ZooKeeper 原理与优化
ZooKeeper 是什么?
ZooKeeper 是一个基于 Google Chubby 论文实现的一款解决分布式数据一致性问题的开源实现,方便了依赖 ZooKeeper 的应用实现 数据发布 / 订阅、负载均衡、服务注册与发现、分布式协调、事件通知、集群管理、Leader 选举、 分布式锁和队列 等功能
基本概念
集群角色
一般的,在分布式系统中,构成集群的每一台机器都有自己的角色,最为典型的集群模式就是 Master / Slave 主备模式。在该模式中,我们把能够处理所有写操作的机器称为 Master 节点,并把所有通过异步复制方式获取最新数据、提供读服务的机器称为 Slave 节点
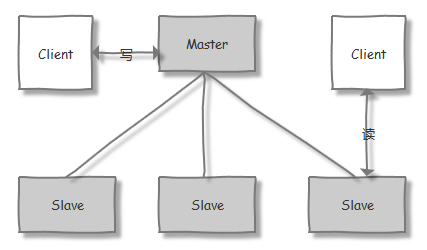
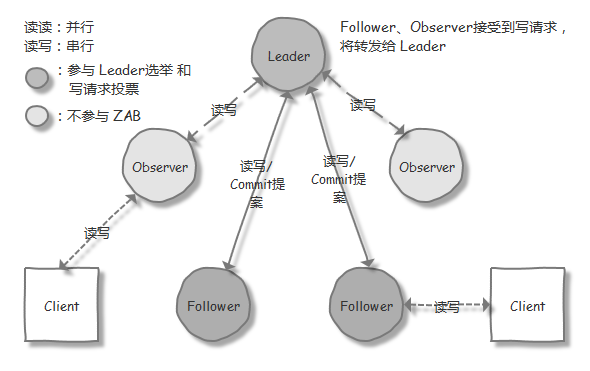
而 ZooKeeper 中,则是引入了 领导者(Leader)、跟随者(Follower)、观察者(Observer) 三种角色 和 领导(Leading)、跟随(Following)、观察(Observing)、寻找(Looking) 等相应的状态。在 ZooKeeper 集群中的通过一种 Leader 选举的过程,来选定某个节点作为 Leader 节点,该节点为客户端提供读和写服务。而 Follower 和 Observer 节点,则都能提供读服务,唯一的区别在于,Observer 机器不参与 Leader 选举过程 和 写操作的"过半写成功"策略,Observer 只会被告知已经 commit 的 proposal。因此 Observer 可以在不影响写性能的情况下提升集群的读性能(详见下文 “性能优化 - 优化策略 - Observer 模式” 部分)
会话
Session 指客户端会话。在 ZooKeeper 中,一个客户端会话是指 客户端和服务器之间的一个 TCP 长连接。客户端启动的时候,会与服务端建立一个 TCP 连接,客户端会话的生命周期,则是从第一次连接建立开始算起。通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,并向 ZooKeeper 服务器发送请求并接收响应,以及接收来自服务端的 Watch 事件通知
Session 的 sessionTimeout 参数,用来控制一个客户端会话的超时时间。当服务器压力太大 或者是网络故障等各种原因导致客户端连接断开时,Client 会自动从 ZooKeeper 地址列表中逐一尝试重连(重试策略可使用 Curator 来实现)。只要在 sessionTimeout 规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。如果,在 sessionTimeout 时间外重连了,就会因为 Session 已经被清除了,而被告知 SESSION_EXPIRED,此时需要程序去恢复临时数据;还有一种 Session 重建后的在新节点上的数据,被之前节点上因网络延迟晚来的写请求所覆盖的情况,在 ZOOKEEPER-417 中被提出,并在该 JIRA 中新加入的 SessionMovedException,使得 用同一个 sessionld/sessionPasswd 重建 Session 的客户端能感知到,但是这个问题到 ZOOKEEPER-2219 仍然没有得到很好的解决
![]()
数据模型
在 ZooKeeper 中,节点分为两类,第一类是指 构成集群的机器,称之为机器节点;第二类则是指 数据模型中的数据单元,称之为数据节点 ZNode。ZooKeeper 将所有数据存储在内存中,数据模型的结构类似于树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个 ZNode,例如 /foo/path1。每个 ZNode 上都会保存自己的数据内容 和 一系列属性信息
ZNode 可以分为持久节点(PERSISTENT)和临时节点(EPHEMERAL)两类。所谓持久节点是指一旦这个 ZNode 被创建了,除非主动进行移除操作,否则这个节点将一直保存在 ZooKeeper 上。而临时节点的生命周期,是与客户端会话绑定的,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。在 HBase 中,集群则是通过 /hbase/rs/* 和 /hbase/master 两个临时节点,来监控 HRegionServer 进程的加入和宕机 和 HMaster 进程的 Active 状态
另外,ZooKeeper 还有一种 顺序节点(SEQUENTIAL)。该节点被创建的时候,ZooKeeper 会自动在其子节点名上,加一个由父节点维护的、自增整数的后缀(上限:Integer.MAX_VALUE)。该节点的特性,还可以应用到 持久 / 临时节点 上,组合成 持久顺序节点(PERSISTENT_SEQUENTIAL) 和 临时顺序节点(EPHEMERAL_SEQUENTIAL)
版本
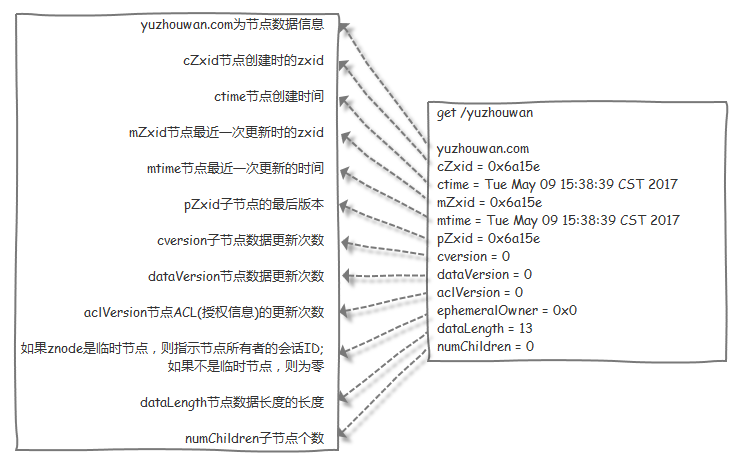
ZooKeeper 的每个 ZNode 上都会存储数据,对应于每个 ZNode,ZooKeeper 都会为其维护一个叫做 Stat 的数据结构,Stat 中记录了这个 ZNode 的三个数据版本,分别是 version(当前 ZNode 数据内容的版本),cversion(当前 ZNode 子节点的版本)和 aversion(当前 ZNode 的 ACL 变更版本)。这里的版本起到了控制 ZooKeeper 操作原子性的作用(详见下文 “源码分析 - 落脚点 - ZooKeeper 乐观锁” 部分)
如果想要让写入数据的操作支持 CAS,则可以借助 Versionable#withVersion 方法,在 setData() 的同时指定当前数据的 verison。如果写入成功,则说明在当前数据写入的过程中,没有其他用户对该 ZNode 节点的内容进行过修改;否则,会抛出一个 KeeperException.BadVersionException,以此可以判断本次 CAS 写入是失败的。而这样做的好处就是,可以避免“并发局部更新 ZNode 节点内容”时,发生相互覆盖的问题
Watcher
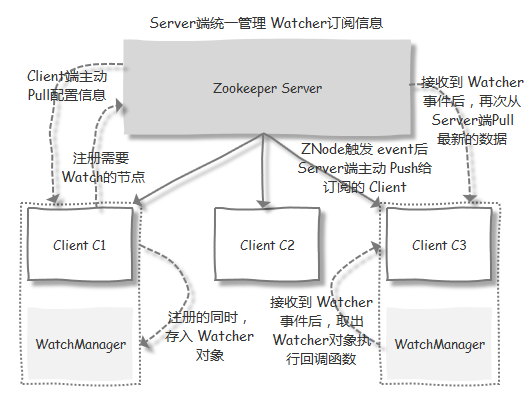
Watcher(事件监听器)是 ZooKeeper 提供的一种 发布/订阅的机制。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知给订阅的客户端。该机制是 ZooKeeper 实现分布式协调的重要特性
ACL
类似于 Unix 文件系统,ZooKeeper 采用 ACL(Access Control Lists)策略来进行权限控制(使用方式,详见下文 “常用命令 - 执行脚本 - zkCli - 节点操作” 部分;代码实现,详见 PrepRequestProcessor#checkACL)
常用的权限控制
| Command | Comment |
|---|---|
| CREATE (c) | 创建子节点的权限 |
| READ (r) | 获取节点数据和子节点列表的权限 |
| WRITE (w) | 更新节点数据的权限 |
| DELETE (d) | 删除当前节点的权限 |
| ADMIN (a) | 管理权限,可以设置当前节点的 permission |
| Scheme | ID | Comment |
|---|---|---|
| world | anyone | ZooKeeper 中对所有人有权限的结点就是属于 world:anyone |
| auth | 不需要 id | 通过 authentication 的 user 都有权限 |
(ZooKeeper 支持通过 kerberos 来进行 authencation,也支持 username/password形式的 authentication) |
||
| digest | username:BASE64 (SHA1(password)) | 需要先通过 username:password 形式的 authentication |
| ip | id 为客户机的 IP 地址(或者 IP 地址段) | ip:192.168.1.0/14,表示匹配前 14 个 bit 的 IP 段 |
| super | 对应的 id 拥有超级权限(CRWDA) |
IP
编码
1 |
|
Tips: Full code is here.
命令行
1 | $ zkCli.sh -server localhost:2181 |
1 | $ zkCli.sh -server 127.0.0.1:2181 |
优缺点
简单易用,直接在物理层面,对用户进行权限隔离;但是,如果不将 127.0.0.1 放入到 IP Acl 列表里,会给服务端的运维带来麻烦
Digest
编码
1 |
|
Tips: Full code is here.
命令行
1 | $ zkCli.sh -server localhost:2181 |
优缺点
可以建立角色,按照用户名、密码进行权限控制;但是,想要修改某个用户的密码,需要对所有的 ACLs 做更改
SASL & Kerberos
环境搭建
单机版
安装
1 | $ cd ~/install/ |
配置
1 | $ cd zookeeper |
启动
1 | $ bin/zkServer.sh start |
容器版
1 | $ docker run --restart always -p 2181:2181 -p 2888:2888 -p 3888:3888 -p 8080:8080 -d zookeeper |
集群版
1 | # 更多配置,详见下文 “常用配置” 部分 |
常用命令
四字命令
| Command | Comment |
|---|---|
| conf | 输出相关服务配置的详细信息 |
| cons | 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息(包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息) |
| envi | 输出关于服务环境的详细信息 (区别于 conf 命令) |
| dump | 列出未经处理的会话和临时节点 |
| stat | 查看哪个节点被选择作为 Follower 或者 Leader |
| ruok | 测试是否启动了该 Server,若回复 imok 表示已经启动 |
| mntr | 输出一些运行时信息(latency / packets / alive_connections / outstanding_requests / server_state / znode + watch + ephemerals count …) |
| reqs | 列出未经处理的请求 |
| wchs | 列出服务器 watch 的简要信息 |
| wchc | 通过 session 列出服务器 watch 的详细信息(输出是一个与 watch 相关的会话的列表) |
| wchp | 通过路径列出服务器 watch 的详细信息(输出一个与 session 相关的路径) |
| srvr | 输出服务的所有信息(可以用来检查当前节点同步完毕集群数据,处于 Follower 状态) |
| srst | 重置服务器统计信息 |
| kill | 关掉 Server |
使用方式
安装 Netcat
1 | # online |
Netcat 执行
1 | $ echo <four-letter command> | nc 127.0.0.1 2181 |
DOS 攻击
1 | # 避免 wchp / wchc 四字命令被 DOS 攻击利用 |
产生的日志
1 | # 可以看到 zk.out 文件中出现 0:0:0:0:0:0:0:1(IPv6 的回送地址,相当于 IPv4 的 127.0.0.1)和 Processing xxxx command 相应的日志 |
执行脚本
zkServer
启动
1 | # 启动 |
排查问题
1 | # 可以通过增加 `start-foreground` 参数来排查失败原因 |
zkCli
启动
1 | $ cd $ZOOKEEPER_HOME |
节点操作
| Command | Example | Comment |
|---|---|---|
| create | 创建一个节点 | |
| ls | 查看当前节点数据 | |
| set | 修改节点 | |
| get | 得到一个节点,包含数据和更新次数等信息 |
|
| delete | 删除一个节点 | |
| deleteall | 递归删除 | |
| history | 列出最近的历史命令 | |
redo <command number: n> |
redo 1 | 重做第 n 步命令 |
| stat | 打印节点状态 | |
| close | 关闭当前连接 | |
connect <host>:<port> |
connect localhost:2181 | 当 close 当前连接或者意外退出后,可在 zkCli 命令模式中重连 |
| quit | 退出当前连接 | |
setAcl <path> <acl: scheme + id + permissions> |
setAcl /zk world:anyone:cdrw | 设置节点权限策略(详见上文 “基本概念 - ACL” 部分) |
getAcl <path> |
获取节点权限策略 | |
addauth <scheme> <auth> |
addauth digest username:password | 节点权限认证 |
| setquota -n | -b val <path> |
|
listquota <path> |
listquota /zookeeper | 查看节点的配额 |
| count=5, bytes=-1 | /zookeeper 节点个数限额为 5,长度无限额 | |
delquota [-n or -b] <path> |
||
sync <path> |
强制同步 | |
(由于“过半原则”,导致某些 ZooKeeper Server 上的数据是旧的,用 sync 命令可强制同步所有的更新操作) |
||
| printwatches on | off |
常见组合(for Kafka)
| Command | Comment |
|---|---|
get /consumers/<topic>/owners |
查看 Topic 实时消费的 Group ID |
get /consumers/<topic>/offsets/<group id>/<partitionor> |
查看 Offset 情况(ctime:创建时间;mtime:修改时间) |
常用配置
dataDir
ZooKeeper 保存服务器存储快照文件的目录,默认情况,ZooKeeper 将 写数据的日志文件也保存在这个目录里(default:/tmp/zookeeper)
dataLogDir
用来存储服务器事务日志
clientPort
客户端连接 ZooKeeper 服务器的端口,ZooKeeper 会监听这个端口,接受客户端的访问请求(default:2181)
tickTime(SS / CS)
用来指示 服务器之间或客户端与服务器之间维护心跳机制的 最小时间单元,Session 最小过期时间默认为两倍的 tickTime(default:2000ms)
initLimit(LF)
集群中的 Leader 节点和 Follower 节点之间初始连接时能容忍的最多心跳数(default:5 tickTime)
syncLimit(LF)
集群中的 Leader 节点和 Follower 节点之间请求和应答时能容忍的最多心跳数(default:2 tickTime)
minSessionTimeout & maxSessionTimeout
默认分别是 2 * tickTime ~ 20 * tickTime,来用控制 客户端设置的 Session 超时时间。如果超出或者小于,将自动被服务端强制设置为 最大或者最小
maxClientCnxns
控制单个客户端(以 IP 地址为唯一标识)创建连接数的上限(default:60),设置为 0 则不作限制
集群节点
配置 ZooKeeper 集群中的服务器节点
格式:server.<myid>=<服务器地址>:<LF通讯端口>:<选举端口>
样例:server.1=yuzhouwan:2888:3888
动态配置
1 | $ vim zoo_replicated1.cfg |
监控
采集方式
JMX
远程连接
ZooKeeper 默认支持 JMX 连接,但是只支持本地连接
1 | # 开启远程 JMX |
Four-letter command
TCP Dump
1 | # 使用 tcpdump 命令,需要在 root 权限下执行 |
Tips: 比较关心的一个问题是,tcpdump 是否会对性能造成影响?答案是:会的。当过滤上千的 IP 时,已经会影响到服务器性能。主要瓶颈在 BPF Filter,这是一个 $O(n)$ 线性时间复杂度的算法,可以考虑 HiPAC 多维树匹配 替代
指标
ZooKeeper 运行状态(mntr)
| Metrics | Comment | Threshold |
|---|---|---|
| zk_version | 版本 | |
| zk_avg_latency | 平均 响应延迟 | > 50ms,比上次统计增长超过 20ms,且上一次延迟不为 0 |
| zk_max_latency | 最大 响应延迟 | |
| zk_min_latency | 最小 响应延迟 | |
| zk_packets_received | 收包数 | |
| zk_packets_sent | 发包数 | |
| zk_num_alive_connections | 活跃连接数 | > 3000 |
| zk_outstanding_requests | 堆积请求数 | 连续两次大于 5(粒度:1min) |
| zk_server_state | 主从状态 | 由 Leader 变为 Follower 或 由 Follower 变为 Leader |
| zk_znode_count | znode 数 | > 40000 |
| zk_watch_count | watch 数 | > 50000 |
| zk_ephemerals_count | 临时节点数 | |
| zk_approximate_data_size | 近似数据总和大小 | |
| zk_open_file_descriptor_count | 打开 文件描述符 数 |
|
| zk_max_file_descriptor_count | 最大 文件描述符 数 |
|
| zk_followers | Follower 数 | |
| zk_synced_followers | 已同步的 Follower 数 | 连续两次检测到未同步的 Follower 节点 (粒度:1min) |
| zk_pending_syncs | 阻塞中的 sync 操作 |
实时预警
numenta / nupic
NuPIC(Numenta Platform for Intelligent Computing,Numenta智能计算平台) 是一个与众不同的开源人工智能平台,它基于一种脑皮质学习算法,即 “层级实时记忆”(Hierarchical Temporal Memory,HTM)。该算法旨在模拟新大脑皮层的工作原理,将复杂的问题转化为模式匹配与预测,而传统的 AI 算法大多是针对特定的任务目标而设计的
NuPIC 聚焦于分析实时数据流,可以通过学习数据之间基于时间的状态变化(而非阀值设置),对未知数据进行预测,并揭示其中的非常规特性。详见我的另一篇博客:人工智能
性能调优
Benchmark
brownsys / zookeeper-benchmark (很难找到合适的开源项目,需自己编写 Benchmark 工具)
优化策略
部署
日志目录
- 快照目录 dataDir 和 事务日志目录 dataLogDir 分离
- 写事务日志的目录,需要保证目录空间足够大,并挂载到单独的磁盘上(为了保证
数据的一致性,ZooKeeper 在返回客户端事务请求响应之前,必须要将此次请求对应的事务日志刷入到磁盘中 [forceSync 参数控制,default:yes],所以事务日志的写入速度,直接决定了 ZooKeeper 的吞吐率)
自动日志清理
autopurge.purgeInterval
指定清理频率,单位为小时(default:0 表示不开启自动清理)
autopurge.snapRetainCount
和上面 purgeInterval 参数配合使用,指定需要保留的文件数目(default:3)
1 | $ vim conf/zoo.cfg |
Log4j 滚动日志
1 | $ cd $ZOOKEEPER_HOME |
Observer 模式
作用
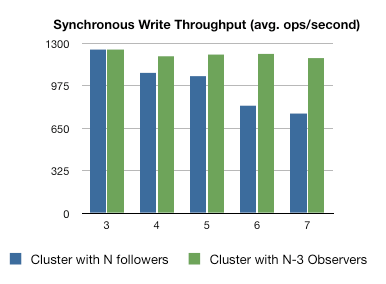
对读请求进行扩展
通过增加更多的 Observer,可以接收更多的读请求流量,却不会牺牲写操作的吞吐量(写操作的吞吐量取决于 quorum 法定人数的个数)
如果增加更多的 Server 进行投票,Quorum 会变大,这会降低写操作的吞吐量
然而增加 Observer 并不会完全没有损耗,新的 Observer 在提交一个事务后收到一条额外的 INFORM 消息。这个损耗比加入 Follower 进行投票来说会小很多
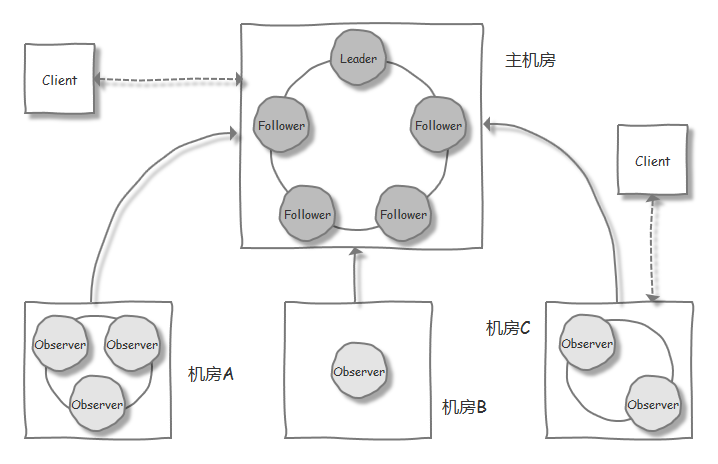
跨数据中心部署
把 participant 分散到多个数据中心,可能会因为数据中心之间的网络延迟,导致系统被拖慢
使用 Observer 的话,更新操作都在单独的数据中心来处理,再发送到其他数据中心,让 Client 消费数据(分布式数据库[中美异地机房]同步系统 Otter 就使用该模式)
设置
1 | $ vim conf/zoo.cfg |
INFORM 消息
因为 Observer 不参与到 ZAB 选举中,所以 Leader 节点不会发送 proposal 给 Observer,只会发送一条包含已经通过选举的 zxid 的 INFORM 消息。这里,参与 ZAB 选举的 Leader、Follower 节点称之为 PARTICIPANT Server,而 Observer 则属于 OBSERVER Server
配置
JVM 相关
swappiness
1 | $ cd $ZOOKEEEPER_HOME |
升级 JDK8
为何建议升级 JDK8 呢?因为 ZooKeeper 里面很多关键的功能点,都用到了 Atomic 类,而该类在 JDK8 中做了一次升级,性能提升了 6x 倍(JDK8 中加入了 Unsafe.getUnsafe().getAnd[Add|Set][Int|Long|Object] 一系列方法对 Atomic 类做了增强,由于无法看到 Oracle JDK 里 Unsafe 的相关实现,有兴趣可以参考 OpenJDK 源码。目前,存在一种比较靠谱的猜测是,compare-and-swap 被替换成系统底层的 fetch-and-add,后者用 lock xadd 替代了 lock cmpxchg 来实现原子操作。其中 指令前缀 lock 用来锁定指令涉及的存储区域,xadd 指令作用是 交换两个操作数的值,再进行加法操作,cmpxchg 比较交换指令,第一操作数先和 AL/AX/EAX 比较,如果相等 ZF 置 1,第二操作数赋给第一操作数,否则 ZF 清 0,第一操作数赋给 AL/AX/EAX。由此可见,xadd 指令实现的 FAA 和 cmpxchg 指令实现的 CAS 相比,并没有自旋,因此不用担心循环时间过长之后 CPU 资源消耗过大,并且也没有了 CAS 中 ABA 之类的问题 [该问题在 AtomicStampedReference 中,通过增加版本号解决了])
1 | // 源码 |
1 | ## 汇编 |
1 | ## 指令 |
Tips: 这里 CAS 还有一个预测分支的损耗,有兴趣可以进一步研究一个问题:为何有序数组的 for 循环遍历,会比无序数组快,以及如何解决?
截止本文编写时间 2017-6-20 (master:111ae5a),一共有 70 个 Atomic 实例在 ZooKeeper 中被初始化并使用
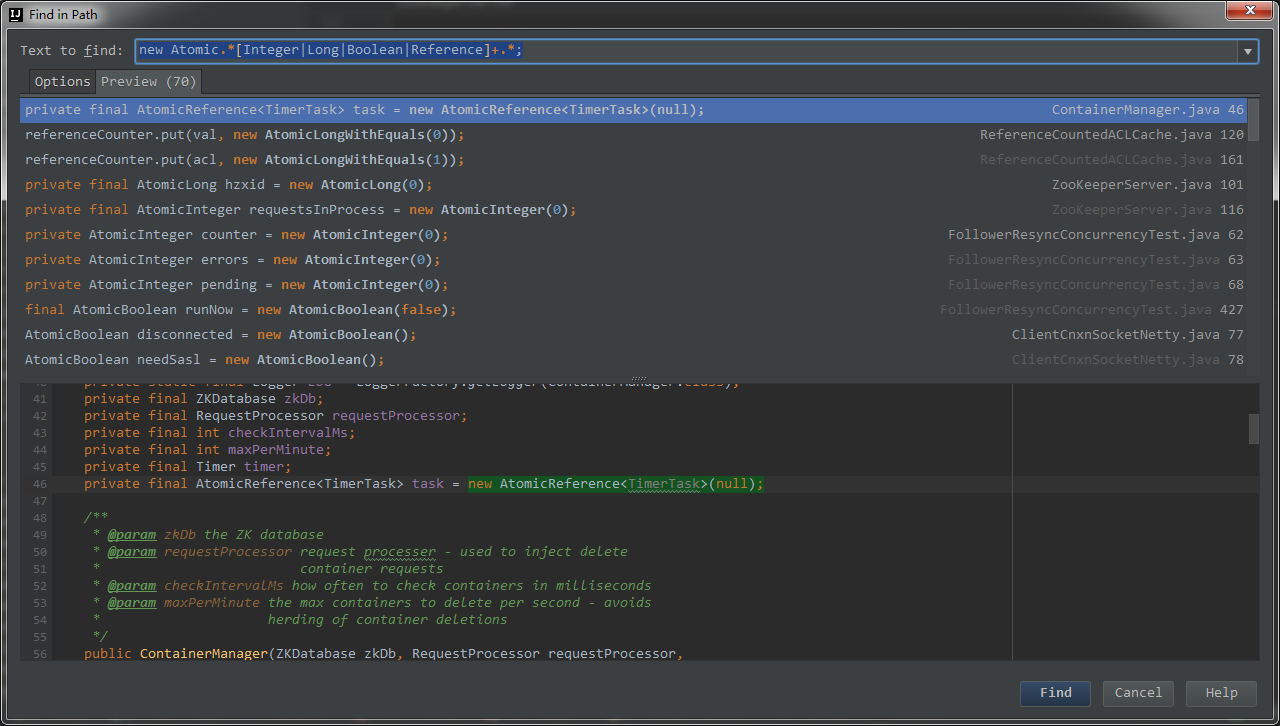
G1GC
在不牺牲吞吐性能的前提下,G1GC 并能更好地控制 GC 的停顿时间,因此非常合适 ZooKeeper 这类需要控制心跳超时时间(tickTime)的服务
在多处理器和大容量内存的环境下,能更快速地整理空闲空间,避免产生过多的内存碎片
这里只罗列一些常用的配置和特定情况下,需要调整的参数,具体调整到多少才算最佳,还是需要依据 ZooKeeper 具体的使用场景、Beachmark 的结果和 GC 日志的分析
| Params | Meaning | Comment |
|---|---|---|
| -XX:+UseG1GC | 使用 G1GC | |
| -XX:G1HeapRegionSize=4m | 设置内存分块的大小(1MB~32MB) | 当系统中存在大量大对象的时候,大的 Region 会提升 GC 效率 |
| -XX:MaxGCPauseMillis=200(ms) | 此值为建议 JVM 的最长暂停时间 |
只是建议值,G1GC 只能尽量保证,而无法完全保证 |
| -XX:InitiatingHeap OccupancyPercent=45 | 设置使用了整个堆的 n% 时,系统开始进行并行 GC |
注意是整个堆的百分比。这与 CMS 收集器的类似参数不同 |
| -XX:ParallelGCThreads=n | 设置 STW 工作线程数的值 | 默认线程数由 CPU 数量决定,通常小于逻辑处理器的个数 m |
| m<=8: $n=m$; | ||
| m>8 & system!=SPARC: $n\approx5/8*m$; | ||
| m>8 & system=SPARC: $n\approx5/16*m$ | ||
| 当有较大的 Update RSet 时间时,可以尝试调整此值 | ||
| -XX:ConcGCThreads=n | 设置并行标记的线程数 | mixed GC 情况下,较长的 cycle start 时间,可以尝试调整此值 |
| $n\approx1/4 * ParallelGCThreads$ | ||
| -XX:+ParallelRefProcEnabled | 当看到有较长的 Ref Proc 建议配置此值 | CMS 收集器和 G1 收集器均有这个问题。配置以后暂停明显缩小 |
LongAdder
考虑使用 LongAdder(author:Doug Lea)替代 AtomicLong,以提高效率,下面用 100 个线程去 increment 计算 1kw 次,发现效率大致相差 6 倍(已提交 jira 欢迎讨论)
1 | // -Xmx512M -Xms512M -Xmn256M -XX:+AlwaysPreTouch -ea |
下面从源码的角度来分析,首先 LongAdder 继承于 Striped64 类,实现了类似 AtomicLong 的一些 add / increment / decrement / sum / longValue 等方法
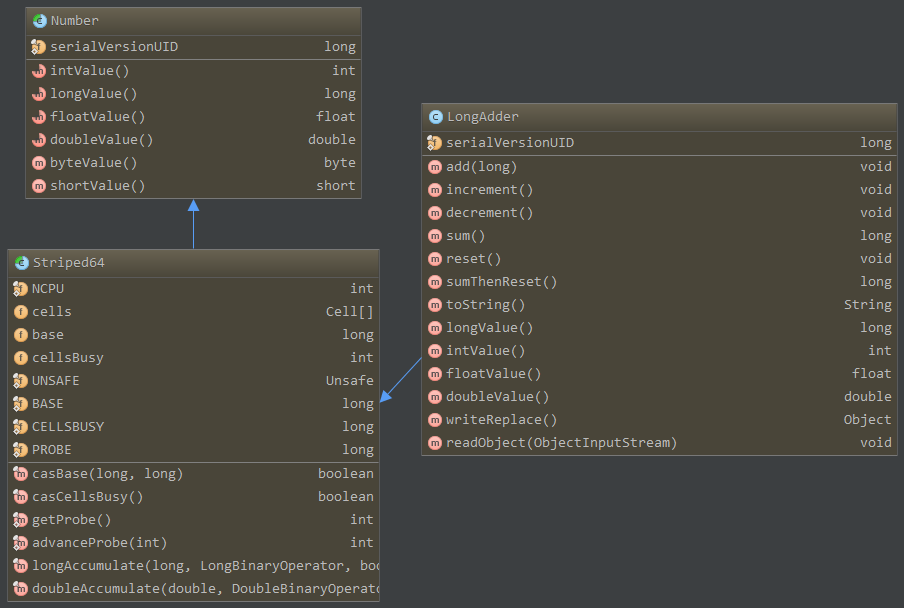
分析 LongAdder 里面最为核心的一个 add 方法
1 | /** |
可以看到里面用到了一个 java.util.concurrent.atomic.Striped64.Cell 类,作为最终存放数据的地方,比较特别是,这里是一个数组,而不是 AtomicLong 里面看到的 volatile long 变量,并且 Cell[] 数组的长度是以 2 的指数级进行增长的,到这里多少可以看出 LongAdder 有点想以空间换时间的端倪了。之所以是用 Cell[] 数组,是考虑到可以将更新操作分而治之,不必对单一变量进行竞争,而是将压力均分到整个数组里面,这样如果需要得到 LongAdder 的值,只需要做一次 sum 操作
并且,看 add 方法的第一个 if 分支,cells 是一个 lazy init 的变量,也就是只要是在单线程无并发的场景下,就会直接调用 casBase 方法完成 CAS 赋值并返回。如此一来,可以节省下创建数组带来的资源消耗。那么,如果在多线程并发的场景下,casBase 执行失败,则会进行第二个 if 分支的判断,这样就可以发挥 Cell[] 的作用了(AtomicLong 中则是用 while 循环不断进行尝试)。此时 Cell[] as 尚未初始化,因此会进入到 if 分支内,执行 longAccumulate 方法
1 | /** |
longAccumulate 会首先调用 getProbe 方法获取一个 Probe 当前线程的探测值(利用 java.util.concurrent.ThreadLocalRandom#getProbe 返回随机整数值),因为 Probe 值是通过反射 Thread 类的 threadLocalRandomProbe 变量获取的,而 threadLocalRandomProbe 也是 lazy init,所以如果为 int 默认值 0 的时候,需要用 ThreadLocalRandom.current() 方法进行强制初始化(此处用的是 mix64 伪随机数算法,该算法由 Austin Appleby 于 08 年提出的 MurmurHash3 算法的一种变种实现,可以说已经统一了整个伪随机领域,在 Redis、Memcached、Cassandra、HBase、Lucene 和 Elasticsearch 等各大流行框架中看到 MurmurHash 的身影,具体可参考 Doug Lea 的《Fast Splittable Pseudorandom Number Generators》论文)
随后进入 for (;;) 死循环,这时候会先判断 Cell[] 数组是否为空、长度是否大于 0,如果 Cell[] 未完成初始化,则会去判断 cellsBusy 自旋锁是否为 0,来控制 Cell[] 创建和 resize 大小时的原子性。如果自旋锁为 0,则将其通过 casCellsBusy() 方法设置为 1,之后完成初始化工作并将 cellsBusy 重置为 0(默认 Cell[] 的 size 为 2)
完成 Cell[] 数组初始化之后,会进入 for (;;) 死循环的第一个 if 分支,计算 as[(n - 1) & h] = as[(2 - 1) & -217768167] = as[1] 获取到一个随机 Cell 是否为空;如果 Cell 为空,则新建 Cell(x) 存入到 Cell[] 的空槽位中;如果 Cell 不为空,则进一步判断 wasUncontended 参数是否为 false,如果是,则说明是预料到可能的冲突,则置为 true 继续尝试新的 Cell;下一个分支 a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))) 则是进行对应的操作,这里 fn 为空,则执行 + 累加操作;接下来的一个分支 n >= NCPU || cells != as 则是考虑到 Cell[] 的长度对比操作系统的 可用虚拟 CPU 核数 和 并发竞争的激烈程度,来判断是否碰撞严重,并和下一个分支一起控制 collide 变量来做标示;最后一个 if 分支 cellsBusy == 0 && casCellsBusy(),如果到了这里,仍然没有完成 add() 方法的执行,说明需要通过扩展一倍的 Cell[] 数组来满足当前的并发量,之后再次重试,然后会不出意外地落入 a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))) 第三个 if 分支中,最终完成 add() 方法
1 | /** |
总结:
高并发处理能力
从架构的角度来说,
AtomicLong中使用的是单一变量volatile long,而在LongAdder中使用的是Cell[],这可以将并发的压力分摊到整个数组上,而非单个变量,可以更加得心应手地处理高并发的场景低资源消耗
Cell[]数组是延迟初始化的,并且在扩容的操作,是在考虑到 CPU 的核数(即机器的处理能力)和数组操作的碰撞次数(即并发的激烈程度)之后才会发生,尽可能地优化了资源的使用率更为高效的汇编指令
使用的是
lock xadd而非lock cmpxchg指令来实现原子操作的,避免了 CAS 的 ABA、高并发下不断自旋 导致的 CPU 资源消耗过大、预测分支失败等问题
ZooKeeper 相关
leaderServes
zookeeper.leaderServes 参数用于控制,Leader 节点是否可以被 Client 端连接,默认值为 yes
理论上 Leader 可以处理所有 Client 的读写请求,但是在 ZooKeeper 的架构设计中,Leader 的主要作用来对事务更新请求以及集群本身的运行时协调
所以,设置成 no,可使得 Leader 节点不接受 Client 端的连接请求,以提高分布式协调能力
jute.maxbuffer
jute.maxbuffer 参数用于控制,单个 ZNode 上最大可以存储的数据量,默认值为 1048575(1M - 1, 由BinaryInputArchive.maxBuffer 变量控制)
因为 ZooKeeper 旨在存储大小为千字节(1KB)的数据,因此通常情况下,需要下调这个阀值
需要注意的是,该参数并不是在 Server 和 Client 端同时设置才会生效。实际情况是,在客户端设置后,ZooKeeper 将控制从 Server 端读取数据的大小(outgoingBuffer);而在服务端设置后,则是控制从 Client 端写入数据的大小(incomingBuffer)
换句话说,如果 Server 端不设置 maxbuffer,单 ZNode 结点最大可能的写入数据量为 $1024 \cdot 1024 - 42$ $= 1048534$。因为,在数据量达到 1M 的默认限制之前,会因为 org.apache.zookeeper.server.NIOServerCnxn#readLength 中的查看 buffer size 时,lenBuffer.getInt() 的调用就已经抛出了 BufferUnderflowException 了。而如果 Client 端不设置 maxbuffer,将不会对从 Server 端读取到的数据包大小做限制。但是,如果设置了,例如 maxbuffer=1024,但是其实 Client 最大能拿到的数据包大约只有 $1024 - 88 = 936$,因为除了数据本身,还包含了 ReplyHeader(xid/zxid/err, 例如 1,3274,0\n,一般占 9 字节)、Record(Stat,例如 s{2,2,1495790235732,1495790235732,0,2874,0,0,0,0,3273}\n),一般占 55 字节、Tag,例如 response,一般占 8 字节 等其他序列化信息
1 | # 设置 Client 端 |
globalOutstandingLimit
zookeeper.globalOutstandingLimit 参数用于控制,服务器最大请求堆积量,默认值为 1000
为防止服务端资源(内存、CPU、网络)被耗尽,根据服务器最大处理能力,可做适当调整
snapCount & preAllocSize
zookeeper.snapCount 参数用于控制,两次快照之间事务操作的次数,默认值为 100,000
zookeeper.preAllocSize 参数用于控制,事务日志文件预分配磁盘的大小,默认值为 65536KB(64MB)
两个参数配合设置,可以依据特定业务场景下的事务操作数据量 transactionDataSize,按照 $snapCount * transactionDataSize \ge preAllocSize$ 公式进行适当调整
zookeeper.serverCnxnFactory & zookeeper.clientCnxnSocket
在 3.5 版本之后,默认使用 Netty,在此之前的版本,ZooKeeper 支持将默认使用的 NIO,替代为 Netty。通过在服务端和客户端分配配置以下两个配置项
zookeeper.serverCnxnFactory 设置为 org.apache.zookeeper.server.NettyServerCnxnFactory
zookeeper.clientCnxnSocket 设置为 org.apache.zookeeper.ClientCnxnSocketNetty
源码分析
源码环境搭建
下载源码
1 | # 基于 branch-3.4 进行分析 |
下载安装 Ant
- Download: apache-ant-1.9.9-bin.tar.gz
- 安装并设置环境变量
执行 Ant 命令
编译出 IDE 可识别的环境
1 | $ cd %ZOOKEEPER_SOURCE_PATH% |
二次开发后,进行本地测试
1 | # 优先编写 JUnit TestCase 进行测试,随后再利用 `ant test-core` 进行一次整体的测试 |
打包编译
1 | $ ant clean tar -Dbuild.compiler=javac1.7 |
运行 ZooKeeperServerMain
1 | # 配置 Program arguments |
遇到的坑
下载依赖超时
1 | $ vim build.xml |
PowerMock 测试 TestingServer 报错 ClassCastException
描述
1 | 17:32:55.821 [Thread-1] ERROR o.a.c.test.TestingZooKeeperServer - From testing server (random state: false) for instance: InstanceSpec{dataDirectory=/var/folders/4z/h5ftkmm90vg5s7j0kv65j0gw0000gp/T/1542274365502-0, port=2181, electionPort=64470, quorumPort=64471, deleteDataDirectoryOnClose=true, serverId=1, tickTime=-1, maxClientCnxns=-1, customProperties={}, hostname=127.0.0.1} org.apache.curator.test.InstanceSpec@59c3be02 |
分析
因为 Mock 使用自定义 ClassLoader 来完成字节码修改,而对于一些需要使用系统原生 ClassLoader的类,则需要通过 @PowerMockIgnore 注解来显式地告知 Mock 框架跳过它们
解决
1 | @RunWith(PowerMockRunner.class) |
选主机制
ZAB 选主流程
ZooKeeper 提供的选主算法
ZooKeeper 提供了 LeaderElection / FastLeaderElection(UDP) / AuthFastLeaderElection(UDP) / FastLeaderElection(TCP) 这四种选主算法(初始化 QuorumPeer 时需指定到 electionAlg 参数),前三种策略因为 UDP 的不可靠性和 LE 中被选举的 Leader 故障会导致无休止的选举等问题,在 v3.4.0 开始被废弃
Vote 数据结构

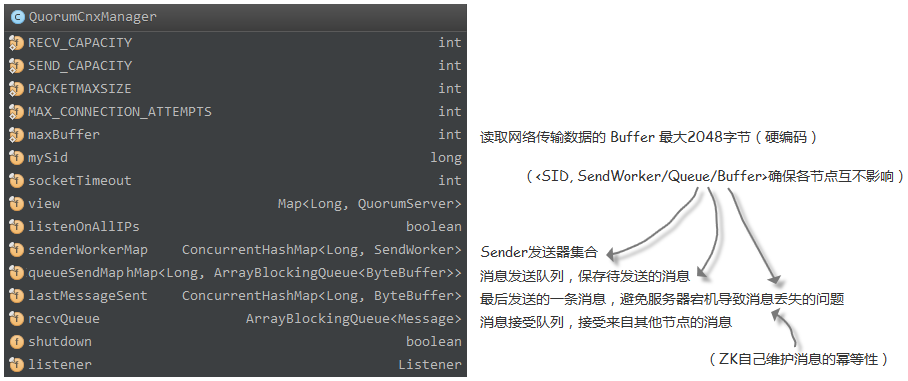
QuorumCnxManager 网络通讯
QuorumCnxManager 起到管理 Election 过程中网络连接、投票接受和发送的作用。通过在 QuorumCnxManager.Listener 中创建 ServerSocket 对象监听 Leader 选举的通信端口(default:3888),接收到 创建连接的请求后,由 receiveConnection 方法来处理,并在 handleConnection 方法中对连接的合法性进行处理,包括 接受的数据是否合法(大小不可小于 0,大于 maxBuffer 2048 [硬编码])、权限控制。之后,会对 SID 进行判断,如果 mySID 大于接受到的 SID 要大,则会执行 closeSocket 方法断开连接,并执行 SendWorker#finish 关闭对应 SID 的 SendWorker。反之,则会创建 SendWorker 和 RecvWorker 并启动。此举可用来确保,只有 SID 更高的节点才会主动创建连接,避免重复的 TCP 连接
LE 实现细节
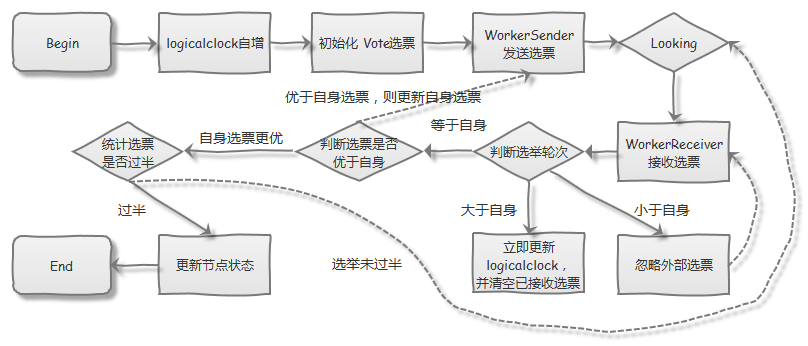
最终进行选举的逻辑实现,都在 FastLeaderElection 中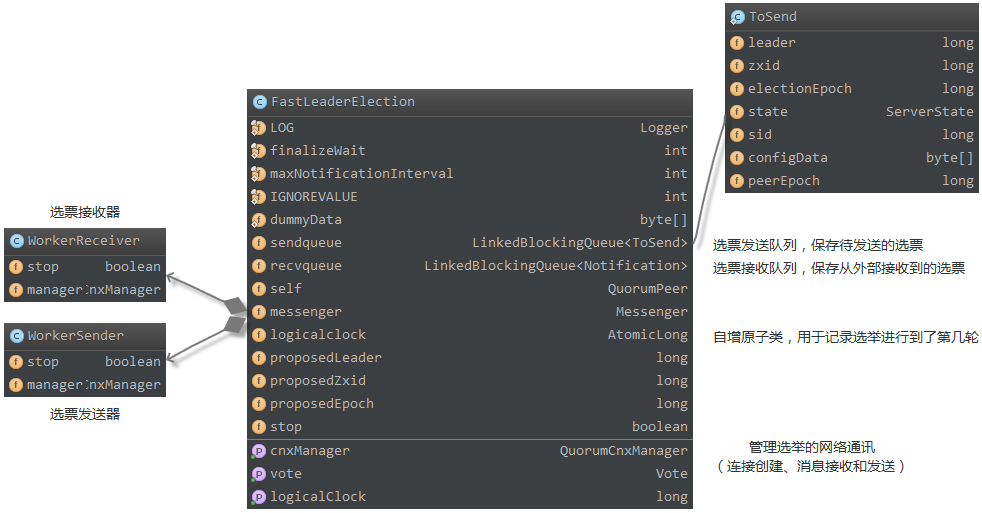
首先会发送投给自身的一条选票,并进入 LOOKING 状态,不断接受外部的选票。再接收到选票之后,会对选票的轮次(logicalclock)、事务 ID(ZXID)、服务器 ID(SID)依次进行比较,如果有一项比自身的值更大,则会更新自身的选票,并重新发送给其他 Quorum;否则,将忽略外部接受的选票,并统计是否已过半。最终,如果选票已经被过半数的 Quorum 节点所接受(Accept),则更新服务器状态,完成选举;否则,继续进入 LOOKING 状态,重复之前的步骤
相关实现代码如下
1 | /** |
ZAB 和 Paxos 的区别
ZAB,Atomic Broadcast 协议,保证了发给各副本的消息顺序相同(因为 ZooKeeper 是一个树形结构,很多操作都要先检查才能确定能不能执行,如 /a/b 需要在 先创建好 /a 的前提下,才能创建 /a/b)
Paxos 保证不了全序顺序,Paxos 算法的确是不关心请求之间的逻辑顺序,而只考虑数据之间的全序
ZAB 的核心思想,形象的说就是保证任意时刻只有一个节点是 Leader,所有更新事务由 Leader发起去更新所有副本(称为 Follower),更新时用的就是 Two-phase 两阶段提交协议,只要多数节点 prepare 成功,就通知他们 commit
各 Follower 要按当初 Leader 让他们 prepare 的顺序来 apply 事务
另外,因为 ZAB 处理的事务永远不会回滚,ZAB 对 2PC 阶段做了点优化,多个事务只要通知 ZXID 最大的那个 commit,之前的各 Follower 会统统 commit
本质上,二者的设计目标是不一样的,ZAB 协议主要用于构建一个髙可用的分布式数据主备系统,而 Paxos 算法则是为了构建一个分布式的一致性状态机系统
数据相关
ZooKeeper 内存结构
ZKDatabase 作为 ZooKeeper 内存数据库的主体,包含了 Session 会话、DataTree、Snapshot(记录 ZooKeeper 服务器上某一个时刻全量的内存数据内容)、事务日志(事务操作时间 、客户端会话 ID、 CXID [客户端的操作序列号]、ZXID、操作类型、会话超时时间、节点路径、节点数据内容、节点的 ACL 信息、 是否为临时节点 和 父节点的子节点版本号)等信息。ZKDatabase 会定时地向磁盘 dump 快照数据,并会在 ZooKeeper 服务端节点启动/重启的时候,read 磁盘上的事务日志和 Snapshot 文件,load 相关数据到内存中,重新恢复出整个 ZKDatabase
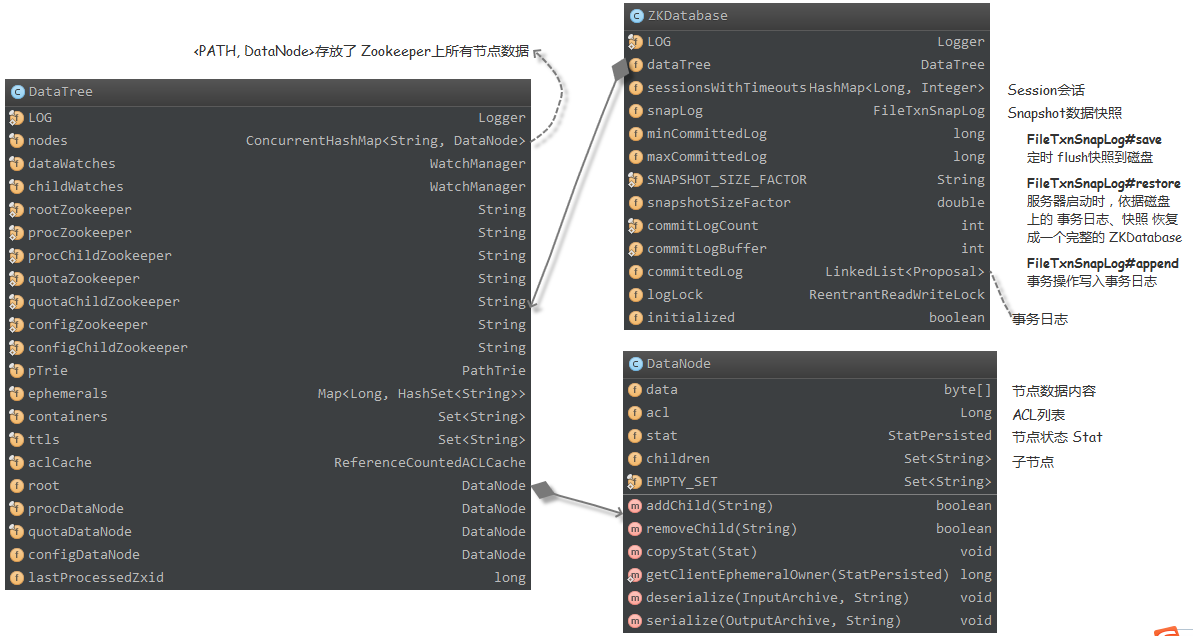
ZooKeeperServer 初始化流程
启动 ZooKeeper 服务器节点的流程,从 ServerMain#main 方法开始。主要的调用链如下:
1 | org.apache.zookeeper.server.ZooKeeperServerMain#runFromConfig |
最终 Session 和 数据的恢复,都将在 loadData 方法中完成。ZKServer 首先利用 ZKDatabase#loadDataBase 调用 FileTxnSnapLog#restore 方法,从磁盘中反序列化 100(硬编码了在 findNValidSnapshots(100) 代码里)个有效的 Snapshot 文件,恢复出 DataTree 和 sessionsWithTimeouts 两个数据结构,以便获取到最新有效的 ZXID,并使用 FileTxnSnapLog#processTransaction 方法增量地处理 DataTree 中的事务。随后根据 Session 超时时间,将超时的 Session 从 DataTree#ephemerals 变量(Map<Long: sessionId, HashSet<String>: pathList>)中移除。同时,利用 ZooKeeperServer#takeSnapshot 方法,将 DataTree 实例持久化到磁盘,创建一个全新的 Snapshot 文件
Snapshot 策略
首先,我们可以看到 SyncRequestProcessor 类的 run() 方法中,ZooKeeperServer#takeSnapshot 方法的调用是在一个新起的线程中发起的,因此 Snapshot 流程是异步发起的
1 | // org.apache.zookeeper.server.SyncRequestProcessor#run |
另外,在启动 Snapshot 线程之前,通过 $logCount \gt (snapCount / 2 + randRoll)$ 公式进行计算,是否应该发起 Snapshot(同时会保证前一个 Snapshot 已经结束才会开始)。由此可见 ZooKeeper 的设计巧妙之处,这里加入了 randRoll 随机数,可以降低所有 Server 节点同时发生 Snapshot 的概率,从而避免因 Snapshot 导致服务受影响。因为,Snapshot 的过程会消耗大量的 磁盘 IO、CPU 等资源,所以全部节点同时 Snapshot 会严重影响集群的对外服务能力
请求流程
按照 ZooKeeperServer 的文档中所示,事务处理的大体流程链应该为 PrepRequestProcessor - SyncRequestProcessor - FinalRequestProcessor。因此,这也将是我们研究源码的阅读顺序
ZooKeeper 乐观锁
分布式中锁分类为,悲观锁(又称悲观并发控制 Pessimistic Concurrency Control,PCC)和 乐观锁(又称乐观并发控制 Optimistic Concurrency Control,OCC)。乐观锁事务控制流程,分为 数据读取、写入校验和数据写入三个阶段,常见实现为 JDK 中的 CAS(synchronized / Atomic 类)。如果是并发竞争少或事务冲突频率低的场景,可使用乐观锁,写入校验成功就执行,不成功就失败回滚;如果冲突频率高或者重试代价大的场景,则建议使用悲观锁
而 ZooKeeper 中,是在执行 OpCode.setData 操作的时候,对 version 版本进行校验,从而实现了 乐观锁的 写入校验流程。如果,发现 version 和 currentVersion 是不一致的,则抛出 BadVersionException 异常进而回滚。不过,如果 version 的值为 -1,意味着 Client 的此次操作请求,不需要进行 乐观锁来控制并发,则无需校验。此处,只是对 version 进行了一次数据写入前的校验,如果并发导致失败了,将直接返回 KeeperErrorCode = BadVersion 错误信息
1 | // org.apache.zookeeper.server.PrepRequestProcessor#pRequest2Txn |
ZooKeeper 连接地址列表的连接策略
ZooKeeper 考虑到第一次连接的时候,使用 StaticHostProvider#resolveAndShuffle 方法进行一次 shuffle,避免第一台节点处于热点状态;而 ZooKeeper 的 Session 连接断开之后,会使用 StaticHostProvider#next 方法,从第一个连接地址开始逐个尝试;另外,在集群扩容/缩容的时候,使用 StaticHostProvider#updateServerList 方法,更新服务器列表,并计算集群扩容的概率,对连接做重新分配,使得集群的负载更加均衡
Follower 和 Observer 请求转发
为了事务的一致性,所有 Follower、Observer 接收到的事务请求,都会通过 Learner#request 方法,将请求发送给 Leader 节点来处理
1 | // org.apache.zookeeper.server.quorum.FollowerRequestProcessor | ObserverRequestProcessor |
Watch 事件触发流程
所有的 Watch 事件都通过 WatchManager#triggerWatch 进行触发。该方法会从 HashMap<String, HashSet<Watcher>> watchTable 中,通过 ServerCnxn#process 方法,将 Watch 对象取出(HashMap#remove 意味着 Watch 只会在 ZooKeeper 触发一次,不过 Curator 框架中已封装,只需注册一次,可多次触发 Watch 事件),并随后通过 ServerCnxn#sendResponse 封装并发送网络包
由此可见,如果 Socket 通讯出现网络故障等问题,可能会丢失 Watch 事件。同时,因为注册一次之后,Watcher 就会从 watchTable 中被移除,再次注册完成之前,发生的 Watch 事件,将无法被监控到。并且,如果 Client 端和 Server 端断开连接之后,因为服务端并没有对 Watch 事件做任何留存,所以重连之后也是无法接受到任何 Watch 事件的(因此,程序中需要在接收到 disconnect 事件之后,进入某种安全模式,使得程序更为谨慎地处理 “依赖于 ZooKeeper Watch 的操作”)。另外,还要一个需要注意的地方是,同一个 ZNode 节点被 Watch 了多种事件,针对该 ZNode 节点 Client 端只会获取到一个 Watch 事件(例如,监控 ZNode A 的 exists / getData 事件,在删除了 A 之后,Client 端只会接受到一个 Delete 事件)
总而言之,强依赖于 ZooKeeper Watch 事件的程序逻辑,都是不可靠的
1 | // [NIO 相关的流程] |
mntr 四字命令使用 JVMFLAGS 和 SERVER_JVMFLAGS 中配置的 JVM 参数
通过增加 START_SERVER_JVMFLAGS 参数,来避免这个问题(已提交 PR#302)
架构设计
ZooKeeper 的 Server ID 如果重复会有什么风险?
截止 v3.5.3 并没有对这个问题进行代码层级的限制,已提交 ZOOKEEPER-2784 issues 和 对应的 #257 PR,进行反馈和修复
ZooKeeper 的事务 ID 超过 32 位,ZooKeeper 的 Leader 节点抛出 XidRolloverException 强制进行 re-election
ZXID 的高 32 位用于 epoch(LE 选举轮次)、低 32 位是一个记录 Leader 节点每一次改动的 counter
如果是 1k/s ops,那么只要 $2^{32} / (86400 * 1000)$ $\approx 49.7$ days 就会将 ZXID 耗尽
重度依赖 ZooKeeper 的应用,可能一周内发生 ZooKeeper 自重启一两次,每次需 30 秒,有无更好的解决方法
在 ZXID 快要溢出的时候,一次性进行自重启的所有操作,必然会比较慢。可以考虑把非依赖的关键步骤拆开,提前做好自重启的准备,以减少延迟
1 | /** |
或者,重新设计 ZXID,高 24 位用于 epoch,低 40 位用于 counter,那么意味着 Math.min($2^{24}$ / 365 / 24, $2^{40}$ / 365 / 86400 / 1000) $\approx$ Math.min(1915.2, 34.9) = 34.9 years 之后才会进行一次强制选举。不过考虑到
ZXID 是 long 类型,32 bit 的 JVM 在对 long 读写时(和 double 类型一样),是分为高 32 位和 低 32 位两部分进行操作的,由于 ZXID 变量没有用 volatile 修饰,且也没有装箱为对应的引用类型(Long / Double),属于非原子操作。因此,如果将高 32 位的低 8 位划分给整个 long 的低 32 位,就可能存在并发的问题了(已提交 Jira / PR,欢迎加入讨论)
常见误区
Paxos 的强一致性
Paxos 本身只是用来选主的算法,用来在分布式节点之间达成共识(Consensus)。只有到了上层应用(ZooKeeper / Redis),出现 数据“副本”的概念,在维持其一致性(Consistency)的时候 才会有强弱之分(一致性模型 vs 一致性协议)
而且,整个副本系统的一致性级别,并不只取决于共识算法,客户端的实现规范也会起到关键作用。如果,Client 客户端允许访问 非 Leader 节点 获取数据,而过半写成功导致有部分 Follower 节点数据副本并没有完成更新(也可以调用 sync() 方法完成强制同步),仍然会表现出弱一致性
有了逻辑时钟后,物理时钟就不再需要了
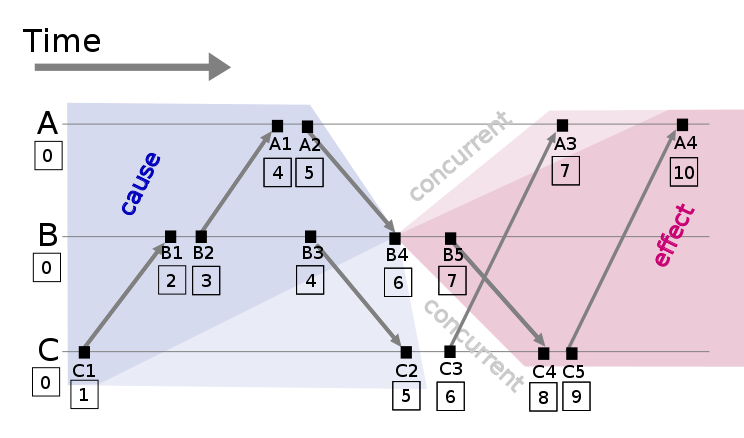
上图就是一个经典的 Lamport 逻辑时钟图,大致的算法描述如下(详见该篇《Time, Clocks, and the Ordering of Events in a Distributed System》论文):
- 每个事件对应一个
Lamport时间戳(初始值为0) - 如果,事件在自己本节点内发生,时间戳加
1即可 - 如果,事件属于发送事件,时间戳加
1并在消息中带上该时间戳 - 如果,事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
并且规定,Lamport 逻辑时钟内做全序,是按事件的时间戳大小为时间排序的,任何两个事件不可能在同一时间发生(并发发生的 B4 和 C3 被认为是有先后顺序的,这里直接按照进程 ID 的大小认定事件发生顺序),并且任何消息收到的时间都应该比发送的时间晚
同时,如果 B4 和 C3 两个事件之间,在逻辑时钟系统之外,有额外的操作,使其有了依赖关系 B4 -> C3,如果 C 进程的 ID 又大于 B 进程的 ID,则无法完成全序操作。因此,需要通过 FTP 时钟同步 或者 Berkeley 算法去调整误差 的方式加入物理时钟。物理时钟的引入,是为了能够区分,系统是处于事件间隔中,还是出错中断了(有兴趣,还可深入研究下 Lamport Logic Lock 的演化版 Vector clock)
依赖组件梳理
梳理点
- 依赖框架中哪部分组件在使用 ZooKeeper,以及使用方式
- 存储的数据(路径、大小、读写的频率 等)
- 对 ZooKeeper 可能产生的压力(并发度、Watcher 数 等)
- 是否对 ZooKeeper 强依赖
依赖 ZooKeeper 的框架
Yarn
遇到的坑
滚动重启升级 ZooKeeper 之后,Yarn 一直重试
描述
一直重连的原因是,Yarn 发送的数据包超过了 1MB
(我们遇到的情况是 1.3MB),服务端默认会设置 1MB 的阀值,避免影响 ZooKeeper 自身的服务解决
重启 ResourceManager 即可
HBase
遇到的坑
KeeperErrorCode = Session expired for /hbase/meta-region-server
描述
连接 HBase 的 Client 突然一段时间 间歇性地报错KeeperErrorCode = Session expired for /hbase/meta-region-server解决
- 查看 HBase、ZooKeeper 的日志和监控告警,并没有发现异常(也就是说,集群没有故障,也没有出现负载过大的情况)
- 发现
/hbase/meta-region-serverZNode 结点保存的信息(meta 表存在于哪一个 RegionServer),并没有和 HBase 集群真实的情况不一致。并且,meta 表的迁移,除非机房断电之类的异常情况,一般是很少发生的 - 尝试在 HBase Client 端的程序,加上
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log的 JVM 参数,来观察是否是客户端程序发生 Long GC 导致的
fsync-ing the write ahead log in SyncThread:1 took 5051ms which will adversely effect operation latency
1 | 2017-06-28 15:28:01,149 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:Follower@89] - Exception when following the leader |
FollowerRequestProcessor.java:88 这行代码是 OpCode.closeSession 操作转发给 Leader,需要发送一个请求包,但是网络问题导致 Socket 连接断开了;另外,fsync-ing the write ahead log in SyncThread:1 took 5051ms which will adversely effect operation latency 告警,意味着 FileTxnLog#commit 进行写事务日志到磁盘的过程过慢
这里可能会导致一个疑问,到底是因为需要写入的事务日志过大导致的告警,还是因为机器磁盘当前的 I/O 负载比较高,所以这里最好再打印出 FileChannel#size() 的信息(已提交 PR#296)
Druid
遇到的坑
DruidTaskResolver: Poll failed, trying again
描述
1
2
3
4
5
6
7
8
9
10
11
12
13
1428 Feb 2018 10:41:45,065 WARN [DruidTaskResolver[com.metamx.tranquility.druid.IndexService@214fd977]] (?.?:?) - Poll failed, trying again at[2018-02-28T10:42:03.867+08:00].
java.lang.IllegalStateException: Service is closed
at com.metamx.tranquility.druid.IndexService.com$metamx$tranquility$druid$IndexService$$client(IndexService.scala:57)
at com.metamx.tranquility.druid.IndexService$$anonfun$call$1.apply(IndexService.scala:131)
at com.metamx.tranquility.druid.IndexService$$anonfun$call$1.apply(IndexService.scala:131)
at com.metamx.tranquility.finagle.FutureRetry$.onErrors(FutureRetry.scala:47)
at com.metamx.tranquility.druid.IndexService.call(IndexService.scala:130)
at com.metamx.tranquility.druid.IndexService.runningTasks(IndexService.scala:101)
at com.metamx.tranquility.finagle.DruidTaskResolver$$anon$1.run(DruidTaskResolver.scala:83)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)解决
定位原因是 Apache Curator 2.11.1 的 bug(详见 CURATOR-394 和 PR#208),将 patch 代码合进 Curator 的 curator-x-discovery 模块后,重新打包 curator-x-discovery-2.11.1.jar,并替换原生的,即可
Storm
遇到的坑
Unable to load database on disk
描述
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
542017-12-08 22:01:01,943 [myid:4] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@197] - Accepted socket connection from /0:0:0:0:0:0:0:1:24756
2017-12-08 22:01:01,943 [myid:4] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@838] - Processing srst command from /0:0:0:0:0:0:0:1:24756
2017-12-08 22:01:01,944 [myid:4] - INFO [Thread-342422:NIOServerCnxn@1018] - Closed socket connection for client /0:0:0:0:0:0:0:1:24756 (no session established for client)
2017-12-08 22:02:01,111 [myid:4] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@197] - Accepted socket connection from /0:0:0:0:0:0:0:1:25076
2017-12-08 22:02:01,111 [myid:4] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@838] - Processing ruok command from /0:0:0:0:0:0:0:1:25076
2017-12-08 22:02:01,112 [myid:4] - INFO [Thread-342423:NIOServerCnxn@1018] - Closed socket connection for client /0:0:0:0:0:0:0:1:25076 (no session established for client)
22017-12-08 22:46:17,702 [myid:] - INFO [main:QuorumPeerConfig@103] - Reading configuration from: /home/zookeeper/software/zookeeper/bin/../conf/zoo.cfg
2017-12-08 22:46:17,730 [myid:] - INFO [main:QuorumPeerConfig@340] - Defaulting to majority quorums
2017-12-08 22:46:17,793 [myid:4] - INFO [main:DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3
2017-12-08 22:46:17,794 [myid:4] - INFO [main:DatadirCleanupManager@79] - autopurge.purgeInterval set to 1
2017-12-08 22:46:17,796 [myid:4] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@138] - Purge task started.
2017-12-08 22:46:17,855 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2017-12-08 22:46:18,193 [myid:4] - INFO [main:NIOServerCnxnFactory@94] - binding to port 0.0.0.0/0.0.0.0:2181
2017-12-08 22:46:18,266 [myid:4] - INFO [main:QuorumPeer@959] - tickTime set to 2000
2017-12-08 22:46:18,266 [myid:4] - INFO [main:QuorumPeer@979] - minSessionTimeout set to -1
2017-12-08 22:46:18,266 [myid:4] - INFO [main:QuorumPeer@990] - maxSessionTimeout set to -1
2017-12-08 22:46:18,266 [myid:4] - INFO [main:QuorumPeer@1005] - initLimit set to 10
2017-12-08 22:46:18,650 [myid:4] - INFO [main:FileSnap@83] - Reading snapshot /data/zookeeper/datadir/version-2/snapshot.e72200034
2017-12-08 22:46:18,831 [myid:4] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@144] - Purge task completed.
2017-12-08 22:46:31,861 [myid:4] - ERROR [main:QuorumPeer@497] - Unable to load database on disk
java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
at org.apache.zookeeper.server.persistence.FileHeader.deserialize(FileHeader.java:64)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.inStreamCreated(FileTxnLog.java:580)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.createInputArchive(FileTxnLog.java:599)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.goToNextLog(FileTxnLog.java:565)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:647)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:158)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:450)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:440)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2017-12-08 22:46:31,868 [myid:4] - ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:498)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:440)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
at org.apache.zookeeper.server.persistence.FileHeader.deserialize(FileHeader.java:64)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.inStreamCreated(FileTxnLog.java:580)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.createInputArchive(FileTxnLog.java:599)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.goToNextLog(FileTxnLog.java:565)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:647)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:158)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:450)
... 4 more
分析
可以看到
2017-12-08 22:02:01,112到22017-12-08 22:46:17,702日志有一个断层,可以看出之前的日志写入被中断了(后续在/var/log/message系统日志里面也验证了)。基本可以确定是,单独挂的盘发生了故障,导致了 Snapshot 文件损坏。而自启动脚本尝试重启 ZooKeeper 进程的时候,ZooKeeper 会依据事务日志里面的最新的 ZXID,一直去尝试读取最后一个已损坏的 Snapshot 文件,导致一直无法恢复1
2$ vim /var/log/messages
kernel: EXT4-fs (vdb): warning: mounting fs with errors, running e2fsck is recommended
解决
因为
EOFException导致当前 ZooKeeper 进程退出后,集群已经选主出新的 Leader 节点,所以,可以直接删除事务日志和 Snapshot 文件,分别对应于dataDir和dataLogDir两个目录(理论上只需要保存myid文件,其他数据会从 Leader 节点重新拉取)。删除数据完成之后,直接启动 ZooKeeper 进程,当前节点即可重新加入 ZooKeeper 集群1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80# 读取配置
2017-12-08 23:20:07,161 [myid:] - INFO [main:QuorumPeerConfig@103] - Reading configuration from: /home/zookeeper/software/zookeeper/bin/../conf/zoo.cfg
2017-12-08 23:20:07,165 [myid:] - INFO [main:QuorumPeerConfig@340] - Defaulting to majority quorums
2017-12-08 23:20:07,168 [myid:4] - INFO [main:DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3
2017-12-08 23:20:07,169 [myid:4] - INFO [main:DatadirCleanupManager@79] - autopurge.purgeInterval set to 1
2017-12-08 23:20:07,170 [myid:4] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@138] - Purge task started.
2017-12-08 23:20:07,179 [myid:4] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@144] - Purge task completed.
2017-12-08 23:20:07,181 [myid:4] - INFO [main:QuorumPeerMain@127] - Starting quorum peer
2017-12-08 23:20:07,191 [myid:4] - INFO [main:NIOServerCnxnFactory@94] - binding to port 0.0.0.0/0.0.0.0:2181
2017-12-08 23:20:07,201 [myid:4] - INFO [main:QuorumPeer@959] - tickTime set to 2000
2017-12-08 23:20:07,202 [myid:4] - INFO [main:QuorumPeer@979] - minSessionTimeout set to -1
2017-12-08 23:20:07,202 [myid:4] - INFO [main:QuorumPeer@990] - maxSessionTimeout set to -1
2017-12-08 23:20:07,202 [myid:4] - INFO [main:QuorumPeer@1005] - initLimit set to 10
# 开始进行选举
2017-12-08 23:20:07,214 [myid:4] - INFO [main:QuorumPeer@473] - currentEpoch not found! Creating with a reasonable default of 0. This should only happen when you are upgrading your installation
2017-12-08 23:20:07,223 [myid:4] - INFO [main:QuorumPeer@488] - acceptedEpoch not found! Creating with a reasonable default of 0. This should only happen when you are upgrading your installation
2017-12-08 23:20:07,228 [myid:4] - INFO [Thread-2:QuorumCnxManager$Listener@505] - My election bind port: /192.168.1.104:3888
# 进入 LOOKING 状态,并创建自己的选票
2017-12-08 23:20:07,238 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:QuorumPeer@714] - LOOKING
2017-12-08 23:20:07,243 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@815] - New election. My id = 4, proposed zxid=0x0
2017-12-08 23:20:07,250 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 1 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,250 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), FOLLOWING (n.state), 1 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,252 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 4 (n.leader), 0x0 (n.zxid), 0x1 (n.round), LOOKING (n.state), 4 (n.sid), 0x0 (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,253 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 3 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,253 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), FOLLOWING (n.state), 3 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,253 [myid:4] - INFO [WorkerSender[myid=4]:QuorumCnxManager@195] - Have smaller server identifier, so dropping the connection: (5, 4)
2017-12-08 23:20:07,254 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 4 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,254 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), FOLLOWING (n.state), 3 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,254 [myid:4] - INFO [WorkerSender[myid=4]:QuorumCnxManager@195] - Have smaller server identifier, so dropping the connection: (5, 4)
2017-12-08 23:20:07,254 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), FOLLOWING (n.state), 1 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,255 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 4 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,272 [myid:4] - INFO [/192.168.1.104:3888:QuorumCnxManager$Listener@512] - Received connection request /192.168.1.105:18290
2017-12-08 23:20:07,273 [myid:4] - INFO [/192.168.1.104:3888:QuorumCnxManager$Listener@512] - Received connection request /192.168.1.105:18291
2017-12-08 23:20:07,274 [myid:4] - WARN [RecvWorker:5:QuorumCnxManager$RecvWorker@781] - Connection broken for id 5, my id = 4, error =
java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.zookeeper.server.quorum.QuorumCnxManager$RecvWorker.run(QuorumCnxManager.java:766)
2017-12-08 23:20:07,296 [myid:4] - WARN [RecvWorker:5:QuorumCnxManager$RecvWorker@784] - Interrupting SendWorker
2017-12-08 23:20:07,295 [myid:4] - WARN [SendWorker:5:QuorumCnxManager$SendWorker@698] - Interrupted while waiting for message on queue
java.lang.InterruptedException
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.reportInterruptAfterWait(AbstractQueuedSynchronizer.java:2017)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2095)
at java.util.concurrent.ArrayBlockingQueue.poll(ArrayBlockingQueue.java:389)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.pollSendQueue(QuorumCnxManager.java:850)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.access$500(QuorumCnxManager.java:61)
at org.apache.zookeeper.server.quorum.QuorumCnxManager$SendWorker.run(QuorumCnxManager.java:686)
2017-12-08 23:20:07,280 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 2 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,297 [myid:4] - WARN [SendWorker:5:QuorumCnxManager$SendWorker@707] - Send worker leaving thread
2017-12-08 23:20:07,297 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), FOLLOWING (n.state), 2 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,297 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LOOKING (n.state), 5 (n.sid), 0xe (n.peerEpoch) LOOKING (my state)
2017-12-08 23:20:07,297 [myid:4] - INFO [WorkerReceiver[myid=4]:FastLeaderElection@597] - Notification: 1 (message format version), 5 (n.leader), 0xe72217dad (n.zxid), 0x6 (n.round), LEADING (n.state), 5 (n.sid), 0xf (n.peerEpoch) LOOKING (my state)
# 经过 84ms,进入 FOLLOWING 状态,完成选举过程
2017-12-08 23:20:07,298 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:QuorumPeer@784] - FOLLOWING
2017-12-08 23:20:07,303 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Learner@86] - TCP NoDelay set to: true
2017-12-08 23:20:07,317 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:zookeeper.version=3.4.6--1, built on 08/30/2017 09:55 GMT
2017-12-08 23:20:07,317 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:host.name=yuzhouwan-storm-4
2017-12-08 23:20:07,317 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.version=1.7.0_60-ea
2017-12-08 23:20:07,317 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.vendor=Oracle Corporation
2017-12-08 23:20:07,317 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.home=/home/zookeeper/software/jdk1.7.0_60/jre
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.class.path=/home/zookeeper/software/zookeeper/bin/../build/classes:/home/zookeeper/software/zookeeper/bin/../build/lib/*.jar:/home/zookeeper/software/zookeeper/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/zookeeper/software/zookeeper/bin/../lib/slf4j-api-1.6.1.jar:/home/zookeeper/software/zookeeper/bin/../lib/netty-3.7.0.Final.jar:/home/zookeeper/software/zookeeper/bin/../lib/log4j-1.2.16.jar:/home/zookeeper/software/zookeeper/bin/../lib/jline-0.9.94.jar:/home/zookeeper/software/zookeeper/bin/../zookeeper-3.4.6.4.jar:/home/zookeeper/software/zookeeper/bin/../src/java/lib/*.jar:/home/zookeeper/software/zookeeper/bin/../conf:/home/zookeeper/software/java/lib/dt.jar:/home/zookeeper/software/java/lib/tools.jar:.
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.io.tmpdir=/tmp
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:java.compiler=<NA>
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:os.name=Linux
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:os.arch=amd64
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:os.version=2.6.32-279.19.1.el6_sn.11.x86_64
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:user.name=zookeeper
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:user.home=/home/zookeeper
2017-12-08 23:20:07,318 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Environment@100] - Server environment:user.dir=/data/zookeeper
2017-12-08 23:20:07,320 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:ZooKeeperServer@162] - Created server with tickTime 2000 minSessionTimeout 4000 maxSessionTimeout 40000 datadir /data/zookeeper/dataLogDir/version-2 snapdir /data/zookeeper/datadir/version-2
2017-12-08 23:20:07,320 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Follower@63] - FOLLOWING - LEADER ELECTION TOOK - 77
# 从 Leader 节点获取最新的 Snapshot 文件
2017-12-08 23:20:07,335 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Learner@326] - Getting a snapshot from leader
2017-12-08 23:20:07,545 [myid:4] - WARN [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Learner@374] - Got zxid 0xf001761dc expected 0x1
# 创建 Snapshot 文件(实际内容是 zxid - 1,而不是直接用最新的 zxid)
2017-12-08 23:20:07,545 [myid:4] - INFO [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:FileTxnSnapLog@240] - Snapshotting: 0xf001761db to /data/zookeeper/datadir/version-2/snapshot.f001761db
# 创建事务日志文件
2017-12-08 23:20:07,655 [myid:4] - INFO [SyncThread:4:FileTxnLog@203] - Creating new log file: log.f001761dc
2017-12-08 23:20:07,657 [myid:4] - WARN [QuorumPeer[myid=4]/0:0:0:0:0:0:0:0:2181:Follower@118] - Got zxid 0xf00176261 expected 0x1
# 至此,完成最终恢复,历时 496ms
Flink
遇到的坑
Node not empty: /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
描述
1
2
3
4
5
6
7# 没有子目录也无法删除
[zk: localhost:2181(CONNECTED) 1] ls /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
[]
[zk: localhost:2181(CONNECTED) 2] delete /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
Node not empty: /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
[zk: localhost:2181(CONNECTED) 3] rmr /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
Node not empty: /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694解决
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 通过 get 命令发现,6f96a21ae1aaf087b7423f504e554694 本身就是有数据的
# 设置对应 version 为 '' 空字符串,再执行 delete 操作即可
[zk: localhost:2181(CONNECTED) 12] set /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694 '' 1
cZxid = 0x1b01e697c7
ctime = Mon Jun 11 14:29:58 CST 2018
mZxid = 0x1b01ebc650
mtime = Mon Jun 11 17:04:50 CST 2018
pZxid = 0x1b01e6adb8
cversion = 2
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
[zk: localhost:2181(CONNECTED) 13] delete /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
[zk: localhost:2181(CONNECTED) 14] ls /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
Node does not exist: /flink/sportsa/StarterALLJSPlaying/jobgraphs/6f96a21ae1aaf087b7423f504e554694
Hadoop
Kafka
其他技术比对
思维导图

分布式框架
Chubby
Google Chubby 是一种分布式锁服务,解决了分布式协作、元数据存储和 Leader 选举等一系列与分布式锁服务相关的问题,有着以下的优势:
- 提供了一个完整的、独立的分布式锁服务
- 提供粗粒度的锁服务
- 在提供锁服务的同时提供对小文件的读写功能
- 高可用
- 提供事件通知机制
和 ZooKeeper 的区别主要有三点:
一致性算法不同
ZooKeeper 用的是 ZAB 原子广播协议;Chubby 是带租约的 Paxos
API 设计不同
ZooKeeper 用
ZNode节点来实现锁;Chubby 提供了直接的加锁 API集群设计不同
ZooKeeper 每个机器都可以读,提供 sync 方法同步刷新,保证了吞吐量;Chubby 读写都在 Master 单节点上
HyperTable
Hypertable 和 HBase 是最知名的两款基于 BigTable 为蓝本设计的数据库,他们的不同之处在于 Hypertable 基于 Boost C++ 实现,而 HBase 则基于 Java。虽然前者架构足够精细、代码足够高质,但是流行度远不及 HBase
一致性算法
Raft
相比 Paxos,Raft 算法则更加易于理解和实现(目前 Redis 的集群设计用的是 Raft 算法)

分布式协同
Fourinone
Fourinone 是阿里自主研发的一个分布式并行计算框架,它集成了 Hadoop、ZooKeeper、MQ、分布式缓存 四大主要的分布式计算功能。同时,还提供完整的分布式缓存支持,包括中小型缓存以及大型集群缓存,不过已经很长时间没有维护了
分布式服务注册与发现
Consul
Consul 是强一致性的数据存储,使用 Gossip 形成动态集群。它提供分级键/值存储方式,不仅可以存储数据,而且可以用于注册各种事件,从发送数据改变通知到运行健康检查和自定义命令
相比于 ZooKeeper 只能提供 KV 存储,Consul 内嵌了 服务发现系统,并且原生支持多数据中心部署。同时,还可以执行健康检查,并提供一个可视化的 Dashboard 用于管理
Etcd
Etcd 是一个采用 HTTP 协议的键/值对存储系统,它是一个分布式和功能层次配置系统,可用于构建服务发现系统。其很容易部署、安装和使用,提供了可靠的数据持久化特性
Registrator
Registrator 通过检查容器在线或者停止运行状态自动注册和卸载注册服务,它目前支持 etcd、Consul 和 SkyDNS2
Registrator 与 etcd 是一个简单但是功能强大的组合,可以运行很多先进的技术。每当打开一个容器,所有数据将被存储在 etcd 并同步复制到集群中的所有节点上
Confd
Confd 是一个轻量级的配置管理工具,常见的用法是通过使用存储在 etcd、consul 和 其他一些数据登记处的数据保持配置文件的最新状态,它也可以用来在配置文件改变时重新加载应用程序。换句话说,我们可以用存储在 etcd(或者其他注册中心)的信息来重新配置所有服务
实用工具
日志可视化工具
1 | $ cd ~/software/zookeeper |
Snapshot 可视化工具
1 | $ cd ~/software/zookeeper |
Hue Browser 集群页面监控工具
Rest 服务
编译
1 | $ tar zxvf zookeeper-3.4.10.tar.gz -C ~/software/ |
拷贝 Jar 包
1 | $ cp build/contrib/rest/zookeeper-dev-rest.jar src/contrib/rest/lib/ |
启动 Rest Service
1 | $ cd /home/zookeeper/software/zookeeper1/src/contrib/rest |
安装 Hue
1 | # 增加 ZooKeeper 用户 |
移除 Watch 工具
Docker 开发环境部署工具
生成配置工具
冒烟测试工具
Curator 框架
社区跟进
PR & Issues
详见,《如何成为 Apache 的 PMC》
ZooKeeper 社区的一些“规则”
同时也是共享其他开源项目时,需要注意和养成的好习惯,只是 ZooKeeper 中控制更加严格
保持 Diff 信息最简
PR 中不应该做无关的 Code Format(import / 代码缩进 等)
保持 PR 的相关性
不做无关的 代码优化,尤其是对其他不相关的类(可以另起 PR 进行优化)
保持 代码风格一致
关闭 IDE 自动优化 import 合并为通配符 * 的功能(如,import java.io.* 等)
类似的,还有 Apache Druid 里的参数列表,需要分行写;Apache Superset 之类的 Python 项目,需要注意 PEP 规范;Apache Eagle 需要 squash PR 中的 commits 等等。更多相关内容,参见我的另一篇文章:《如何成为 Apache 的 PMC》
规避已知 issues
在 jira 中,根据自己的版本(affectedVersion),找到 Major 级别的 Bug,按照各个组件,对组件(component)进行筛选,并合并 patch 到自己的本地代码库里,从而规避一些已知的 issues,提高集群稳定性
1 | project = ZOOKEEPER AND issuetype = Bug AND resolution = Fixed AND affectedVersion = 3.4.6 AND priority = Major AND component = server ORDER BY priority DESC, updated DESC |
以 v3.4.6 为例
server
- ZOOKEEPER-2026: Startup order in ServerCnxnFactory-ies is wrong
- ZOOKEEPER-2044: CancelledKeyException in zookeeper branch-3.4
- ZOOKEEPER-2052: Unable to delete a node when the node has no children
- ZOOKEEPER-2060: Trace bug in NettyServerCnxnFactory
- ZOOKEEPER-2186: QuorumCnxManager#receiveConnection may crash with random input
quorum
- ZOOKEEPER-1774: QuorumPeerMainTest fails consistently with “complains about host” assertion failure
- ZOOKEEPER-2029: Leader.LearnerCnxAcceptor should handle exceptions in run()
- ZOOKEEPER-2033: zookeeper follower fails to start after a restart immediately following a new epoch
- ZOOKEEPER-2195: fsync.warningthresholdms in zoo.cfg not working
java client
- ZOOKEEPER-1853: zkCli.sh cannot issue a CREATE command containing spaces in the data
- ZOOKEEPER-1897: ZK Shell/Cli not processing commands
- ZOOKEEPER-2375: Prevent multiple initialization of login object in each ZooKeeperSaslClient instance
- ZOOKEEPER-2893: very poor choice of logging if client fails to connect to server
other
- ZOOKEEPER-1913: Invalid manifest files due to bogus revision property value
- ZOOKEEPER-1991: zkServer.sh returns with a zero exit status when a ZooKeeper process is already running
- ZOOKEEPER-2039: Jute compareBytes incorrect comparison index
improvement
- ZOOKEEPER-1506: Re-try DNS hostname -> IP resolution if node connection fails
- ZOOKEEPER-2270: Allow MBeanRegistry to be overridden for better unit tests
- ZOOKEEPER-1948: Enable JMX remote monitoring
- ZOOKEEPER-2205: Log type of unexpected quorum packet in learner handler loop
- ZOOKEEPER-2194: Let DataNode.getChildren() return an unmodifiable view of its children set
资料
Book
Paper
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| 大数据 | |
| 算法 | |
| 数据库 |