环境搭建 基础环境 用户 1 2 3 4 5 6 7 8 9 10 11 12 13 $ adduser redis $ passwd redis $ chmod u+w /etc/sudoers $ vim /etc/sudoers redis ALL=(ALL) ALL $ chmod u-w /etc/sudoers $ su - redis
目录 1 2 3 4 $ cd /home/redis $ mkdir install && mkdir software && mkdir logs && mkdir data
分布式集群 下载 1 2 $ cd ~/install $ wget http://download.redis.io/releases/redis-3.2.9.tar.gz
解压分发 1 2 3 4 5 $ tar zxvf redis-3.2.9.tar.gz -C ~/software $ cd ~/software/ $ scp -r redis-3.2.9/ redis@yuzhouwan02:/home/redis/software/ $ scp -r redis-3.2.9/ redis@yuzhouwan03:/home/redis/software/ $ ln -s redis-3.2.9/ redis
安装 1 2 3 4 5 6 7 8 9 10 $ cd ~/software/redis $ make -j8 Hint: It's a good idea to run ' make test ' ;) make[1]: Leaving directory `/home/redis/software/redis-3.2.9/src' $ vim ~/.bash_profile REDIS_HOME=~/software/redis PATH=$PATH :$HOME /bin:$REDIS_HOME /src $ source ~/.bash_profile
配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ mv redis.conf redis.conf.bak $ vim redis.conf bind 0.0.0.0 port 6379 pidfile /home/redis/software/redis/redis.pid logfile "/home/redis/logs/redis.log" dir /home/redis/data cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes $ scp -r ~/software/redis/redis.conf redis@yuzhouwan02:/home/redis/software/redis/ $ scp -r ~/software/redis/redis.conf redis@yuzhouwan03:/home/redis/software/redis/
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 $ nohup redis-server redis.conf 1>/dev/null 2>&1 & $ ps -ef | grep redis redis 12781 9204 0 10:15 pts/0 00:00:00 redis-server 127.0.0.1:6379 [cluster] $ redis-cli -c -p 6379 127.0.0.1:6379> cluster info cluster_state:fail cluster_slots_assigned:0 cluster_slots_ok:0 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:1 cluster_size:0 cluster_current_epoch:0 cluster_my_epoch:0 cluster_stats_messages_sent:0 cluster_stats_messages_received:0 $ cd ~/software && mkdir redis2 && cp redis/redis.conf redis2/ $ mkdir /home/redis/data2 $ vim redis2/redis.conf bind 0.0.0.0 port 6380 pidfile /home/redis/software/redis2/redis.pid logfile "/home/redis/logs/redis2.log" dir /home/redis/data2 cluster-enabled yes cluster-config-file nodes2.conf cluster-node-timeout 5000 appendonly yes $ scp -r ~/software/redis2/redis.conf redis@yuzhouwan02:/home/redis/software/redis2/ $ scp -r ~/software/redis2/redis.conf redis@yuzhouwan03:/home/redis/software/redis2/ $ nohup redis-server redis2/redis.conf 1>/dev/null 2>&1 &
集群配置 安装 Ruby 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ apt-get install ruby $ sudo yum install ruby $ cd ~/install $ wget https://cache.ruby-lang.org/pub/ruby/2.4/ruby-2.4.1.tar.gz $ tar zxvf ruby-2.4.1.tar.gz -C ~/software $ cd ~/software/ruby-2.4.1 && mkdir ../ruby $ ./configure prefix=/home/redis/software/ruby $ make -j8 && make -j8 install $ vim ~/.bash_profile REDIS_HOME=~/software/redis RUBY_HOME=~/software/ruby PATH=$PATH :$HOME /bin:$REDIS_HOME /src:$RUBY_HOME /bin $ source ~/.bash_profile $ ruby -v ruby 2.4.1p111 (2017-03-22 revision 58053) [x86_64-linux]
安装 Redis 插件 1 2 3 4 5 6 7 8 9 10 $ gem update --system $ gem install redis $ gem sources remove http://rubygems.org/ $ gem sources -a https://ruby.taobao.org/ $ cd ~/install $ wget https://rubygems.org/downloads/redis-3.2.2.gem
redis-trib 创建分布式集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 $ redis-trib.rb create --replicas 1 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.101:6380 192.168.1.102:6380 192.168.1.103:6380 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 Adding replica 192.168.1.102:6380 to 192.168.1.101:6379 Adding replica 192.168.1.101:6380 to 192.168.1.102:6379 Adding replica 192.168.1.103:6380 to 192.168.1.103:6379 M: 4c0fb081525a5f1893479225576b75f03cca065d 192.168.1.101:6379 slots:0-5460 (5461 slots) master M: 4f9fc4536f6e4e30666264738d632b1bb54799f0 192.168.1.102:6379 slots:5461-10922 (5462 slots) master M: 4dde95537b69d2b23f2f9a4cd2a357a1e4af756e 192.168.1.103:6379 slots:10923-16383 (5461 slots) master S: 6ffea478b1e5d1187b85adc5b0bd11b6601dd556 192.168.1.101:6380 replicates 4f9fc4536f6e4e30666264738d632b1bb54799f0 S: 1213855d2c0d1b35020895af45dcd734da50ef2c 192.168.1.102:6380 replicates 4c0fb081525a5f1893479225576b75f03cca065d S: 94478f8642d5a0cef1a989a620f132221e35fc8a 192.168.1.103:6380 replicates 4dde95537b69d2b23f2f9a4cd2a357a1e4af756e Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join ... >>> Performing Cluster Check (using node 192.168.1.101:6379) M: 4c0fb081525a5f1893479225576b75f03cca065d 192.168.1.101:6379 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 6ffea478b1e5d1187b85adc5b0bd11b6601dd556 192.168.1.101:6380 slots: (0 slots) slave replicates 4f9fc4536f6e4e30666264738d632b1bb54799f0 M: 4dde95537b69d2b23f2f9a4cd2a357a1e4af756e 192.168.1.103:6379 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: 1213855d2c0d1b35020895af45dcd734da50ef2c 192.168.1.102:6380 slots: (0 slots) slave replicates 4c0fb081525a5f1893479225576b75f03cca065d S: 94478f8642d5a0cef1a989a620f132221e35fc8a 192.168.1.103:6380 slots: (0 slots) slave replicates 4dde95537b69d2b23f2f9a4cd2a357a1e4af756e M: 4f9fc4536f6e4e30666264738d632b1bb54799f0 192.168.1.102:6379 slots:5461-10922 (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
redis-cli 集群状态检查 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ redis-cli -c -p 6379 127.0.0.1:6379> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_sent:376 cluster_stats_messages_received:376
关闭 遇到的坑 cannot load such file — zlib 描述 1 2 3 4 5 6 7 $ gem install -l redis-3.2.2.gem ERROR: Loading command : install (LoadError) cannot load such file -- zlib ERROR: While executing gem ... (NoMethodError) undefined method `invoke_with_build_args' for nil:NilClass
解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ yum install zlib-devel $ yum reinstall --downloadonly --downloaddir=/opt/software/zlib zlib-devel zlib libc.so.6 glibc-common glibc libfreebl3.so zlib-1.2.3-27.el6 -y $ ll /opt/software/zlib -rw-r--r-- 1 root root 4558520 Feb 18 2016 glibc-2.12-1.166.el6_7.7.i686.rpm -rw-r--r-- 1 root root 14887196 Feb 18 2016 glibc-common-2.12-1.166.el6_7.7.x86_64.rpm -rw-r--r-- 1 root root 118976 Nov 9 2011 nss-softokn-freebl-3.12.9-11.el6.i686.rpm -rw-r--r-- 1 root root 73604 Sep 26 2011 zlib-1.2.3-27.el6.i686.rpm -rw-r--r-- 1 root root 73864 Sep 26 2011 zlib-1.2.3-27.el6.x86_64.rpm -rw-r--r-- 1 root root 44728 Sep 26 2011 zlib-devel-1.2.3-27.el6.x86_64.rpm $ rpm -ivh glibc-2.12-1.166.el6_7.7.i686 --nodeps --force $ rpm -e --nodeps zlib-1.2.3-29.el6.x86_64
ERR Slot 0 is already busy 描述 1 2 ERR Slot 0 is already busy (Redis::CommandError)
解决 1 2 $ redis-cli -h 127.0.0.1 -p 6379 cluster reset soft && redis-cli -h 127.0.0.1 -p 6380 cluster reset soft
ERR Invalid node address specified 描述 1 2 3 $ redis-trib.rb create --replicas 1 yuzhouwan01:6379 yuzhouwan02:6379 yuzhouwan03:6379 yuzhouwan01:6380 yuzhouwan02:6380 yuzhouwan03:6380
解决 1 2 $ redis-trib.rb create --replicas 1 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.101:6380 192.168.1.102:6380 192.168.1.103:6380
连接集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private void init (DynamicPropUtils DP) { Object clusterListObj = DP.get(PROJECT_NAME, "redis.cluster.list" ); String clusterList; if (clusterListObj == null || StrUtils.isEmpty(clusterList = clusterListObj.toString())) { String error = String.format("Cannot get [%s-redis.cluster.list] from Dynamic PropUtils!" , PROJECT_NAME); _log.error(error); throw new RuntimeException (error); } String[] hostAndPort; Set<HostAndPort> jedisClusterNodes = new HashSet <>(); for (String clusters : clusterList.split("," )) { hostAndPort = clusters.split(":" ); jedisClusterNodes.add(new HostAndPort (hostAndPort[0 ], Integer.valueOf(hostAndPort[1 ]))); } JedisPoolConfig conf = new JedisPoolConfig (); conf.setMaxTotal(1000 ); conf.setMinIdle(50 ); conf.setMaxIdle(100 ); conf.setMaxWaitMillis(6 * 1000 ); conf.setTestOnBorrow(true ); pool = new JedisCluster (jedisClusterNodes, conf); }
集群操作 1 2 3 4 5 6 public Long putSet (String key, String... values) { return pool.sadd(key, values); } public Set<String> getSet (String key) { return pool.smembers(key); }
资源释放 1 2 3 public void close () throw IOException { if (pool != null ) pool.close(); }
1 2 3 4 5 6 7 $ redis-cli -h localhost -p 6380 CONFIG SET notify-keyspace-events AKE $ vim redis.conf notify-keyspace-events AKE
服务端验证 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ redis-cli 127.0.0.1:6379> set yuzhouwan01 blog OK 127.0.0.1:6379> expire yuzhouwan01 3 (integer ) 1 127.0.0.1:6379> ttl yuzhouwan01 (integer ) 0 127.0.0.1:6379> ttl yuzhouwan01 (integer ) -2 $ redis-cli -h localhost -p 6379 --csv psubscribe '*' "pmessage" ,"*" ,"__keyspace@0__:yuzhouwan01" ,"set" "pmessage" ,"*" ,"__keyevent@0__:set" ,"yuzhouwan01" "pmessage" ,"*" ,"__keyspace@0__:yuzhouwan01" ,"expire" "pmessage" ,"*" ,"__keyevent@0__:expire" ,"yuzhouwan01" "pmessage" ,"*" ,"__keyspace@0__:yuzhouwan01" ,"expired" "pmessage" ,"*" ,"__keyevent@0__:expired" ,"yuzhouwan01"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 private String getClusterList (DynamicPropUtils DP) { Object clusterListObj = DP.get(PROJECT_NAME, "redis.cluster.list" ); String clusterList; if (clusterListObj == null || StrUtils.isEmpty(clusterList = clusterListObj.toString())) { String error = String.format("Cannot get [%s-redis.cluster.list] from Dynamic PropUtils!" , PROJECT_NAME); _log.error(error); throw new RuntimeException (error); } return clusterList; } private JedisPoolConfig buildConf () { JedisPoolConfig conf = new JedisPoolConfig (); conf.setMaxTotal(1000 ); conf.setMinIdle(50 ); conf.setMaxIdle(100 ); conf.setTestOnCreate(true ); conf.setTestOnBorrow(true ); conf.setTestOnReturn(true ); conf.setTestWhileIdle(true ); conf.setNumTestsPerEvictionRun(30 ); return conf; } private void initPools (DynamicPropUtils DP) { String clusterList = getClusterList(DP); pools = new LinkedList <>(); String[] hostAndPort; for (String clusters : clusterList.split("," )) { hostAndPort = clusters.split(":" ); pools.add(new JedisPool (buildConf(), hostAndPort[0 ], Integer.valueOf(hostAndPort[1 ]))); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 try (RedisClusterConnPool pool = new RedisClusterConnPool (dp, true )) { List<JedisPool> jedis = pool.getPools(); JedisPubSub jedisPubSub = new JedisPubSub () { @Override public void onPSubscribe (String pattern, int subscribedChannels) { _log.info("onPSubscribe {} {}" , pattern, subscribedChannels); } @Override public void onPMessage (String pattern, String channel, String message) { _log.info("onPMessage: {}, Channel: {}, Message: {}" , pattern, channel, message); } }; for (JedisPool j : jedis) j.getResource().psubscribe(jedisPubSub, "__keyevent@*__:expired" ); }
1 2 3 4 5 6 7 8 pool.put("yuzhouwan01" , "blog01" ); pool.expire("yuzhouwan01" , 2 ); Thread.sleep(2100 ); assertEquals(null , pool.get("yuzhouwan01" )); 2017 -07 -26 16 :18 :56.045 | INFO | onPMessage Pattern: *, Channel: __keyevent@0__:set, Message: yuzhouwan01 | com.yuzhouwan.bigdata.redis.notification.RedisNotification.onPMessage | RedisNotification.java:61 2017 -07 -26 16 :18 :56.045 | INFO | onPMessage Pattern: *, Channel: __keyevent@0__:expire, Message: yuzhouwan01 | com.yuzhouwan.bigdata.redis.notification.RedisNotification.onPMessage | RedisNotification.java:61 2017 -07 -26 16 :18 :57.064 | INFO | onPMessage Pattern: *, Channel: __keyevent@0__:expired, Message: yuzhouwan01 | com.yuzhouwan.bigdata.redis.notification.RedisNotification.onPMessage | RedisNotification.java:61
实战技巧 匹配删除 1 2 3 4 5 6 7 8 $ redis-cli flushdb $ redis-cli --raw -n 1 keys "yuzhouwan*" | xargs -L1 -I{} redis-cli move {} 0 $ redis-cli 127.0.0.1:6379> keys yuzhouwan* (empty list or set ) $ redis-utils del 127.0.0.1 yuzhouwan*
数据容灾 主从热备 + 二级缓存 + 从库 AOF(主从切换)
参考
全局流控 流控方案 Leaky bucket 漏桶算法 桶内水溢出时,可以把消息放到队列中等待
Token bucket 令牌桶算法 桶内令牌不足时,可以把消息放到队列中等待
实现方式 Guava RateLimiter Guava 无法做到全局流控
Redis Expire 机制 如果设置的超时时间过长,可能对内存有一定的损耗
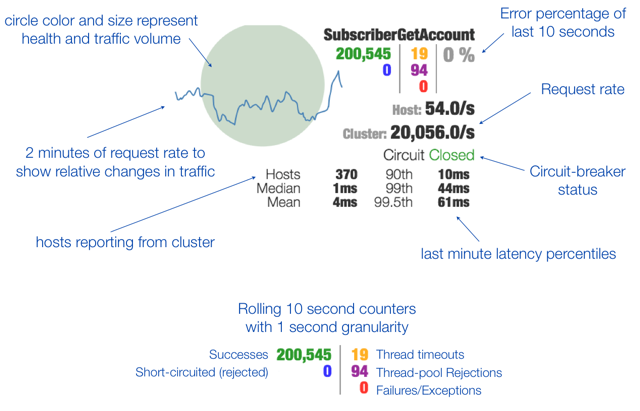
Hystrix 限流 支持 自动降级、熔断与恢复、依赖隔离、异常记录、流量控制、实时监控,不过会存在一定的 代码侵入 和 性能损耗 的问题(1%~5%)
(图片来源:Hystrix ™ 官网)
参考
Tips: Full code is here .
技术内幕 缓存穿透 vs 缓存雪崩 vs 缓存失效 缓存穿透 场景描述 一般的缓存系统,都是按照 key 去缓存查询,如果不存在对应的 value,就应该去后端系统查找(比如 DB)。如果 key 对应的 value 是一定不存在的,并且对该 key 并发请求量很大,就会对后端系统造成很大的压力,我们称之为缓存穿透
解决方案
对查询结果为空的情况也进行缓存,缓存过期时间设置短一点(避免消耗太多的缓存空间),或者该 key 对应的数据 insert 了之后清理缓存
对一定不存在的 key 进行过滤。可以把所有的可能存在的 key 放到一个大的 Bitmap 中,查询时通过该 Bitmap 过滤
排查是否是自身程序或者数据的问题,亦或是外部恶意攻击或者爬虫,导致大量访问不存在的 key 值
缓存雪崩 场景描述 缓存雪崩 ,是指当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如 DB)带来很大压力
解决方案
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待
不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀
做二级缓存,A1 为原始缓存,A2 为拷贝缓存。A1 失效时,可以访问 A2。A1 缓存失效时间设置为短期,A2 设置为长期
保证缓存层服务的高可用,后端组件做好限流措施,并提前预演缓存层失效的场景
缓存失效 场景描述 缓存失效 ,是指缓存集中在一段时间内失效,DB 的压力凸显
解决方案 这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上
其他 当发生大量的缓存穿透 ,例如对某个失效的缓存的大并发访问就造成了缓存雪崩
缓存失效 的同时发生雪崩效应 ,对底层系统的冲击将会非常大。这时候,可以使用双缓存机制,在工作缓存之外另外维护一层灾备缓存
双缓存 vs 二级缓存 一般的,用 Keepalived 做双机热备,而用 J2Cache 来做二级缓存
Tips: Full code is here .
为什么 Redis 一致性算法使用 Raft ,而不是 Paxos ? 没有应用场景上的区别,主要是因为 Raft 算法更为简单 、好懂 和 易实现
协议上的简化 最后主要 RPC 只有两个,其他协议的二阶段、三阶段也都变成 看起来像是一阶段
Term 概念的强化 看起来似乎 Paxos 也有重选 Leader 的机制,但是强化概念,并增加一个 Term,包含有一个 Leader、Entry 与 Term 相关的属性等都大大简化了流程
Log 只会从 Leader 到 Follower 单向同步 实现一下,会发现减少了很多问题,代码实现的复杂度也下降了很多
性能
都比较高,性能对我们来说应该都不是瓶颈
从 TPS 的角度来看,Redis 和 Memcached 差不多,要略优于 MongoDB
操作的便利性
Redis
Memcached
MongoDB
内存空间的大小和数据量的大小
RedisK-V 设置过期时间(类似 Memcached)
Memcached
MongoDB
可用性
Redis
Memcached
MongoDB
持久化
Redis
Memcached
MongoDB
事务性
Redis
Memcached
MongoDB
数据分析
MongoDB
应用场景
Redis
Memcached
MongoDB
群名称
群号
人工智能(高级)
人工智能(进阶)
BigData
算法