相乘的常数,默认值为
2
Accounting Requests Circuit Breaker
indices.breaker.accounting.limit
计费熔断器,限制的是请求完成时,未被释放的内容的内存大小(例如,Lucene 段内存等),默认值为
100%(这意味着可能会在父熔断器允许的范围内将内存耗尽)indices.breaker.accounting.overhead
用来和计费熔断器的估计值相乘的常数,默认值为
1
Script Compilation Circuit Breaker
script.max_compilations_rate
脚本编译熔断器,限制的是一段时间内的内联脚本编译次数,默认值为
75/5m
主体
org.elasticsearch.common.breaker.CircuitBreaker
最上层的接口,定义了除脚本编译熔断器(ScriptService)之外的所有内置的 Breaker:
PARENTFIELDDATAREQUESTIN_FLIGHT_REQUESTSACCOUNTING
和相应的类型:
MEMORY子熔断器
PARENT父熔断器
NOOP不会触发任何熔断行为的熔断器
以及 Breaker 相关的行为:
addEstimateBytesAndMaybeBreakaddWithoutBreakinggetUsedgetLimitgetOverheadgetTrippedCountgetNamegetDurability
org.elasticsearch.common.breaker.ChildMemoryCircuitBreaker
org.elasticsearch.indices.breaker.HierarchyCircuitBreakerService
#breakers记录所有的 Breaker,即
<熔断器名称,CircuitBreaker 实例>checkParentLimit检查父熔断器是否已跳闸
registerBreaker注册熔断器(支持注册自定义的熔断器,如果自定义的熔断器名称和已存在的熔断器的名称相同,将会覆盖掉已存在的熔断器)
org.elasticsearch.indices.breaker.BreakerSettings
#name熔断器的名称
#limitBytes阀值
#overhead计算内存消耗时的因子
#type熔断器的类型
Rollup
主体
- org.elasticsearch.xpack.rollup.Rollup
- org.elasticsearch.xpack.rollup.job.RollupJobTask
- org.elasticsearch.xpack.rollup.job.RollupJobTask.RollupJobPersistentTasksExecutor
时序图
sequenceDiagram participant User participant TransportPutRollupJobAction participant RollupJob participant PersistentTasksService participant ElasticsearchClient participant AbstractClient participant OriginSettingClient participant ActionListener User ->>+ TransportPutRollupJobAction : masterOperation TransportPutRollupJobAction ->> TransportPutRollupJobAction : createRollupJob TransportPutRollupJobAction ->>+ RollupJob : << new >> RollupJob -->>- TransportPutRollupJobAction : Instance TransportPutRollupJobAction ->> TransportPutRollupJobAction : createIndex TransportPutRollupJobAction ->>+ TransportPutRollupJobAction : startPersistentTask TransportPutRollupJobAction ->> PersistentTasksService : sendStartRequest PersistentTasksService ->>+ PersistentTasksService : execute PersistentTasksService ->>+ ElasticsearchClient : execute ElasticsearchClient ->>+ AbstractClient : doExecute AbstractClient ->>+ OriginSettingClient : doExecute OriginSettingClient -->>- AbstractClient : done AbstractClient -->>- ElasticsearchClient : done ElasticsearchClient -->>- PersistentTasksService : done PersistentTasksService ->> PersistentTasksService : waitForPersistentTaskCondition PersistentTasksService ->>+ ActionListener : onResponse | onFailure | onTimeout ActionListener -->>- PersistentTasksService : done PersistentTasksService -->>- TransportPutRollupJobAction : done TransportPutRollupJobAction -->>- User : done
踩过的坑
Unknown Analyzer type [org.Elasticsearch.index.analysis.IkAnalyzerProvider] for [ik]
属于配置的问题,需注意 Elasticsearch 和 IK 中文分词插件的版本,不同的版本中支持的配置项也会不一样
The number of object passed must be even but was [1]
1 | // 建议不使用 JSON.toJSONString,而是自己在 POJO 中拼装 Map<String, Object> |
blocked by: [FORBIDDEN/12/index read-only / allow delete (api)]
1 | PUT _settings |
1 | { |
Docker 中无法开启 bootstrap.memory_lock 参数
非容器环境下,在 limits.conf 文件中增加 memlock 相关的配置即可(这里了的 admin 是 Elasticsearch 运行的用户,可以根据实际情况更换)
1 | $ su - |
容器环境下,则需要用如下方式进行修改:
1 | $ grep locked /proc/$(ps --no-headers -o pid -C dockerd | tr -d ' ')/limits |
资料
Doc
Lucene
Elasticsearch
| 主分类 | 子分类 | 字段类型 |
|---|---|---|
| 核心类型 | 字符串类型 | text / keyword |
| 整数类型 | long /integer / short / byte | |
| 浮点类型 | double / float / half_float / scaled_float | |
| 逻辑类型 | boolean | |
| 日期类型 | date | |
| 范围类型 | integer_range / float_range / long_range / double_range / date_range | |
| 二进制类型 | binary | |
| 复合类型 | 对象类型 | object |
| 嵌套类型 | nested | |
| 数组类型 | 不存在数组类型,所有的字段都有存储多个相同类型的字段值 | |
| 地理类型 | 地理坐标类型 | geo_point |
| 地理地图 | geo_shape | |
| 特殊类型 | IP 类型 | ip |
| 范围类型 | completion | |
| 令牌计数类型 | token_count | |
| 存储索引的 Hash 值类型 | murmur3 | |
| 抽取类型 | percolator |
- Elasticsearch: doc_values
- Rollup APIs
- Rollup aggregation limitations
- Rolling up historical data
- Tune for indexing speed
Github
- Lucene
- Open Distro for Elasticsearch Security
- Formal models of core Elasticsearch algorithms
- Fix G1 GC default IHOP
Paper
Book
- Mastering Elasticsearch
- Monitoring Elasticsearch
- Elasticsearch Cookbook, 2nd Edition
- Elasticsearch in Action
- Elasticsearch Indexing
- Elasticsearch Server, 2nd Edition
- Elasticsearch:The Definitive Guide
Tool
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| BigData | |
| 算法 |