You are now connected to database "druid" as user "druid".
1 2
-- 列出所有的表 > \dt
1 2 3 4 5 6 7 8 9 10 11 12 13 14
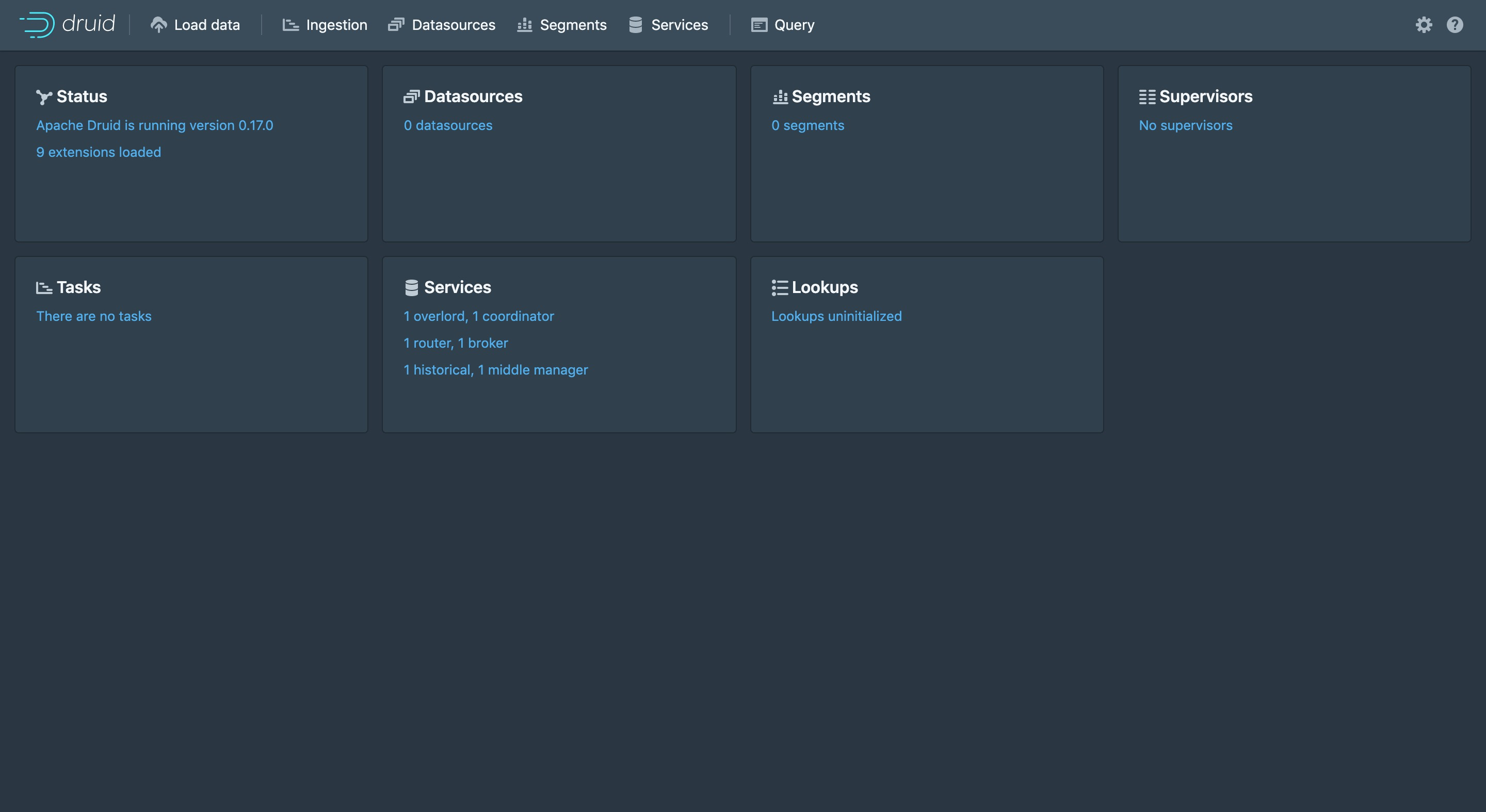
List of relations Schema | Name | Type | Owner --------+-----------------------+-------+------- public | druid_audit | table | druid public | druid_config | table | druid public | druid_datasource | table | druid public | druid_pendingsegments | table | druid public | druid_rules | table | druid public | druid_segments | table | druid public | druid_supervisors | table | druid public | druid_tasklocks | table | druid public | druid_tasklogs | table | druid public | druid_tasks | table | druid (10 rows)
1 2
-- 查看 druid_segments 表结构 > \d+ druid_segments;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Table "public.druid_segments" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------------+------------------------+-----------+----------+---------+----------+--------------+------------- id | character varying(255) | | not null | | extended | | datasource | character varying(255) | | not null | | extended | | created_date | character varying(255) | | not null | | extended | | start | character varying(255) | | not null | | extended | | end | character varying(255) | | not null | | extended | | partitioned | boolean | | not null | | plain | | version | character varying(255) | | not null | | extended | | used | boolean | | not null | | plain | | payload | bytea | | not null | | extended | | Indexes: "druid_segments_pkey" PRIMARY KEY, btree (id) "idx_druid_segments_datasource_used_end_start" btree (datasource, used, "end", start) "idx_druid_segments_used" btree (used)
1 2
-- 查看 segment 的元数据 >select id, datasource, created_date, start, "end", partitioned, version, used from public.druid_segments;
1
wikipedia_2016-06-27T00:00:00.000Z_2016-06-28T00:00:00.000Z_2020-06-04T07:11:42.714Z | wikipedia | 2020-06-04T07:14:50.619Z | 2016-06-27T00:00:00.000Z | 2016-06-28T00:00:00.000Z | t | 2020-06-04T07:11:42.714Z | t
-- 查看 druid 用户的权限 >select rolname, rolsuper, rolcreaterole, rolcreatedb, rolcanlogin, rolreplication from pg_roles where rolname ='druid';
1 2 3 4
rolname | rolsuper | rolcreaterole | rolcreatedb | rolcanlogin | rolreplication ---------+----------+---------------+-------------+-------------+---------------- druid | f | f | t | t | f (1 row)
$ curl -X POST -H 'Content-Type: application/json' -u xxx:yyy http://localhost:8082/druid/v2/sql -d '{"query":"SELECT * FROM wikipedia ORDER BY __time DESC LIMIT 1"}' | jq
$ bin/plyql --host <broker host>:8082 -q "select TIME_PART(__time, MINUTE_OF_DAY, 'Asia/Shanghai'), max(gcCount_max) from yuzhouwan_metrics where serverName='druid01' and __time>='2017-04-04' and __time<'2017-04-05' group by 1" -Z Asia/Shanghai
# 不参与 group by 的 指标需要进行 sum / min / max 之类的聚合操作 $ bin/plyql --host <broker host>:8082 -q "select TIME_PART(__time, MINUTE_OF_DAY, 'Asia/Shanghai'), metric, sum(sum) as sum_value from yuzhouwan_metrics where level='level1' and metric='metric1' and __time>='2017-04-04' and __time<'2017-04-05' group by 1, 2 order by sum_value desc limit 10" -Z Asia/Shanghai -v
展示查询对应的 JSON 语句
增加 -v 参数,可以将查询的 JSON 语句展示出来,用于检查 plyql 语句是否符合预期
1
$ bin/plyql --host <broker host>:8082 -q "select distinct level from yuzhouwan_metrics where __time>='2017-01-16 03:00'" -Z Asia/Shanghai -v
$ time bin/plyql -h <broker host>:8082 -q "select * from yuzhouwan_metrics where __time>='2017-03-18' and __time<'2017-03-19' and level='level01' limit 100" -Z Asia/Shanghai
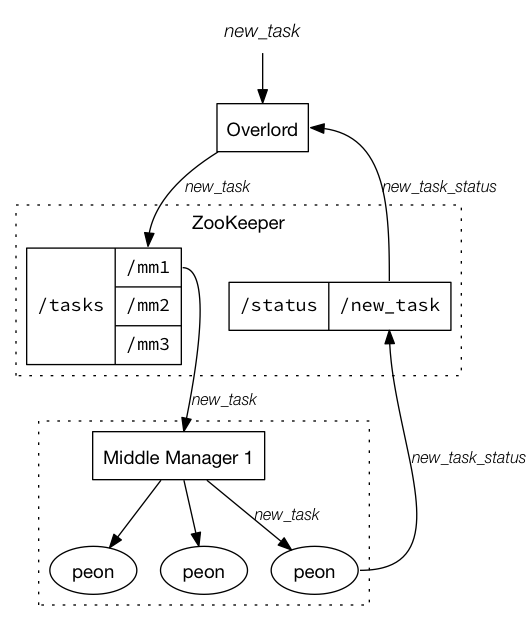
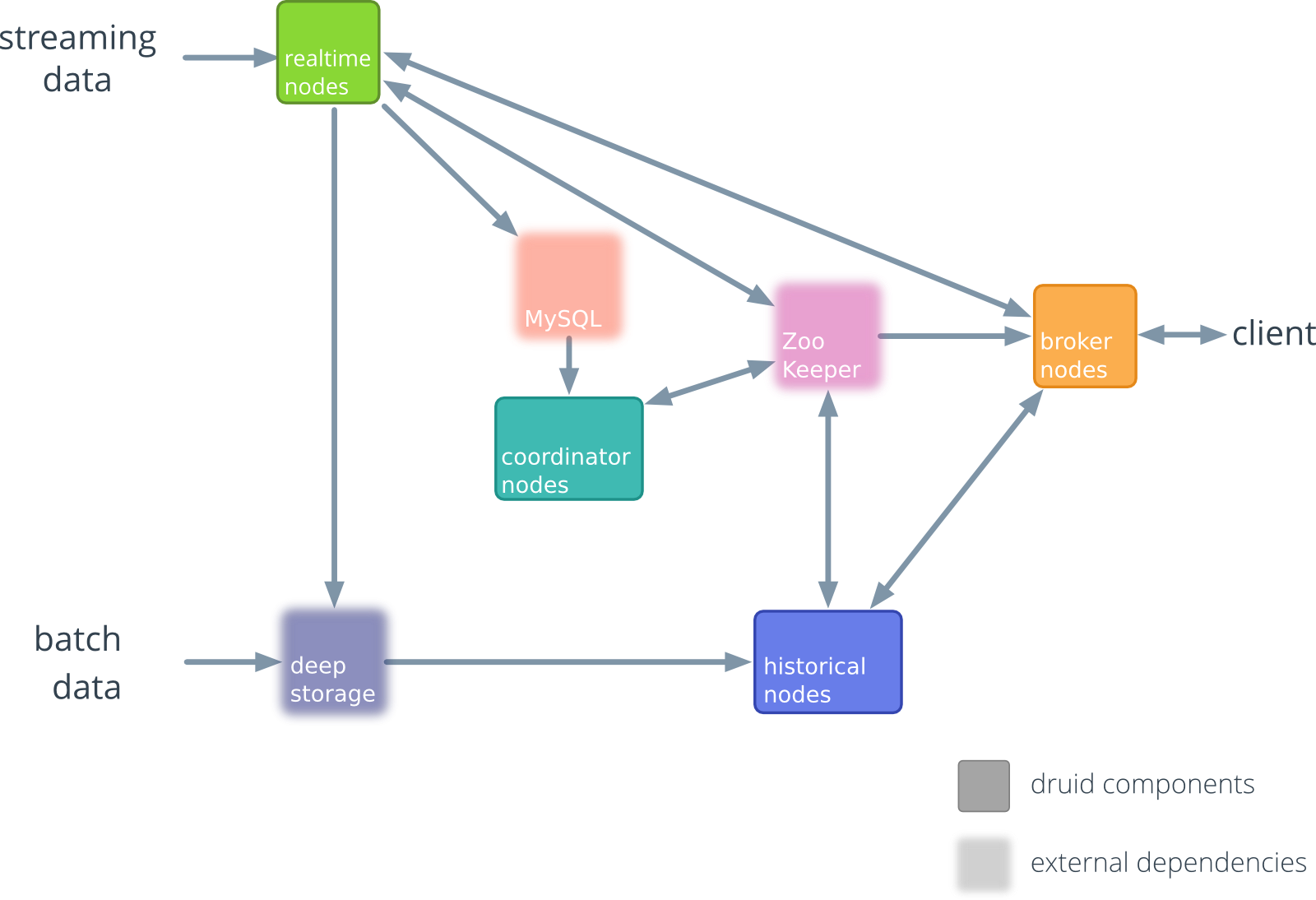
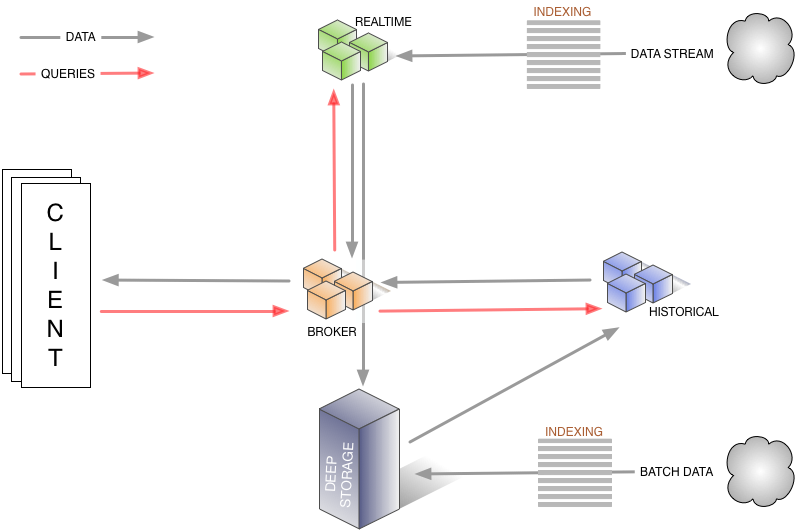
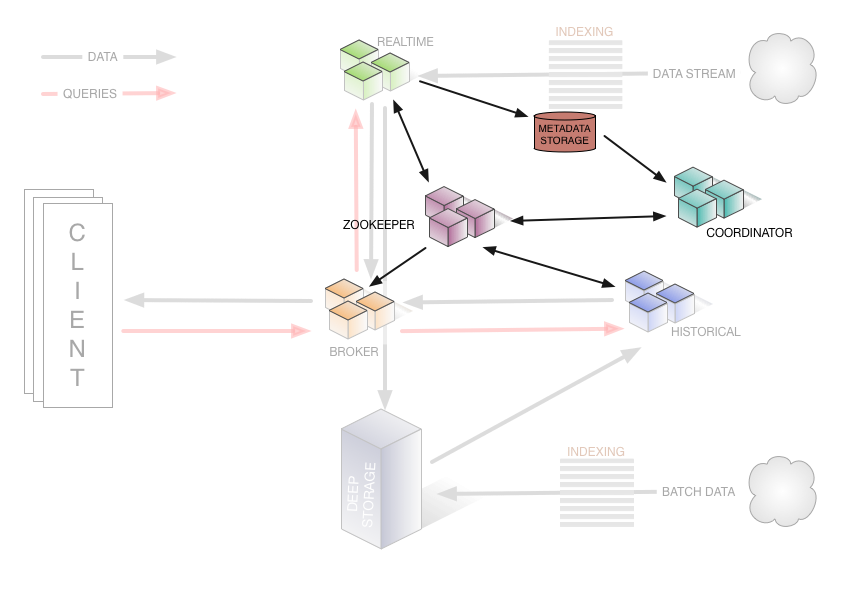
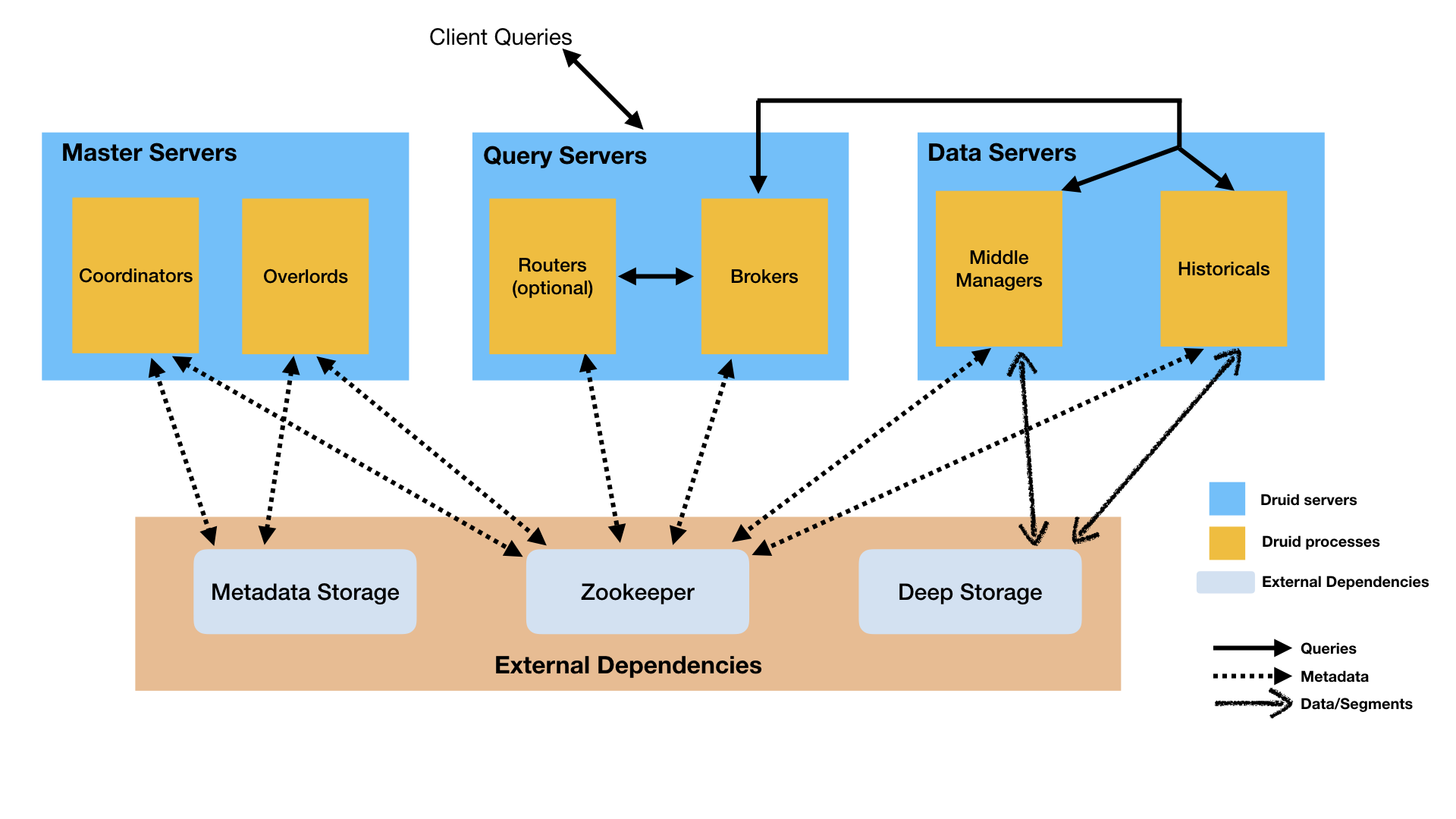
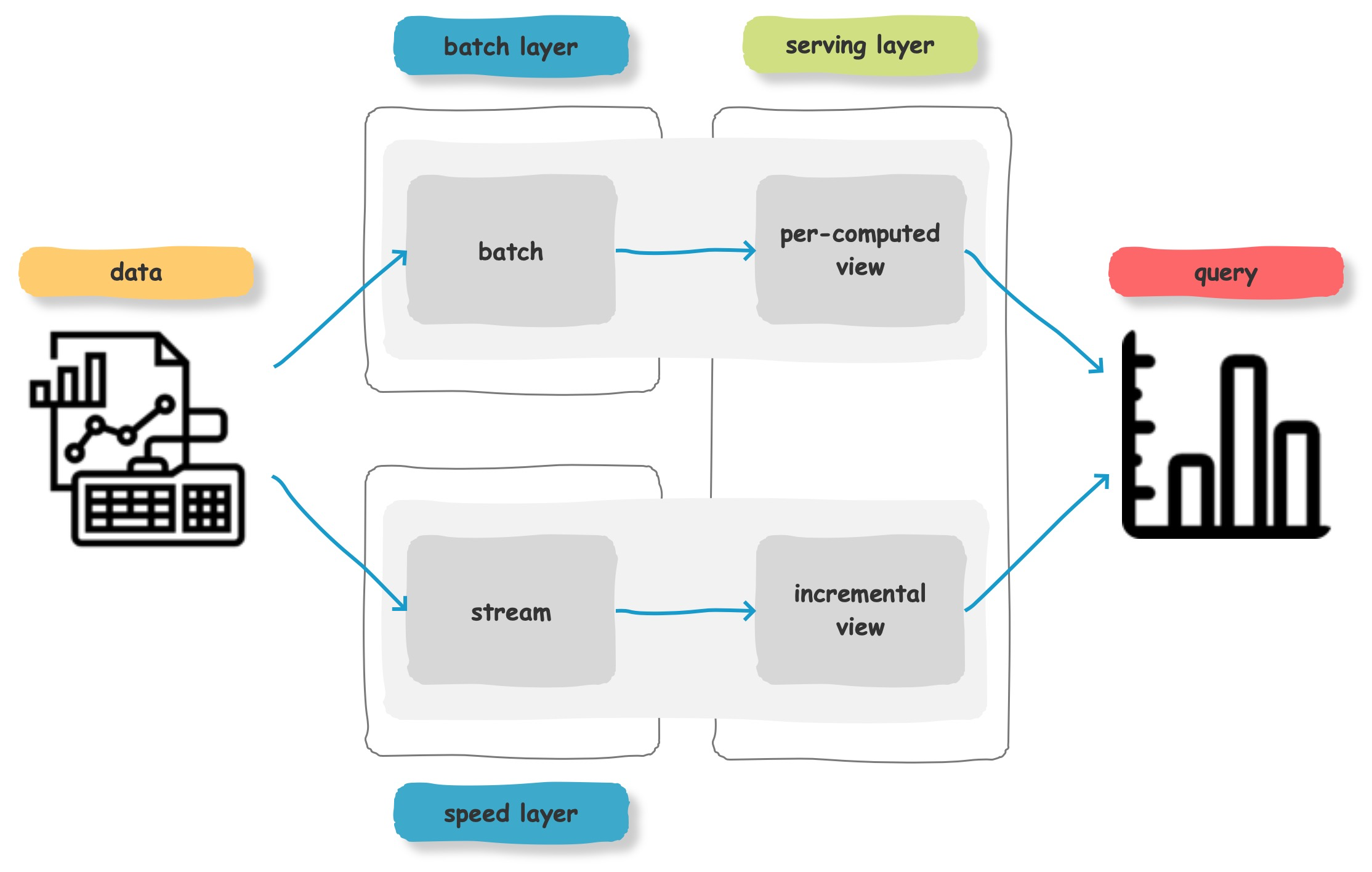
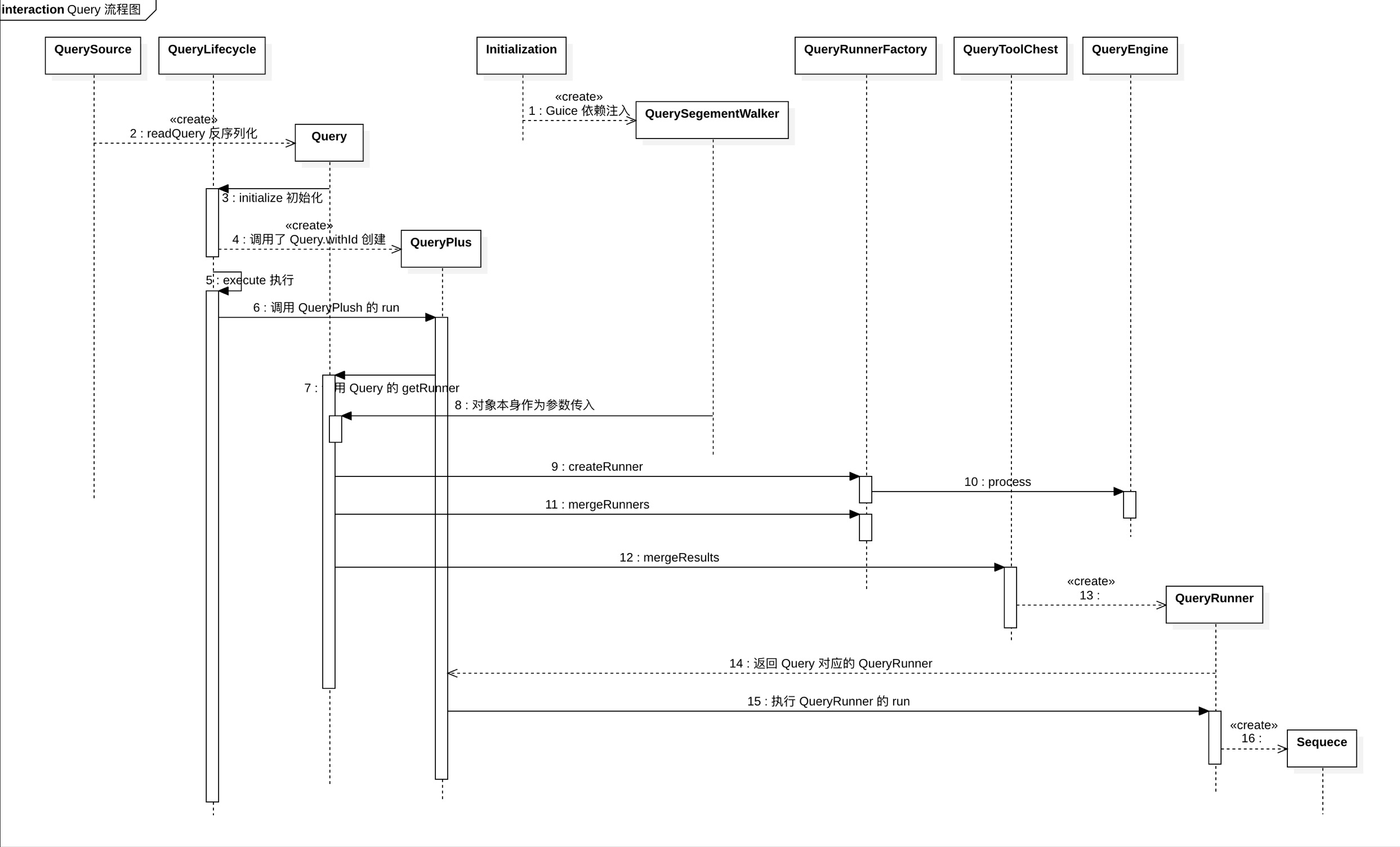
通常流式数据的链路为 Raw data → Kafka → Stream processor(optional, typically for ETL) → Kafka(optional)→ Druid → Application / user,而批处理的链路为 Raw data → Kafka(optional)→ HDFS → ETL process(optional)→ Druid → Application / user
sequenceDiagram
participant Historical
participant Disk
participant ZooKeeper
ZooKeeper -->> Historical : CHILD_ADDED event
Historical ->>+ Disk : get all files under info_dir
Disk ->>- Historical : return cached segments info
alt segment does not exist
Historical ->> Disk : delete the corresponding file under info_dir
end
Historical ->> Historical : load local segment
Historical ->> ZooKeeper : register loaded segment
NAME: my-release LAST DEPLOYED: Mon Jul 19 08:03:13 2020 NAMESPACE: test-new-grafana STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: ** Please be patient while the chart is being deployed **
1. Get the application URL by running these commands: echo"Browse to http://127.0.0.1:8080" kubectl port-forward svc/my-release-grafana 8080:3000 &
2. Get the admin credentials: echo"User: admin" echo"Password: $(kubectl get secret my-release-grafana-admin --namespace test-new-grafana -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 --decode)"
NAME: grafana-1675914054 LAST DEPLOYED: Sat Feb 4 11:40:54 2023 NAMESPACE: test-new-grafana STATUS: deployed REVISION: 1 NOTES: 1. Get your 'admin' user password by running:
Get the Grafana URL to visit by running these commands in the same shell: export POD_NAME=$(kubectl get pods --namespace test-new-grafana -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana-1675914054" -o jsonpath="{.items[0].metadata.name}") kubectl --namespace test-new-grafana port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
$ uname -a Linux olap03-sit.yuzhouwan.com 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
$ cat /proc/version Linux version 2.6.32-431.el6.x86_64 (mockbuild@c6b8.bsys.dev.centos.org) (gcc version 4.4.7 20120313 (Red Hat 4.4.7-4) (GCC) ) #1 SMP Fri Nov 22 03:15:09 UTC 2013
# init database $ cd /root/graphite/lib/python2.7/site-packages/opt/graphite/webapp/graphite/ $ python /root/graphite/lib/python2.7/site-packages/opt/graphite/webapp/graphite/manage.py syncdb
Would you like to create one now? (yes/no): yes Username (leave blank to use 'root'): graphite Email address: bj@yuzhouwan.com Password: Password (again): Superuser created successfully.
(graphite) [root@graphite-sit.yuzhouwan.com conf]# /root/graphite/bin/carbon-cache.py start Traceback (most recent call last): File "/root/graphite/bin/carbon-cache.py", line 28, in <module> from carbon.util import run_twistd_plugin ImportError: No module named carbon.util
django.db.utils.OperationalError: unable to open database file
描述
1
$ python manage.py syncdb
1 2 3 4 5 6 7 8 9
/root/graphite/lib/python2.7/site-packages/opt/graphite/webapp/graphite/settings.py:246: UserWarning: SECRET_KEY isset to an unsafe default. This should be setin local_settings.py for better security warn('SECRET_KEY is set to an unsafe default. This should be set in local_settings.py for better security') Traceback (most recent call last): File "manage.py", line 13, in <module> execute_from_command_line(sys.argv) File "/root/graphite/lib/python2.7/site-packages/django/core/management/__init__.py", line 338, in execute_from_command_line utility.execute() // ... django.db.utils.OperationalError: unable to open database file
解决
change default SECRET_KEY in settings.py
1
$ vim /root/graphite/lib/python2.7/site-packages/opt/graphite/webapp/graphite/settings.py
1 2 3
# Django 1.5 requires this so we set a default but warn the user # SECRET_KEY = 'UNSAFE_DEFAULT' SECRET_KEY = 'graphite'
change DATABASE_NAME in sqlites
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
$ mkdir /root/graphite/sqlite $ cd /root/graphite/sqlite
# create database $ sqlite3 graphite.db $ sqlite3 sqlite>.help sqlite>.databases seq name file --- --------------- ------------------------------------------ 0 main /root/graphite/sqlite/graphite.db
# run 'python manage.py syncdb' again, then the graphite database disappeared
modify settings.py for sqlite database
1 2 3 4 5
$ cd /root/graphite/storage $ mkdir db $ cd db $ sqlite3 graphite.db $ vim /root/graphite/lib/python2.7/site-packages/django/conf/project_template/project_name/settings.py
#DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # } #} DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', # Add 'postgresql_psycopg2', 'postgresql', 'mysql', 'sqlite3' or 'oracle'. 'NAME': '/root/graphite/storage/db/graphite.db', # Or path to database file if using sqlite3. 'USER': '', # Not used with sqlite3. 'PASSWORD': '', # Not used with sqlite3. 'HOST': '', # Set to empty string for localhost. Not used with sqlite3. 'PORT': '', # Set to empty string for default. Not used with sqlite3. } }
SQLite version 3.6.20 Enter ".help"for instructions Enter SQL statements terminated with a ";" sqlite> .databases seq name file --- --------------- -------------------------------------- 0 main /root/graphite/storage/db/graphite.db
tail: /root/graphite/storage/log/webapp/process.log: file truncated Traceback (most recent call last): File "/root/graphite/bin/django-admin", line 11, in <module> sys.exit(execute_from_command_line()) File "/root/graphite/lib/python2.7/site-packages/django/core/management/__init__.py", line 338, in execute_from_command_line utility.execute() File "/root/graphite/lib/python2.7/site-packages/django/core/management/__init__.py", line 303, in execute settings.INSTALLED_APPS File "/root/graphite/lib/python2.7/site-packages/django/conf/__init__.py", line 48, in __getattr__ self._setup(name) File "/root/graphite/lib/python2.7/site-packages/django/conf/__init__.py", line 44, in _setup self._wrapped = Settings(settings_module) File "/root/graphite/lib/python2.7/site-packages/django/conf/__init__.py", line 92, in __init__ mod = importlib.import_module(self.SETTINGS_MODULE) File "/usr/local/python27/lib/python2.7/importlib/__init__.py", line 37, in import_module __import__(name) ImportError: No module named graphite.settings
解决
修改 local_settings.py
1
$ vim /root/graphite/lib/python2.7/site-packages/opt/graphite/webapp/graphite/local_settings.py
1 2 3 4 5 6 7 8 9 10
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', # Add 'postgresql_psycopg2', 'postgresql', 'mysql', 'sqlite3' or 'oracle'. 'NAME': '/root/graphite/storage/db/graphite.db', # Or path to database file if using sqlite3. 'USER': '', # Not used with sqlite3. 'PASSWORD': '', # Not used with sqlite3. 'HOST': '', # Set to empty string for localhost. Not used with sqlite3. 'PORT': '', # Set to empty string for default. Not used with sqlite3. } }
OError: [Errno 2] No such file or directory: ‘/root/graphite/lib/python2.7/site-packages/opt/graphite/storage/log/webapp/info.log’
描述
访问 http://192.168.1.102:8085/ 返回如下信息:
1 2 3 4 5 6 7
Traceback (most recent call last): File "/root/graphite/lib/python2.7/site-packages/django/core/handlers/base.py", line 119, in get_response resolver_match = resolver.resolve(request.path_info) # ... File "/usr/local/python27/lib/python2.7/logging/__init__.py", line 943, in _open stream = open(self.baseFilename, self.mode) IOError: [Errno 2] No such file or directory: '/root/graphite/lib/python2.7/site-packages/opt/graphite/storage/log/webapp/info.log'
# graphite 配置没有问题 $ vim /root/graphite/lib/python2.7/site-packages/django/conf/project_template/project_name/settings.py
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', # Add 'postgresql_psycopg2', 'postgresql', 'mysql', 'sqlite3' or 'oracle'. 'NAME': '/root/graphite/storage/db/graphite.db', # Or path to database file if using sqlite3. 'USER': '', # Not used with sqlite3. 'PASSWORD': '', # Not used with sqlite3. 'HOST': '', # Set to empty string for localhost. Not used with sqlite3. 'PORT': '', # Set to empty string for default. Not used with sqlite3. } }
# 发现 sqlite 中并没有将 events 记录下来 (graphite) [root@kylin03-pre db]# sqlite3 /root/graphite/storage/db/graphite.db SQLite version 3.6.20 Enter ".help"for instructions Enter SQL statements terminated with a ";" sqlite> .databases seq name file --- --------------- ---------------------------------------- 0 main /root/graphite/storage/db/graphite.db sqlite> .tables account_mygraph dashboard_dashboard account_profile dashboard_dashboard_owners account_variable django_admin_log account_view django_content_type account_window django_migrations auth_group django_session auth_group_permissions events_event auth_permission tagging_tag auth_user tagging_taggeditem auth_user_groups url_shortener_link auth_user_user_permissions sqlite> select * from auth_user; 1|pbkdf2_sha256$20000$oEgzveEmcg9B$8xbilUymXlwVBAaB48xpUQwsfIucmeP/4C4YF3U6SlI=|1|graphite|||bj@yuzhouwan.com|1|1|2017-01-04 05:59:10.615950|2017-01-05 08:24:54.957631 2|pbkdf2_sha256$20000$gG1lK6FNg0h7$dXH47Wqc+Gj/qTyI6EKOajd+Pj1kKN+U5CtnmDo0K/0=|0|default|||default@localhost.localdomain|0|1|2017-01-04 06:53:34.687401| 3|pbkdf2_sha256$20000$fcQ5sYbw0cjk$anjZc4J0eRE51HGJ6D50c0c9+d08iY7lhWseke9RmEY=|0|druid||||0|1|2017-01-05 09:03:48.696161| sqlite> select * from events_event; # no data!
$ yum-config-manager --enable mysql57-community $ service mysqld start
$ mysql -uroot -p -S /home/mysql/data/mysql.sock
# 后面规范化部署的时候,可以创建 graphite 用户,并赋权 CREATE DATABASE graphite; # GRANT ALL PRIVILEGES ON graphite.* TO 'graphite'@'localhost' IDENTIFIED BY 'sysadmin'; GRANT ALL PRIVILEGES ON graphite.* TO 'root'@'localhost' IDENTIFIED BY 'sysadmin'; FLUSH PRIVILEGES;
$ vim /root/graphite/lib/python2.7/site-packages/django/conf/project_template/project_name/settings.py
Traceback (most recent call last): File "carbon-cache.py", line 28, in <module> from carbon.util import run_twistd_plugin File "/opt/graphite/lib/carbon/util.py", line 20, in <module> from twisted.python.util import initgroups ImportError: No module named twisted.python.util
{ "error":"Unknown exception", "errorClass":"java.lang.IllegalStateException", "errorMessage":"Pool was initialized with limit = 0, there are no objects to take.", "host":"druid01:8101" }
Caused by: org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "druid_pendingsegments_pkey" Detail: Key (id)=(yuzhouwan_2024-01-06T11:15:00.000Z_2024-01-06T11:30:00.000Z_2024-01-06T11:15:00.092Z_12) already exists. at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2284) ~[?:?] at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2003) ~[?:?] at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:200) ~[?:?] at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:424) ~[?:?] at org.postgresql.jdbc.PgPreparedStatement.executeWithFlags(PgPreparedStatement.java:161) ~[?:?] at org.postgresql.jdbc.PgPreparedStatement.execute(PgPreparedStatement.java:155) ~[?:?] at org.apache.commons.dbcp2.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:198) ~[commons-dbcp2-2.0.1.jar:2.0.1] at org.apache.commons.dbcp2.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:198) ~[commons-dbcp2-2.0.1.jar:2.0.1] at org.skife.jdbi.v2.SQLStatement.internalExecute(SQLStatement.java:1328) ~[jdbi-2.63.1.jar:2.63.1] at org.skife.jdbi.v2.Update.execute(Update.java:56) ~[jdbi-2.63.1.jar:2.63.1] at io.druid.metadata.IndexerSQLMetadataStorageCoordinator.insertToMetastore(IndexerSQLMetadataStorageCoordinator.java:662) ~[druid-server-0.12.3-iap6.jar:0.12.3-iap6] at io.druid.metadata.IndexerSQLMetadataStorageCoordinator.allocatePendingSegment(IndexerSQLMetadataStorageCoordinator.java:547) ~[druid-server-0.12.3-iap6.jar:0.12.3-iap6] at io.druid.metadata.IndexerSQLMetadataStorageCoordinator.access$200(IndexerSQLMetadataStorageCoordinator.java:80) ~[druid-server-0.12.3-iap6.jar:0.12.3-iap6] at io.druid.metadata.IndexerSQLMetadataStorageCoordinator$3.inTransaction(IndexerSQLMetadataStorageCoordinator.java:404) ~[druid-server-0.12.3-iap6.jar:0.12.3-iap6] at io.druid.metadata.IndexerSQLMetadataStorageCoordinator$3.inTransaction(IndexerSQLMetadataStorageCoordinator.java:399) ~[druid-server-0.12.3-iap6.jar:0.12.3-iap6] at org.skife.jdbi.v2.tweak.transactions.LocalTransactionHandler.inTransaction(LocalTransactionHandler.java:184) ~[jdbi-2.63.1.jar:2.63.1] at org.skife.jdbi.v2.BasicHandle.inTransaction(BasicHandle.java:327) ~[jdbi-2.63.1.jar:2.63.1] at org.skife.jdbi.v2.DBI$5.withHandle(DBI.java:333) ~[jdbi-2.63.1.jar:2.63.1] at org.skife.jdbi.v2.DBI.withHandle(DBI.java:281) ~[jdbi-2.63.1.jar:2.63.1] ... 80 more
// ... WARN [main] org.apache.druid.indexing.common.actions.RemoteTaskActionClient - Exception submitting action for task[partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z]: {"type":"surrogateAction","surrogateId":"index_parallel_yuzhou wan_ajapddgn_2024-10-08T06:09:27.679Z","taskAction":{"type":"lockTryAcquire","lockType":"EXCLUSIVE","interval":"2024-08-28T00:00:00.000Z/2024-09-03T00:00:00.000Z"}} (org.apache.druid.java.util.common.IOE: Error with status[500 Internal Server Error] and message[{"error":"Unable to grant lock to inactive Task [index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z]"}]. Check overlord logs for details.) WARN [main] org.apache.druid.indexing.common.actions.RemoteTaskActionClient - Will try again in [PT46.262S]. WARN [main] org.apache.druid.indexing.common.actions.RemoteTaskActionClient - Exception submitting action for task[partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z]: {"type":"surrogateAction","surrogateId":"index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z","taskAction":{"type":"lockTryAcquire","lockType":"EXCLUSIVE","interval":"2024-08-28T00:00:00.000Z/2024-09-03T00:00:00.000Z"}} (org.apache.druid.java.util.common.IOE: Error with status[500 Internal Server Error] and message[{"error":"Unable to grant lock to inactive Task [index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z]"}]. Check overlord logs for details.) ERROR [main] org.apache.druid.cli.CliPeon - Error when starting up. Failing. java.lang.reflect.InvocationTargetException: null at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_275] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_275] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_275] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_275] at org.apache.druid.java.util.common.lifecycle.Lifecycle$AnnotationBasedHandler.start(Lifecycle.java:446) ~[druid-core-0.22.1.jar:0.22.1] at org.apache.druid.java.util.common.lifecycle.Lifecycle.start(Lifecycle.java:341) ~[druid-core-0.22.1.jar:0.22.1] at org.apache.druid.guice.LifecycleModule$2.start(LifecycleModule.java:143) ~[druid-core-0.22.1.jar:0.22.1] at org.apache.druid.cli.GuiceRunnable.initLifecycle(GuiceRunnable.java:115) [druid-services-0.22.1.jar:0.22.1] at org.apache.druid.cli.CliPeon.run(CliPeon.java:318) [druid-services-0.22.1.jar:0.22.1] at org.apache.druid.cli.Main.main(Main.java:113) [druid-services-0.22.1.jar:0.22.1] Caused by: org.apache.druid.java.util.common.ISE: Failed to run task[partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z] isReady at org.apache.druid.indexing.worker.executor.ExecutorLifecycle.start(ExecutorLifecycle.java:177) ~[druid-indexing-service-0.22.1.jar:0.22.1] ... 10 more Caused by: org.apache.druid.java.util.common.IOE: Error with status[500 Internal Server Error] and message[{"error":"Unable to grant lock to inactive Task [index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z]"}]. Check overlord logs for details. at org.apache.druid.indexing.common.actions.RemoteTaskActionClient.submit(RemoteTaskActionClient.java:98) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.actions.SurrogateTaskActionClient.submit(SurrogateTaskActionClient.java:43) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.AbstractBatchIndexTask.tryTimeChunkLock(AbstractBatchIndexTask.java:402) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.PartialDimensionCardinalityTask.isReady(PartialDimensionCardinalityTask.java:141) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.worker.executor.ExecutorLifecycle.start(ExecutorLifecycle.java:172) ~[druid-indexing-service-0.22.1.jar:0.22.1] ... 10 more
// ... INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Submitted a newtask[partial_dimension_cardinality_yuzhouwan_bielnedb_2024-10-08T08:22:16.849Z] for spec[index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z_98] INFO [task-monitor-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - [96/35972] tasks succeeded INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexPhaseRunner - Submit a newtaskfor spec[index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z_99] INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Submitted a newtask[partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z] for spec[index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z_99] INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexPhaseRunner - Cleaning up resources INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Request to cancel subtask[partial_dimension_cardinality_yuzhouwan_flbmkkfl_2024-10-08T08:19:22.098Z] INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Request to cancel subtask[partial_dimension_cardinality_yuzhouwan_miehlmnd_2024-10-08T08:19:28.092Z] INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Request to cancel subtask[partial_dimension_cardinality_yuzhouwan_bielnedb_2024-10-08T08:22:16.849Z] WARN [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Inconsistent state: numRunningTasks[1] is still not zero after trying to cancel all running tasks. INFO [task-runner-0-priority-0] org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor - Stopped taskMonitor ERROR [task-runner-0-priority-0] org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner - Exception while running task[AbstractTask{id='index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z', groupId='index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z', taskResource=TaskResource{availabilityGroup='index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z', requiredCapacity=1}, dataSource='yuzhouwan', context={forceTimeChunkLock=true, useLineageBasedSegmentAllocation=true}}] java.lang.RuntimeException: com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'Cannot': was expecting(JSON String, Number, Array, Object or token 'null', 'true' or 'false') at [Source: (String)"Cannot find any task with id: [partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z]"; line: 1, column: 7] at org.apache.druid.client.indexing.HttpIndexingServiceClient.getTaskStatus(HttpIndexingServiceClient.java:283) ~[druid-server-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.TaskMonitor.submit(TaskMonitor.java:254) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexPhaseRunner.submitNewTask(ParallelIndexPhaseRunner.java:245) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexPhaseRunner.run(ParallelIndexPhaseRunner.java:173) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexSupervisorTask.runNextPhase(ParallelIndexSupervisorTask.java:276) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexSupervisorTask.runHashPartitionMultiPhaseParallel(ParallelIndexSupervisorTask.java:652) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexSupervisorTask.runMultiPhaseParallel(ParallelIndexSupervisorTask.java:601) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.batch.parallel.ParallelIndexSupervisorTask.runTask(ParallelIndexSupervisorTask.java:462) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.task.AbstractBatchIndexTask.run(AbstractBatchIndexTask.java:159) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner$SingleTaskBackgroundRunnerCallable.call(SingleTaskBackgroundRunner.java:471) [druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.SingleTaskBackgroundRunner$SingleTaskBackgroundRunnerCallable.call(SingleTaskBackgroundRunner.java:443) [druid-indexing-service-0.22.1.jar:0.22.1] at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_275] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_275] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_275] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_275] Caused by: com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'Cannot': was expecting(JSON String, Number, Array, Object or token 'null', 'true' or 'false') at [Source: (String)"Cannot find any task with id: [partial_dimension_cardinality_yuzhouwan_bajnofbm_2024-10-08T08:22:29.096Z]"; line: 1, column: 7] at com.fasterxml.jackson.core.JsonParser._constructError(JsonParser.java:1840) ~[jackson-core-2.10.5.jar:2.10.5] at com.fasterxml.jackson.core.base.ParserMinimalBase._reportError(ParserMinimalBase.java:722) ~[jackson-core-2.10.5.jar:2.10.5] at com.fasterxml.jackson.core.json.ReaderBasedJsonParser._reportInvalidToken(ReaderBasedJsonParser.java:2873) ~[jackson-core-2.10.5.jar:2.10.5] at com.fasterxml.jackson.core.json.ReaderBasedJsonParser._handleOddValue(ReaderBasedJsonParser.java:1919) ~[jackson-core-2.10.5.jar:2.10.5] at com.fasterxml.jackson.core.json.ReaderBasedJsonParser.nextToken(ReaderBasedJsonParser.java:772) ~[jackson-core-2.10.5.jar:2.10.5] at com.fasterxml.jackson.databind.ObjectMapper._initForReading(ObjectMapper.java:4356) ~[jackson-databind-2.10.5.1.jar:2.10.5.1] at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:4205) ~[jackson-databind-2.10.5.1.jar:2.10.5.1] at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3214) ~[jackson-databind-2.10.5.1.jar:2.10.5.1] at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3197) ~[jackson-databind-2.10.5.1.jar:2.10.5.1] at org.apache.druid.client.indexing.HttpIndexingServiceClient.getTaskStatus(HttpIndexingServiceClient.java:275) ~[druid-server-0.22.1.jar:0.22.1] ... 14 more INFO [task-runner-0-priority-0] org.apache.druid.indexing.worker.executor.ExecutorLifecycle - Task completed with status: { "id" : "index_parallel_yuzhouwan_ajapddgn_2024-10-08T06:09:27.679Z", "status" : "FAILED", "duration" : 7972711, "errorMsg" : "java.lang.RuntimeException: com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'Canno...", "location" : { "host" : null, "port" : -1, "tlsPort" : -1 } } // ...
WARN [qtp284957218-197] org.apache.druid.indexing.overlord.http.OverlordResource - Failed to perform task action org.apache.druid.java.util.common.ISE: Unable to grant lock to inactive Task [index_parallel_yuzhouwan_dgjlmlan_2024-10-09T02:42:46.230Z] at org.apache.druid.indexing.overlord.TaskLockbox.tryLock(TaskLockbox.java:343) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.actions.TimeChunkLockTryAcquireAction.perform(TimeChunkLockTryAcquireAction.java:80) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.actions.TimeChunkLockTryAcquireAction.perform(TimeChunkLockTryAcquireAction.java:39) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.actions.SurrogateAction.perform(SurrogateAction.java:70) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.common.actions.LocalTaskActionClient.submit(LocalTaskActionClient.java:74) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.http.OverlordResource$4.apply(OverlordResource.java:504) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.http.OverlordResource$4.apply(OverlordResource.java:493) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.http.OverlordResource.asLeaderWith(OverlordResource.java:869) ~[druid-indexing-service-0.22.1.jar:0.22.1] at org.apache.druid.indexing.overlord.http.OverlordResource.doAction(OverlordResource.java:490) ~[druid-indexing-service-0.22.1.jar:0.22.1] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_275] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_275] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_275] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_275] at com.sun.jersey.spi.container.JavaMethodInvokerFactory$1.invoke(JavaMethodInvokerFactory.java:60) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.model.method.dispatch.AbstractResourceMethodDispatchProvider$ResponseOutInvoker._dispatch(AbstractResourceMethodDispatchProvider.java:205) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.model.method.dispatch.ResourceJavaMethodDispatcher.dispatch(ResourceJavaMethodDispatcher.java:75) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.uri.rules.HttpMethodRule.accept(HttpMethodRule.java:302) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.uri.rules.RightHandPathRule.accept(RightHandPathRule.java:147) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.uri.rules.ResourceClassRule.accept(ResourceClassRule.java:108) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.uri.rules.RightHandPathRule.accept(RightHandPathRule.java:147) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.uri.rules.RootResourceClassesRule.accept(RootResourceClassesRule.java:84) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.application.WebApplicationImpl._handleRequest(WebApplicationImpl.java:1542) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.application.WebApplicationImpl._handleRequest(WebApplicationImpl.java:1473) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.application.WebApplicationImpl.handleRequest(WebApplicationImpl.java:1419) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.server.impl.application.WebApplicationImpl.handleRequest(WebApplicationImpl.java:1409) ~[jersey-server-1.19.3.jar:1.19.3] at com.sun.jersey.spi.container.servlet.WebComponent.service(WebComponent.java:409) ~[jersey-servlet-1.19.3.jar:1.19.3] at com.sun.jersey.spi.container.servlet.ServletContainer.service(ServletContainer.java:558) ~[jersey-servlet-1.19.3.jar:1.19.3] at com.sun.jersey.spi.container.servlet.ServletContainer.service(ServletContainer.java:733) ~[jersey-servlet-1.19.3.jar:1.19.3] at javax.servlet.http.HttpServlet.service(HttpServlet.java:790) ~[javax.servlet-api-3.1.0.jar:3.1.0] at com.google.inject.servlet.ServletDefinition.doServiceImpl(ServletDefinition.java:286) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.ServletDefinition.doService(ServletDefinition.java:276) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.ServletDefinition.service(ServletDefinition.java:181) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.ManagedServletPipeline.service(ManagedServletPipeline.java:91) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:85) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.ManagedFilterPipeline.dispatch(ManagedFilterPipeline.java:120) ~[guice-servlet-4.1.0.jar:?] at com.google.inject.servlet.GuiceFilter.doFilter(GuiceFilter.java:135) ~[guice-servlet-4.1.0.jar:?] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.server.http.RedirectFilter.doFilter(RedirectFilter.java:73) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.server.security.PreResponseAuthorizationCheckFilter.doFilter(PreResponseAuthorizationCheckFilter.java:82) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.server.security.AllowHttpMethodsResourceFilter.doFilter(AllowHttpMethodsResourceFilter.java:78) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.server.security.AllowOptionsResourceFilter.doFilter(AllowOptionsResourceFilter.java:75) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.security.basic.authentication.BasicHTTPAuthenticator$BasicHTTPAuthenticationFilter.doFilter(BasicHTTPAuthenticator.java:208) ~[?:?] at org.apache.druid.server.security.AuthenticationWrappingFilter.doFilter(AuthenticationWrappingFilter.java:59) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.apache.druid.server.security.SecuritySanityCheckFilter.doFilter(SecuritySanityCheckFilter.java:77) ~[druid-server-0.22.1.jar:0.22.1] at org.eclipse.jetty.servlet.FilterHolder.doFilter(FilterHolder.java:193) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler$Chain.doFilter(ServletHandler.java:1601) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:548) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:233) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:1624) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:233) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1435) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:188) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:501) ~[jetty-servlet-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:1594) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:186) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1350) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:141) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.gzip.GzipHandler.handle(GzipHandler.java:763) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.HandlerList.handle(HandlerList.java:59) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:127) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.Server.handle(Server.java:516) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.HttpChannel.lambda$handle$1(HttpChannel.java:388) ~[jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.HttpChannel.dispatch(HttpChannel.java:633) [jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:380) [jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:277) [jetty-server-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:311) [jetty-io-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:105) [jetty-io-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.io.ChannelEndPoint$1.run(ChannelEndPoint.java:104) [jetty-io-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.runTask(EatWhatYouKill.java:336) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.doProduce(EatWhatYouKill.java:313) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.tryProduce(EatWhatYouKill.java:171) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.run(EatWhatYouKill.java:129) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.ReservedThreadExecutor$ReservedThread.run(ReservedThreadExecutor.java:383) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:882) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.run(QueuedThreadPool.java:1036) [jetty-util-9.4.40.v20210413.jar:9.4.40.v20210413] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_275] // ...
Druid STRING columns are reported as VARCHAR. Can include multi-value strings as well.
DECIMAL
DOUBLE
0.0
DECIMAL uses floating point, not fixed point math
FLOAT
FLOAT
0.0
Druid FLOAT columns are reported as FLOAT
REAL
DOUBLE
0.0
DOUBLE
DOUBLE
0.0
Druid DOUBLE columns are reported as DOUBLE
BOOLEAN
LONG
false
TINYINT
LONG
0
SMALLINT
LONG
0
INTEGER
LONG
0
BIGINT
LONG
0
Druid LONG columns (except __time) are reported as BIGINT
TIMESTAMP
LONG
0, meaning 1970-01-01 00:00:00 UTC
Druid’s __time column is reported as TIMESTAMP. Casts between string and timestamp types assume standard SQL formatting, such as 2000-01-02 03:04:05, not ISO 8601 formatting. For handling other formats, use one of the time functions.
DATE
LONG
0, meaning 1970-01-01
Casting TIMESTAMP to DATE rounds down the timestamp to the nearest day. Casts between string and date types assume standard SQL formatting—for example, 2000-01-02. For handling other formats, use one of the time functions.
ARRAY
ARRAY
NULL
Druid native array types work as SQL arrays, and multi-value strings can be converted to arrays. See Arrays for more information.
OTHER
COMPLEX
none
May represent various Druid column types such as hyperUnique, approxHistogram, etc.