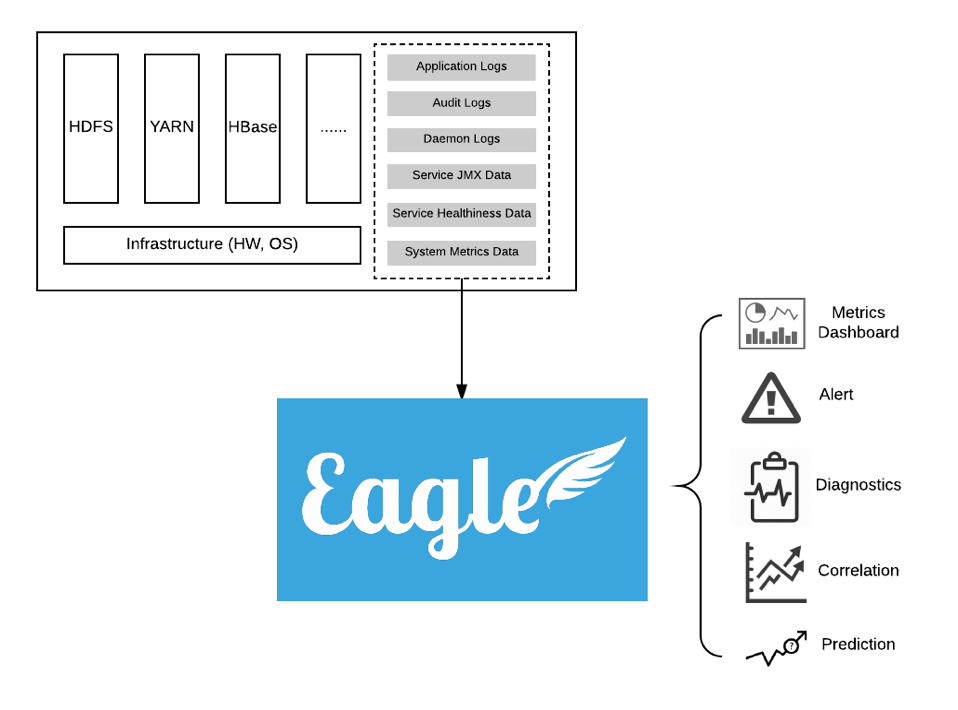
基本概念 Apache Eagle 是一个高度可扩展的监控警报平台,采用了设计灵活的应用框架和经过实践考验的大数据技术,如 Kafka ,Spark 和 Storm 。它提供了丰富的大数据平台监控程序,例如 HDFS / HBase / YARN 服务运行状况检查,JMX 指标,守护进程日志,审核日志 和 Yarn 应用程序。外部 Eagle 开发人员可以自定义应用来监视其 NoSQL 数据库或 Web 服务器,可以自己决定是否共享到 Eagle 应用程序存储库。它还提供最先进的警报引擎来报告安全漏洞,服务故障和应用程序异常,由警报策略定义高度可定制。
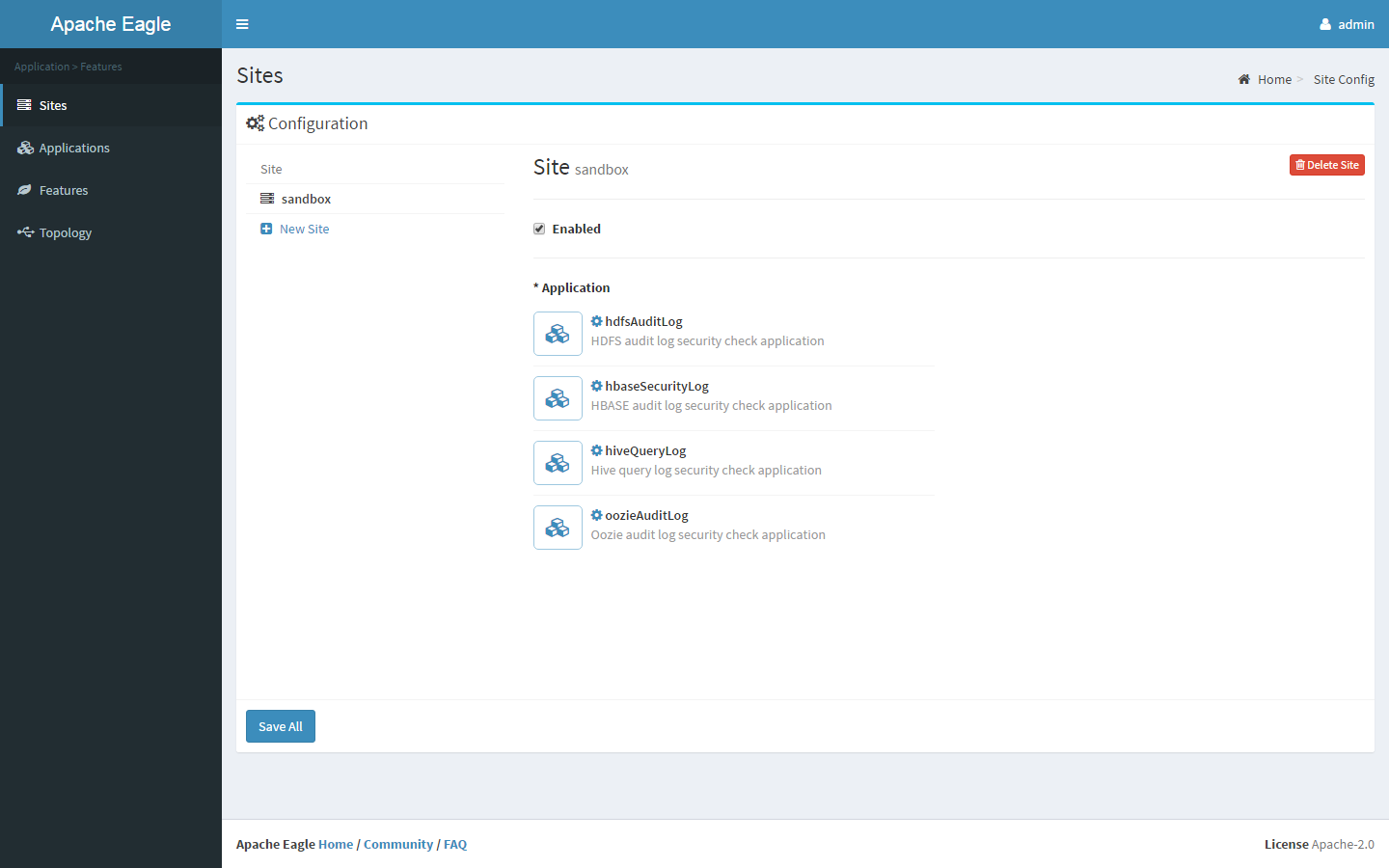
Site 管理一组应用程序实例,用来区别某些被多次安装的应用程序
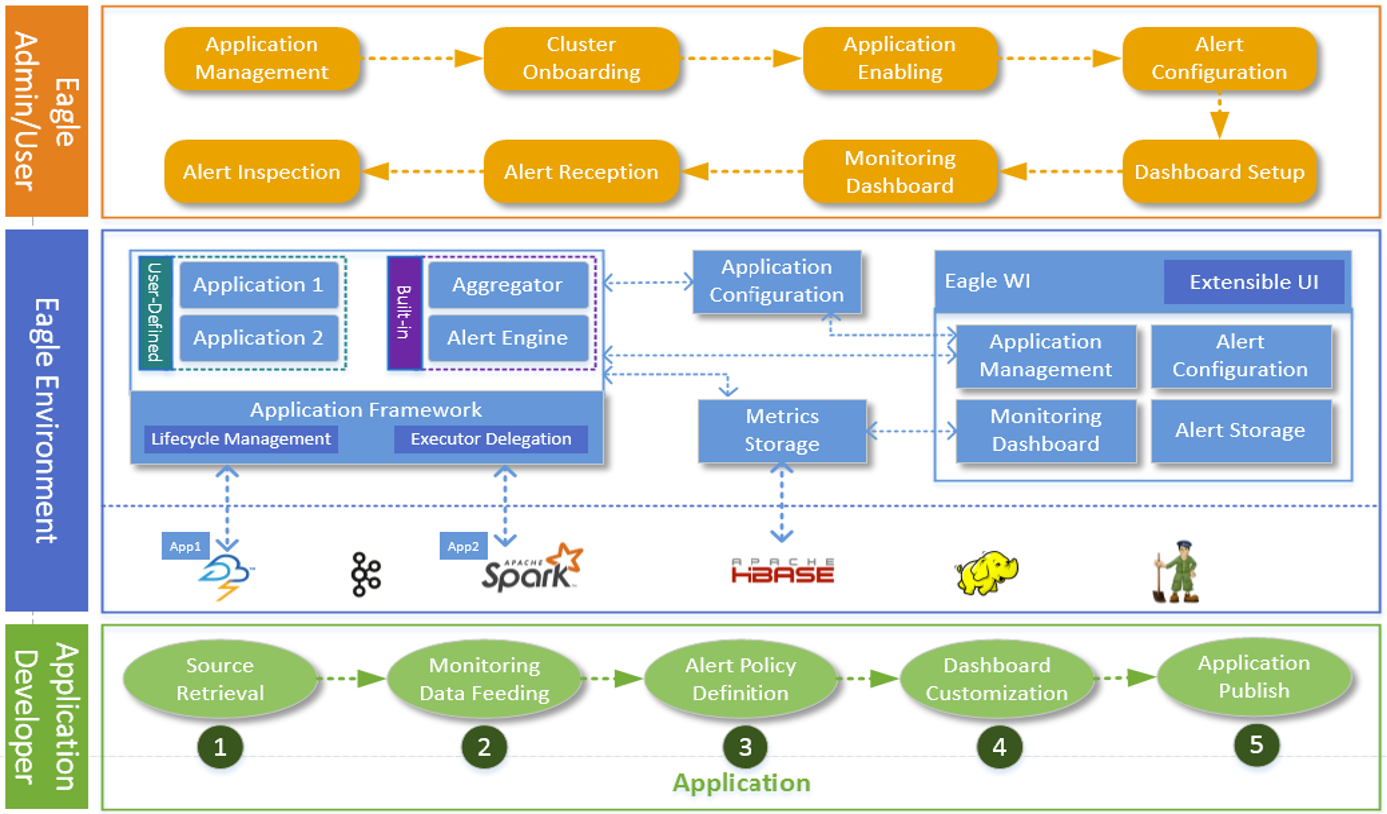
Application 应用程序(或监控应用程序)是 Apache Eagle 中的一级公民,它代表端到端的监控 / 警报解决方案,通常包含监控源入站,源的 schema规范,警报策略和 仪表板定义
Stream Stream 是 Alert Engine 的输入,每个应用程序应该有自己的由开发人员定义的流。通常,流定义里面包含了一个类似 POJO 的结构。一旦定义完成,应用程序就有了将数据写入Kafka 的逻辑
Data Activity Monitoring 内置监控应用程序,用于监控 HDFS / HBase / Hive 操作,并允许用户定义某些策略来实时检测敏感数据访问和恶意数据操作
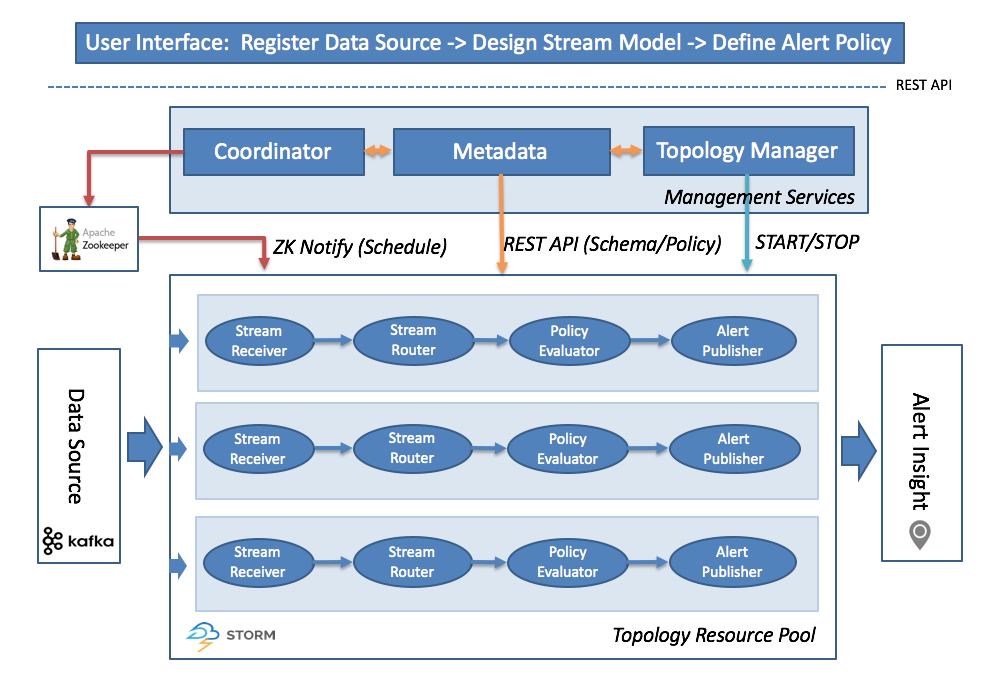
Alert Engine 被所有其他监控应用程序所共享的特定内置应用程序,它从 Kafka 读取数据,并通过实时应用策略来处理数据,并生成报警通知
Policy Alert Engine 使用规则来匹配 Kafka 的数据输入(策略以 SiddhiQL 格式定义)
Alert 如果输入到 Alert Engine 的任何数据符合该策略,则 Alert Engine 将生成一条消息并通过警报发布者(Alert Publisher)进行发布。这些消息我们称之为警报
Alert Publisher 它会将警报发布到可以是 SMTP 通道、Kafka 通道、Slack 通道或 其他存储系统的外部通道
核心架构 概况
告警
存储
主要功能 数据流接入和存储 Metrics 存储
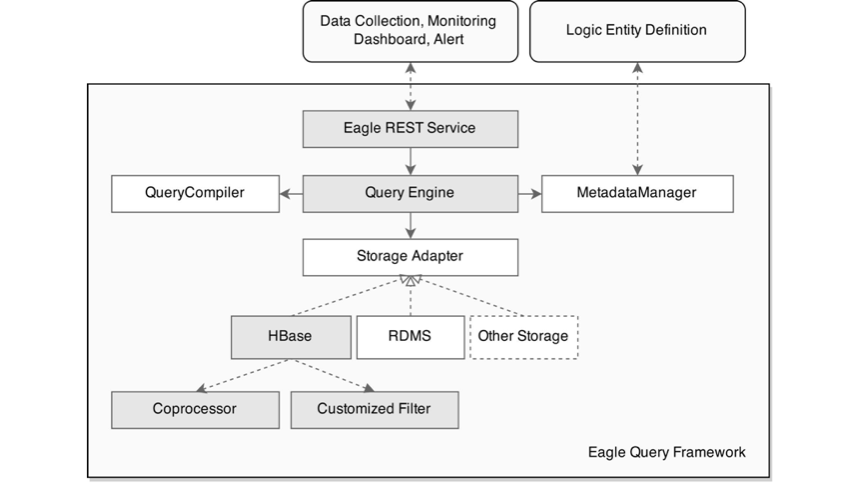
Eagle 为 HBase / RDMBS 提供了轻量级的 ORM 框架,支持使用 Java 注释便于定义持久化数据模型
Eagle 在 NoSQL Model 上提供类似 SQL 的 REST 查询语言(List / Aggregation / Bucket / Rowkey / Rowkey Query、Pagination、Sorting、Union、Join)
针对时间序列数据优化的 Rowkey 设计 ,针对度量/实体/日志等进行了优化,不同的存储类型
数据实时处理 流处理 API Eagle Alert Engine 是基于开源实时流处理框架的,如 Apache Storm 作为默认执行引擎,Apache Kafka 作为默认的消息总线(Messaging Bus)
告警框架
机器学习模块
核密度估计算法(Kernel Density Estimation)
特征值分解算法(Eigen-Value Decomposition)
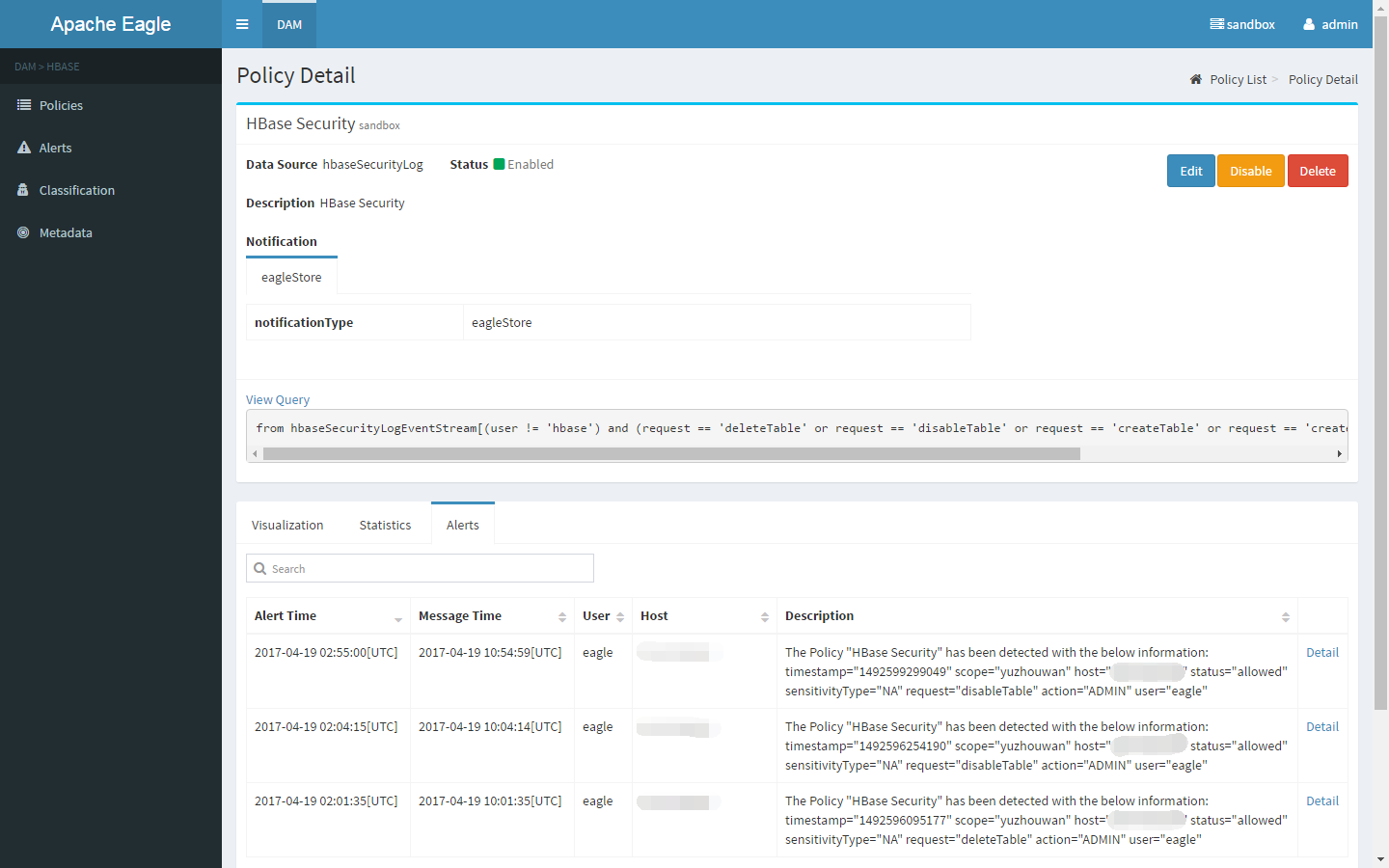
Eagle 服务 策略管理器 Eagle 策略管理器 提供交互友好的用户界面和 REST API 供用户轻松地定义和管理策略策略的管理、敏感元数据的标识和导入、HDFS 或 Hive 的资源浏览以及预警仪表等功能WSO2 的 Siddhi CEP 引擎和 机器学习引擎,以下是几个基于 Siddi CEP 的策略示例
查询服务 单一事件执行策略(用户访问 Hive 中的敏感数据列) 1 from hiveAccessLogStream[sensitivityType= = 'PHONE_NUMBER' ] select * insert into outputStream;
基于窗口的策略(用户在 10 分钟内访问目录 /tmp/private 多于 inverted 5 次) 1 hdfsAuditLogEventStream[(src = = '/tmp/private' )]#window.externalTime(timestamp ,10 min) select user , count (timestamp ) as aggValue group by user having aggValue >= 5 insert into outputStream;
适用场景 数据活动监控 分析数据活动和提醒不安全访问是保护企业数据的基本要求。随着 Hadoop、Hive、Spark 技术的数据量呈指数级增长,了解每个用户的数据活动变得非常困难,更不用说每天在 PB 级的数据流中,实时地警告单个恶意事件数据层次结构,标记敏感数据,然后制定全面的策略,告警不安全的数据访问
任务性能分析 运行 MapReduce 任务是人们用来分析 Hadoop 系统中数据的最流行的方式。分析任务的性能和提供调优建议对于 Hadoop 系统稳定性、作业 SLA 和 资源使用情况至关重要Job 的性能。 首先,Eagle 定期用 Yarn API 为所有正在运行的作业拍摄快照;其次,Eagle 在作业完成后立即读取作业生命周期事件。通过这两种方法,Eagle 可以分析单个 Job 的趋势,数据倾斜问题,失败原因等。更进一步地,Eagle 可以通过考虑所有工作来分析整个 Hadoop 集群的性能
集群性能分析 了解为什么集群性能会下降是至关重要的。那是因为最近一些不正常的工作被提交,还是存在大量的小文件,还是 NameNode 的性能降级了?
Ebay(2015)
Eagle 的数据行为监控系统已经部署到一个拥有 10000 多个节点的 Hadoop 集群之上,用以保护数百 PB 数据的安全
已针对 HDFS、Hive 等集群中的数据内置了一些基础的安全策略,并将不断引入更多的策略,以确保重要数据的绝对安全
Eagle 的策略涵盖多种模式,包括从访问模式、频繁访问数据集,预定义查询类型、Hive 表和列、HBase 表,以及基于机器学习模型生成的用户 Profile 相关的所有策略等
有广泛的策略来防止数据的丢失、数据被拷贝到不安全地点、敏感数据被未授权区域访问等
Eagle 策略定义上极大的灵活性和扩展性,使得未来可以轻易地继续扩展更多更复杂的策略,以支持更多多元化的用例场景
优缺点 优点 高拓展性 Apache Eagle 围绕 application 概念构建了其核心框架,application 本身包括用于监视源数据收集,预处理和归一化的逻辑。开发人员可以使用 Eagle 的应用程序框架轻松开发自己的开箱(out-of-box)监控应用程序,并部署到 Eagle 中
可伸缩 Eagle 核心团队选择了经过考验的大数据技术来构建其基本运行时,并应用可扩展内核,根据数据流的吞吐量以及受监控应用程序的数量进行自适应
实时性 基于 Storm 或 Spark Streaming 的计算引擎使我们能够将策略应用于数据流,并实时生成警报。确保能在亚秒级别的时间内产生告警,一旦综合多种因素确定为危险操作,立即采取措施进行阻止
动态配置 用户可以自由启用或禁用监控应用程序,而无需重新启动服务。还可以动态添加/删除/更改其警报策略,而不会对底层运行时造成任何影响
简单易用 用户可以通过选择相应的监控应用程序并为服务配置少量参数,在几分钟内实现对服务的监控
无侵入性 Apache Eagle 使用开箱即用(out-of-box)的应用程序来监控服务,不需要对现有服务进行任何更改
用户Profile Eagle 内置提供基于机器学习算法,对监控平台中的用户行为习惯建立用户 Profile,实现实时地用户行为告警
开源 Apache Eagle 一直都是根据开源的标准来进行开发的
缺点 目前流行度较差
Watch
Star
Fork
Commit
Contributors
Current Date
53
291
158
1047
27
2018-6-1
稳定性略不足 最新 release 版本为 eagle-0.5.0,刚从 0.4.0-incubating 版本中孵化出来
单元测试覆盖率过低:39%
另外,CI 系统方面,目前只有 Jenkins 在用,而 Travis 并未真实在用,在 fork 的私有分支下开启后,发现每次 build 过程需要一小时之久
代码质量相对较差 由于 check-in 系统的不完善,没有对 代码质量、代码风格、测试覆盖率 等方面进行考量(Apache Eagle 暂定在 v0.5.0 之后进行完善)
对 HBase 的支持度 比对表
Version
Comment
v0.4.0
只支持 用户行为分析
v0.5.0 开始支持 JMX(Metric 不支持)、Add HBase master metric dashboard、Add HBase RegionServer metric dashboard、Integrate hbase metric to basic panel 等功能
参考
Eagle 环境搭建 组件 流式平台依赖
Name
Version
Comment
Storm
0.9.3 or later
0.9.7
Kafka
0.8.x or later
kafka_2.11-0.10.1.1
Java
1.7.x
jdk-1.7.0_80(v0.4 不支持 JDK1.8)
NPM
3.x
3.10.10(On MAC OS try brew install node)
LogStash
2.3.4
Maven
3.3.9
数据库依赖(Choose one of them)
Name
Version
Comment
HBase
0.98 or later
2.7.3 (Hadoop 2.6.x is required)
MySQL
5.5.18(Eagle v0.4 建议使用 MySQL)
Derby
沙箱
Name
Version
Comment
Hortonworks Sandbox
2.2.4
基础环境 Linux 用户 1 2 3 4 5 6 7 8 9 10 11 12 13 $ adduser eagle $ passwd eagle $ chmod u+w /etc/sudoers $ vim /etc/sudoers eagle ALL=(ALL) ALL $ chmod u-w /etc/sudoers $ su - eagle
目录 1 2 3 4 $ cd /home/eagle $ mkdir install && mkdir software && mkdir logs
依赖 JDK Download from jdk-7u80-linux-x64.rpm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ chmod +x install/jdk-7u80-linux-x64.rpm $ sudo rpm -ivh install/jdk-7u80-linux-x64.rpm $ java -version java version "1.7.0_80" Java(TM) SE Runtime Environment (build 1.7.0_80-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode) $ which java /usr/bin/java $ ln -s /usr/java/jdk1.7.0_80 software/jdk1.7.0_80 $ ln -s /home/eagle/software/jdk1.7.0_80 software/java $ vim ~/.bash_profile JAVA_HOME=/home/eagle/software/java CLASSPATH=.:$JAVA_HOME /lib/tools.jar PATH=$JAVA_HOME /bin:$PATH export JAVA_HOME CLASSPATH PATH $ source ~/.bash_profile
如果需要清除之前的低版本 JDK,或者重装,可以参照(没有这个需求,可跳过)
1 2 3 4 $ rpm -qa | grep -E 'jdk|java' jdk-1.7.0_80-fcs.x86_64 $ sudo rpm -e --nodeps jdk-1.7.0_80-fcs.x86_64
Hadoop 依赖 1 2 3 4 5 6 7 8 $ sudo yum install openssh-clients openssh-server -y $ ssh localhost $ exit $ cd ~/.ssh/ $ ssh-keygen -t rsa $ cat id_rsa.pub >> authorized_keys $ chmod 600 ./authorized_keys
安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cd /home/eagle/install/ $ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz $ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz.mds $ head -n 6 hadoop-2.7.3.tar.gz.mds hadoop-2.7.3.tar.gz: MD5 = 34 55 BB 57 E4 B4 90 6B BE A6 7B 58 CC A7 8F A8 hadoop-2.7.3.tar.gz: SHA1 = B84B 8989 3426 9C68 753E 4E03 6D21 395E 5A4A B5B1 hadoop-2.7.3.tar.gz: RMD160 = 8FE4 A91E 8C67 2A33 C4E9 61FB 607A DBBD 1AE5 E03A hadoop-2.7.3.tar.gz: SHA224 = 23AB1EAB B7648921 7101671C DCF9D774 7B84AD50 6A74E300 AE6617FA hadoop-2.7.3.tar.gz: SHA256 = D489DF38 08244B90 6EB38F4D 081BA49E 50C4603D $ md5sum hadoop-2.7.3.tar.gz | tr "a-z" "A-Z" 3455BB57E4B4906BBEA67B58CCA78FA8 HADOOP-2.7.3.TAR.GZ $ tar zxvf hadoop-2.7.3.tar.gz -C ~/software/ $ cd ~/software/ $ ln -s hadoop-2.7.3/ hadoop $ cd hadoop/ $ bin/hadoop version Hadoop 2.7.3 $ mkdir -p ~/input $ rm -r ~/output $ cp etc/hadoop/*.xml ~/input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep ~/input ~/output 'dfs[a-z.]+' $ cat ~/output/* 1 dfsadmin
配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 $ vim ~/.bashrc if [ -f /etc/bashrc ]; then . /etc/bashrc fi export HADOOP_HOME=~/software/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME /lib/native export JAVA_HOME=~/software/java export PATH=$PATH :$HADOOP_HOME /sbin:$HADOOP_HOME /bin:$JAVA_HOME /bin $ source ~/.bashrc $ mkdir -p ~/data/hadoop/tmp $ vim ~/software/hadoop/etc/hadoop/core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/eagle/data/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> $ vim ~/software/hadoop/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/eagle/data/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/eagle/data/hadoop/tmp/dfs/data</value> </property> </configuration> $ vim ~/software/hadoop/etc/hadoop/hadoop-env.sh export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,RFAAUDIT} $HADOOP_NAMENODE_OPTS " $ mkdir -p /home/eagle/logs/hadoop-hdfs/ $ vim ~/software/hadoop/etc/hadoop/log4j.properties log4j.appender.RFAAUDIT.File=/home/eagle/logs/hadoop-hdfs/hdfs-audit.log $ ps auxwww | grep NameNode | grep 'hdfs.audit.logger' $ tail -f ~/logs/hadoop-hdfs/hdfs-audit.log $ bin/hdfs namenode -format 17/04/07 16:27:17 INFO util.ExitUtil: Exiting with status 0
伪分布式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ cd ~/software/hadoop/ $ bin/hdfs dfs -mkdir -p /user/hadoop $ bin/hdfs dfs -mkdir /user/hadoop/input $ bin/hdfs dfs -put etc/hadoop/*.xml /user/hadoop/input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+' $ bin/hdfs dfs -ls /user/hadoop/output/ -rw-r--r-- 1 eagle supergroup 0 2017-04-10 10:26 /user/hadoop/output/_SUCCESS -rw-r--r-- 1 eagle supergroup 97 2017-04-10 10:26 /user/hadoop/output/part-r-00000 $ bin/hdfs dfs -cat /user/hadoop/output/part-r-00000 1 dfsadmin 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.namenode.http 1 dfs.datanode.data.dir $ bin/hdfs dfs -get /user/hadoop/output ~/output
Yarn 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ cd ~/software/hadoop/ $ mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml $ vim etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> $ vim etc/hadoop/yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ sbin/start-dfs.sh $ jps -ml | grep -v jps 13196 org.apache.hadoop.hdfs.server.namenode.NameNode 13503 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 13329 org.apache.hadoop.hdfs.server.datanode.DataNode 31639 org.apache.catalina.startup.Bootstrap start 13685 sun.tools.jps.Jps -ml $ sbin/start-yarn.sh $ sbin/mr-jobhistory-daemon.sh start historyserver $ jps -ml | grep -v jps 3691 org.apache.hadoop.hdfs.server.namenode.NameNode 3995 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 3821 org.apache.hadoop.hdfs.server.datanode.DataNode 4271 org.apache.hadoop.yarn.server.nodemanager.NodeManager 4175 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 4671 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer 31639 org.apache.catalina.startup.Bootstrap start
LogStash 安装 1 2 3 4 5 6 7 8 9 $ tar zxvf logstash-2.3.4.tar.gz -C ~/software/ $ cd ~/software $ ln -s logstash-2.3.4/ logstash $ cd logstash $ bin/logstash-plugin list | grep output-kafka logstash-output-kafka
配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 $ mkdir -p /home/eagle/logs/hadoop-hdfs $ mkdir -p /home/eagle/logs/logstash $ mkdir conf $ vim conf/hdfs-audit.conf input { file { type => "cdh-nn-audit" path => "/home/eagle/logs/hadoop-hdfs/hdfs-audit.log" start_position => end sincedb_path => "/home/eagle/logs/logstash/logstash.log" } } filter{ if [type ] == "cdh-nn-audit" { grok { match => ["message" , "ugi=(?<user>([\w\d\-]+))@|ugi=(?<user>([\w\d\-]+))/[\w\d\-.]+@|ugi=(?<user>([\w\d.\-_]+))[\s(]+" ] } } } output { if [type ] == "cdh-nn-audit" { kafka { codec => plain { format => "%{message}" } bootstrap_servers => "localhost:9092" topic_id => "hdfs_audit_log" timeout_ms => 10000 retries => 3 client_id => "cdh-nn-audit" } } }
启动 1 2 3 4 $ nohup bin/logstash -f conf/hdfs-audit.conf > ~/logs/logstash/hdfs-audit.log 2>&1 & Settings: Default pipeline workers: 2 Pipeline main started $ tail -f ~/logs/logstash/hdfs-audit.log
ZooKeeper 安装 1 2 3 4 5 6 $ cd ~/install/ $ wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz $ tar zxvf zookeeper-3.4.10.tar.gz -C ~/software/ $ cd ~/software $ ln -s zookeeper-3.4.10 zookeeper
配置 1 2 3 4 5 6 7 8 $ cd zookeeper $ mkdir tmp $ cp conf/zoo_sample.cfg conf/zoo.cfg $ mkdir -p /home/eagle/data/zookeeper $ mkdir -p /home/eagle/logs/zookeeper $ vim conf/zoo.cfg dataDir=/home/eagle/data/zookeeper dataLogDir=/home/eagle/logs/zookeeper
启动 1 2 3 4 5 6 $ bin/zkServer.sh start $ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/eagle/software/zookeeper/bin/../conf/zoo.cfg Mode: standalone $ bin/zkCli.sh
Storm 安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ cd ~/install/ $ wget http://archive.apache.org/dist/storm/apache-storm-0.9.7/apache-storm-0.9.7.tar.gz $ tar zxvf apache-storm-0.9.7.tar.gz -C ~/software/ $ cd ~/software $ ln -s apache-storm-0.9.7 storm $ cd storm $ vim ~/.bashrc if [ -f /etc/bashrc ]; then . /etc/bashrc fi export HADOOP_HOME=~/software/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME /lib/native export JAVA_HOME=~/software/java export STORM_HOME=~/software/storm export PATH=$PATH :$HADOOP_HOME /sbin:$HADOOP_HOME /bin:$JAVA_HOME /bin:$STORM_HOME /bin $ source ~/.bashrc $ storm version 0.9.7
配置 1 2 3 4 5 6 7 $ vim conf/storm.yaml storm.zookeeper.servers: - "127.0.0.1" storm.zookeeper.port: 2181 nimbus.host: "127.0.0.1" ui.host: 0.0.0.0 ui.port: 8081
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ mkdir -p ~/logs/storm $ nohup bin/storm nimbus > ~/logs/storm/nimbus.log 2>&1 & $ nohup bin/storm supervisor > ~/logs/storm/supervisor.log 2>&1 & $ nohup bin/storm ui > ~/logs/storm/ui.log 2>&1 & $ jps -ml | grep -v jps 17557 backtype.storm.daemon.nimbus 17675 backtype.storm.daemon.supervisor 20403 backtype.storm.ui.core 17043 org.apache.zookeeper.server.quorum.QuorumPeerMain /home/eagle/software/zookeeper/bin/../conf/zoo.cfg 3691 org.apache.hadoop.hdfs.server.namenode.NameNode 3995 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 3821 org.apache.hadoop.hdfs.server.datanode.DataNode 4271 org.apache.hadoop.yarn.server.nodemanager.NodeManager 4175 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 4671 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer 15515 org.jruby.Main --1.9 /home/eagle/software/logstash/lib/bootstrap/environment.rb logstash/runner.rb agent -f conf/hdfs-audit.conf 7212 org.apache.catalina.startup.Bootstrap start $ bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.7.jar storm.starter.WordCountTopology | grep 'Thread-[0-9]*-count'
Kafka Scala依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 $ cd ~/install/ $ wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz --no-check-certificate $ tar zxvf scala-2.11.8.tgz -C ~/software/ $ cd ~/software/ $ ln -s scala-2.11.8/ scala $ vim ~/.bash_profile JAVA_HOME=/home/eagle/software/java SCALA_HOME=/home/eagle/software/scala CLASSPATH=.:$JAVA_HOME /lib/tools.jar PATH=$JAVA_HOME /bin:$SCALA_HOME /bin:$PATH export JAVA_HOME CLASSPATH PATH $ bash ~/.bash_profile
安装 1 2 3 4 5 6 $ cd ~/install/ $ wget http://archive.apache.org/dist/kafka/0.10.1.1/kafka_2.11-0.10.1.1.tgz $ tar zxvf kafka_2.11-0.10.1.1.tgz -C ~/software/ $ cd ~/software $ ln -s kafka_2.11-0.10.1.1 kafka
配置 1 2 3 4 5 6 7 8 9 $ cd kafka $ mkdir -p ~/logs/kafka $ vim config/zookeeper.properties dataDir=/home/eagle/data/zookeeper clientPort=2181 maxClientCnxns=0 $ vim config/server.properties log.dirs=/home/eagle/logs/kafka
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ nohup bin/kafka-server-start.sh config/server.properties > ~/logs/kafka/kafka.server.log 2>&1 & $ tail -f /home/eagle/software/hbase/logs/hbase-eagle-master-federation01.out $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hdfs_audit_log Created topic "hdfs_audit_log" . $ bin/kafka-topics.sh --list --zookeeper localhost:2181 hdfs_audit_log $ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic hdfs_audit_log $ ~/software/zookeeper/bin/zkCli.sh [zk: localhost:2181(CONNECTED) 19] get /consumers/console-consumer-51054/offsets/hdfs_audit_log/0 0 cZxid = 0x396 ctime = Tue Apr 11 15:59:22 CST 2017 mZxid = 0x396 mtime = Tue Apr 11 15:59:22 CST 2017 pZxid = 0x396 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 1 numChildren = 0
Eagle 编译 1 2 3 4 5 6 7 8 $ cd install $ wget http://archive.apache.org/dist/eagle/apache-eagle-0.4.0-incubating/apache-eagle-0.4.0-incubating-src.tar.gz $ tar zxvf apache-eagle-0.4.0-incubating-src.tar.gz $ cd apache-eagle-0.4.0-incubating-src $ curl -O https://patch-diff.githubusercontent.com/raw/apache/eagle/pull/268.patch $ git apply 268.patch $ mvn clean package -T 1C -DskipTests
安装 1 2 3 4 5 6 7 8 9 10 11 $ cd /home/eagle/install/ $ tar zxvf apache-eagle-0.4.0-incubating-bin.tar.gz -C /home/eagle/software/ $ cd /home/eagle/software/ $ ln -s apache-eagle-0.4.0-incubating/ eagle $ cd eagle $ bin/eagle-service.sh start Starting eagle service ... Existing PID file found during start. Removing/clearing stale PID file. Eagle service started.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 $ cd ~/software/eagle $ vim bin/eagle-env.sh export EAGLE_HOME=$(dirname $0 )/.. export JAVA_HOME=${JAVA_HOME} export EAGLE_NIMBUS_HOST=localhost export EAGLE_SERVICE_HOST=localhost export EAGLE_SERVICE_PORT=9099 export EAGLE_SERVICE_USER=admin export EAGLE_SERVICE_PASSWD=secret export EAGLE_CLASSPATH=$EAGLE_HOME /conf for file in $EAGLE_HOME /lib/share/*;do EAGLE_CLASSPATH=$EAGLE_CLASSPATH :$file done export EAGLE_STORM_CLASSPATH=$EAGLE_CLASSPATH for file in $EAGLE_HOME /lib/storm/*;do EAGLE_STORM_CLASSPATH=$EAGLE_STORM_CLASSPATH :$file done $ vim conf/eagle-scheduler.conf appCommandLoaderEnabled = false appCommandLoaderIntervalSecs = 1 appHealthCheckIntervalSecs = 5 envContextConfig.env = "storm" envContextConfig.url = "http://localhost:8081" envContextConfig.nimbusHost = "localhost" envContextConfig.nimbusThriftPort = 6627 envContextConfig.jarFile = "/home/eagle/software/eagle/lib/topology/eagle-topology-0.4.0-incubating-assembly.jar" eagleProps.mailHost = "mailHost.com" eagleProps.mailSmtpPort = "25" eagleProps.mailDebug = "true" eagleProps.eagleService.host = "localhost" eagleProps.eagleService.port = 9099 eagleProps.eagleService.username = "admin" eagleProps.eagleService.password = "secret" eagleProps.dataJoinPollIntervalSec = 30 dynamicConfigSource.enabled = true dynamicConfigSource.initDelayMillis = 0 dynamicConfigSource.delayMillis = 30000 $ vim conf/sandbox-hdfsAuditLog-application.conf { "envContextConfig" : { "env" : "storm" , "mode" : "cluster" , "topologyName" : "sandbox-hdfsAuditLog-topology" , "stormConfigFile" : "security-auditlog-storm.yaml" , "parallelismConfig" : { "kafkaMsgConsumer" : 1, "hdfsAuditLogAlertExecutor*" : 1 } }, "dataSourceConfig" : { "topic" : "hdfs_audit_log" , "zkConnection" : "127.0.0.1:2181" , "brokerZkPath" : "/brokers" , "zkConnectionTimeoutMS" : 15000, "fetchSize" : 1048586, "deserializerClass" : "org.apache.eagle.security.auditlog.HdfsAuditLogKafkaDeserializer" , "transactionZKServers" : "127.0.0.1" , "transactionZKPort" : 2181, "transactionZKRoot" : "/consumers" , "consumerGroupId" : "eagle.hdfsaudit.consumer" , "transactionStateUpdateMS" : 2000 }, "alertExecutorConfigs" : { "hdfsAuditLogAlertExecutor" : { "parallelism" : 1, "partitioner" : "org.apache.eagle.policy.DefaultPolicyPartitioner" , "needValidation" : "true" } }, "eagleProps" : { "site" : "sandbox" , "application" : "hdfsAuditLog" , "dataJoinPollIntervalSec" : 30, "mailHost" : "mailHost.com" , "mailSmtpPort" :"25" , "mailDebug" : "true" , "eagleService" : { "host" : "localhost" , "port" : 9099 "username" : "admin" , "password" : "secret" } }, "dynamicConfigSource" : { "enabled" : true , "initDelayMillis" : 0, "delayMillis" : 30000 } }
元数据存储 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ su - mysql $ mysql -uroot -p -S /home/mysql/data/mysql.sock create database eagle; $ su - eagle $ vim /home/eagle/software/eagle/conf/eagle-service.conf eagle { service { storage-type="jdbc" storage-adapter="mysql" storage-username="eagle" storage-password=eagle storage-database=eagle storage-connection-url="jdbc:mysql://mysql01:3306/eagle" storage-connection-props="encoding=UTF-8" storage-driver-class="com.mysql.jdbc.Driver" storage-connection-max=30 } }
启动 1 2 3 4 5 6 7 8 9 10 $ bin/eagle-service.sh start $ bin/eagle-service.sh status Eagle service is running 17789 $ bin/eagle-topology-init.sh $ bin/eagle-topology.sh start $ bin/eagle-topology.sh status Checking topology sandbox-hdfsAuditLog-topology status ... Topology is alive: sandbox-hdfsAuditLog-topology ACTIVE 7 1 18
至此大功告成~
Eagle 高级玩法 HBase Security Log HBase 部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 $ wget http://archive.apache.org/dist/hbase/hbase-0.98.8/hbase-0.98.8-hadoop2-bin.tar.gz $ tar zxvf hbase-0.98.8-hadoop2-bin.tar.gz -C ~/software/ $ cd ~/software $ ln -s hbase-0.98.8-hadoop2 hbase $ vim ~/.bashrc HBASE_HOME=~/software/hbase PATH=$HBASE_HOME /bin:$PATH $ source ~/.bashrc $ hbase version 2017-04-14 16:19:24,992 INFO [main] util.VersionInfo: HBase 0.98.8-hadoop2 $ ssh-keygen -t dsa -P '' -f /home/eagle/.ssh/id_dsa $ cd /home/eagle/.ssh $ cat id_rsa.pub > authorized_keys $ scp /home/eagle/.ssh/authorized_keys eagle@eagle02:/home/eagle/.ssh/ $ chmod 700 -R ~/.ssh $ chmod 600 ~/.ssh/authorized_keys $ vim conf/hbase-env.sh export JAVA_HOME=~/software/java export HBASE_MANAGES_ZK=false $ mkdir -p /home/eagle/data/hbase/tmp $ vim conf/hbase-site.sh <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://eagle01:9000/hbase</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true </value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>eagle01</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/eagle/data/zookeeper</value> </property> <property> <name>zookeeper.znode.parent</name> <value>/hbase</value> </property> <property> <name>hbase.tmp.dir</name> <value>/home/eagle/data/hbase/tmp</value> </property> </configuration>
开启 Security 日志 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 $ su - hbase $ cd ~/software/hbase/ $ vim conf/hbase-site.xml <property> <name>hbase.security.authentication</name> <value>simple</value> </property> <property> <name>hbase.security.authorization</name> <value>true </value> </property> <property> <name>hbase.coprocessor.master.classes</name> <value>org.apache.hadoop.hbase.security.access.AccessController</value> </property> <property> <name>hbase.coprocessor.region.classes</name> <value>org.apache.hadoop.hbase.security.access.AccessController</value> </property> <property> <name>hbase.coprocessor.regionserver.classes</name> <value>org.apache.hadoop.hbase.security.access.AccessController</value> </property> $ sudo mkdir -p /opt/hbase/logs/security/ $ sudo chown -R eagle:eagle /opt/hbase/ $ vim conf/log4j.properties hbase.security.log.file=SecurityAuth.audit hbase.security.log.maxfilesize=256MB hbase.security.log.maxbackupindex=20 log4j.appender.RFAS=org.apache.log4j.RollingFileAppender log4j.appender.RFAS.File=/opt/hbase/logs/security/security.log log4j.appender.RFAS.MaxFileSize=${hbase.security.log.maxfilesize} log4j.appender.RFAS.MaxBackupIndex=${hbase.security.log.maxbackupindex} log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n log4j.category.SecurityLogger=${hbase.security.logger} log4j.additivity.SecurityLogger=false log4j.logger.SecurityLogger.org.apache.hadoop.hbase.security.access.AccessController=TRACE $ bin/start-hbase.sh $ tail -f /opt/hbase/logs/security/security.log
Kafka 1 2 3 4 5 $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic hbase_security_log Created topic "hbase_security_log" . $ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hbase_security_log
LogStash 安装 参照上文 Eagle环境搭建 - LogStash 部分
配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 $ cd ~/software/logstash/ $ mkdir -p /data03/hbase/logs/logstash $ vim conf/hbase-security.conf input { file { type => "hbase-security-log" path => "/data03/hbase/logs/security/security.log" start_position => end sincedb_path => "/data03/hbase/logs/security/security_monitor.log" } } output { if [type ] == "hbase-security-log" { kafka { codec => plain { format => "%{message}" } bootstrap_servers => "eagle01:9092" topic_id => "hbase_security_log" timeout_ms => 10000 batch_size => 1000 retries => 3 client_id => "hbase-security-log" } } } $ nohup bin/logstash -f conf/hbase-security.conf > /home/eagle/logs/logstash/hbase_security.log 2>&1 & $ tail -f /data03/hbase/logs/logstash/hbase_security.log
Eagle 配置 1 2 3 4 5 $ vim conf/sandbox-hbaseSecurityLog-application.conf "dataSourceConfig" : { "topic" : "hbase_security_log" , // ... },
Eagle 提交 Topology 1 2 3 4 5 6 7 $ bin/eagle-topology.sh --main org.apache.eagle.security.hbase.HbaseAuditLogProcessorMain --config conf/sandbox-hbaseSecurityLog-application.conf start $ bin/eagle-topology.sh --topology sandbox-hbaseSecurityLog-topology status Checking topology sandbox-hbaseSecurityLog-topology status ... Topology is alive: sandbox-hbaseSecurityLog-topology ACTIVE 7 1 131 $ bin/eagle-topology.sh --topology sandbox-hbaseSecurityLog-topology stop
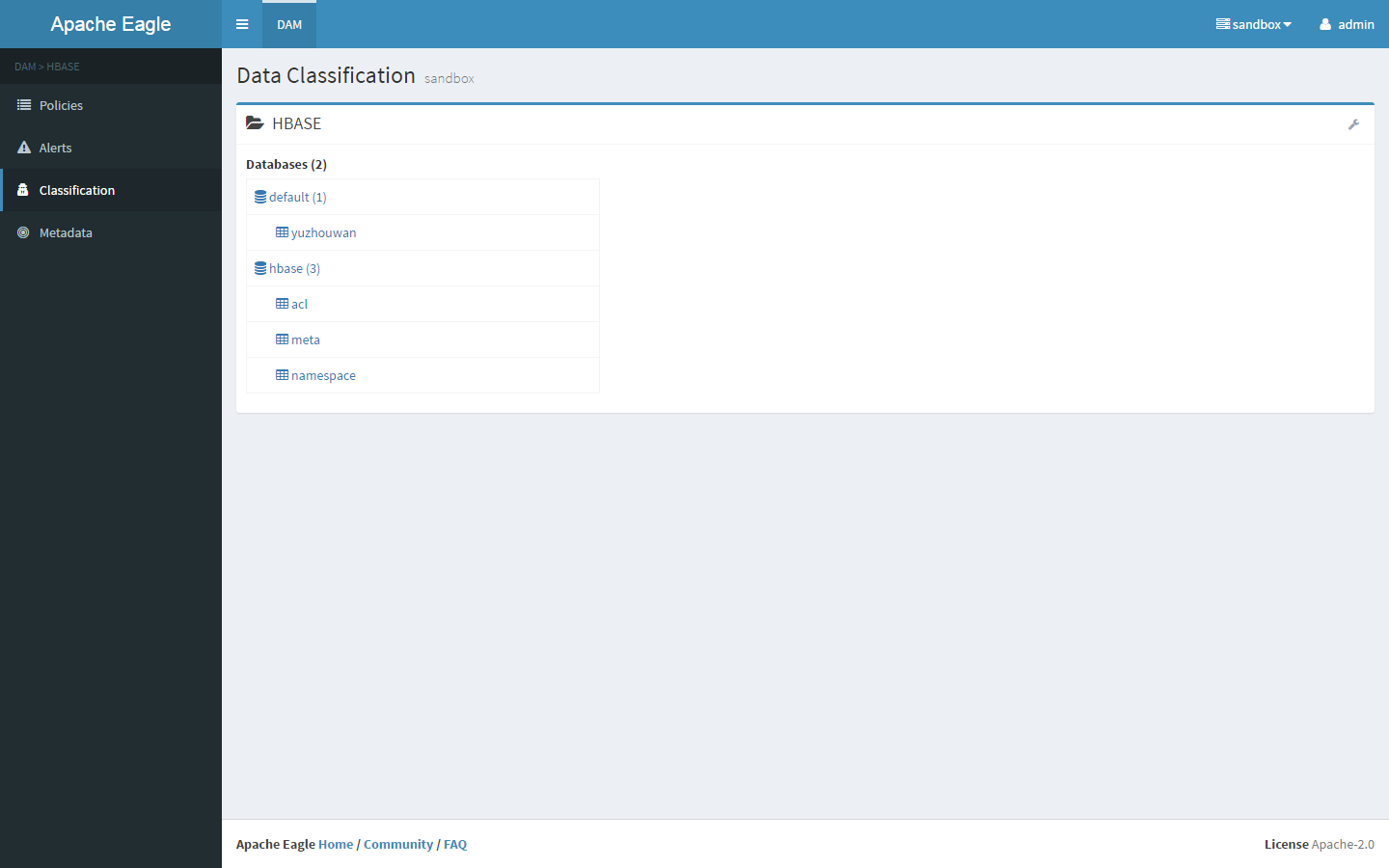
配置告警 在 Site 中配置好 HBase 的 hbaseSecurityLog application 之后,可以在 Data Classification 中看到如下界面Policy
参考
踩过的坑 RPM error: can’t create transaction lock on /var/lib/rpm/.rpm.lock (Permission denied) 解决 增加 sudo
参考
Maven zookeeper:jar:3.4.6.2.2.0.0-2041 无法从 Maven 中央仓库下载到描述 后面小版本说明并不是官方提供的 release 版本,是由 hortonworks 之类的第三方平台提供
1 2 3 $ mvn clean package -T 1C -DskipTests Failed to execute goal on project eagle-log4jkafka: Could not resolve dependencies for project org.apache.eagle:eagle-log4jkafka:jar:0.4.0-incubating: The following artifacts could not be resolved: org.apache.kafka:kafka_2.10:jar:0.8.1.2.2.0.0-2041, org.apache.zookeeper:zookeeper:jar:3.4.6.2.2.0.0-2041: Could not transfer artifact org.apache.kafka:kafka_2.10:jar:0.8.1.2.2.0.0-2041 from/to HDP Release Repository (http://repo.hortonworks.com/content/repositories/releases/): GET request of: org/apache/kafka/kafka_2.10/0.8.1.2.2.0.0-2041/kafka_2.10-0.8.1.2.2.0.0-2041.jar from HDP Release Repository failed: Connection reset -> [Help 1]
解决
通过 mvnrepository.com 进行查找,kafka_2.10-0.8.1.2.2.0.0-2041.jar 的确是存在可以下载,但是 zookeeper_3.4.6.2.2.0.0-2041.jar 并没有提供出来archive.apache.org 中,也只有标准的 Stable Release
自己编译 zookeeper_3.4.6.2.2.0.0-2041.jar
在 Hortonworks 的 github 分支中并没有提供源码,并且在 Release 页面中也找不到对应的版本
Apache Archive 中提供了 apache-eagle-0.4.0-incubating-src.tar.gz 源码
修改 hadoop.version 使得其依赖的 zookeeper 版本也跟着改变
-Dhadoop.version=<hadoop version> -Dhbase.version=<hbase version>mvn clean package -T 1C -DskipTests -Dhadoop.version=2.7.3
已提交 EAGLE-990 ,欢迎参与讨论
参考
maven-scala-plugin 版本过低 描述 1 2 3 [ERROR] Failed to execute goal org.scala-tools:maven-scala-plugin:2.15.0:compile (default) on project eagle-log4jkafka: wrap: org.apache.commons.exec.ExecuteExc eption: Process exited with an error: 1(Exit value: 1) -> [Help 1]
解决 1 2 3 $ vim apache-eagle-0.4.0-incubating-src/pom.xml <!--<maven-scala.version>2.15.0</maven-scala.version>--> <maven-scala.version>2.15.2</maven-scala.version>
rt.jar is broken 描述 1 2 [ERROR] error: error while loading AnnotatedElement, class file 'D:\apps\Java\jd k1.8.0_111\jre\lib\rt.jar(java/lang/reflect/AnnotatedElement.class)' is broken
解决 这个问题是因为 JDK 版本过高
1 2 3 4 5 $ set JAVA_HOME=D:\apps\Java\jdk1.7.0_67 $ set MAVEN_HOME=D:\apps\maven\apache-maven-3.3.9 $ set PATH=%JAVA_HOME%\bin;%MAVEN_HOME%\bin;%PATH%
参考
eagle-webservice 编译失败 描述 1 [ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.6.0:exec (exec-ui-install) on project eagle-webservice: Command execution failed. Cannot run program "bash" (in directory "F:\eagle\apache-eagle-0.4.0-incubating-src\eagle-webservice" ): CreateProcess error=2, ????????? -> [Help 1]
解决 没有安装 NPM
1 2 3 $ set NODE_HOME=D:\apps\nodejs\ $ set PATH=%NODE_HOME%;%PATH%
java.io.IOException: Cannot run program “bash” 解决 将 Git 的 bash.exe 目录配置到环境变量
1 $ set PATH=D:\apps\Git\bin;%PATH%
参考
Npm fetch 失败 解决 检查是否配置好代理
1 2 3 4 5 6 7 $ npm config set proxy "http://10.19.110.55:8080/" $ npm config set registry "https://registry.npm.taobao.org" $ vim C:\Users\BenedictJin\.npmrc proxy=http://10.19.110.55:8080/ registry=https://registry.npm.taobao.org
另外,如果 npm 调用了 bower 命令,仍然需要给 bower 进行代理设置
1 2 3 4 5 6 7 8 $ touch C:\Users\BenedictJin\.bowerrc $ vim C:\Users\BenedictJin\.bowerrc { "directory" : "bower_components" , "proxy" : "http://10.19.110.55:8080/" , "https-proxy" :"http://10.19.110.55:8080/" , "no-proxy" :"*.yuzhouwan.com" }
默认镜像地址:https://registry.npmjs.com/
application.conf: No such file or directory 描述 1 2 3 4 5 6 $ bin/eagle-service.sh start cp : cannot create regular file `bin/../lib/tomcat/webapps/eagle-service/WEB-INF/classes/application.conf': No such file or directory cp: cannot create regular file `bin/../lib/tomcat/webapps/eagle-service/WEB-INF/classes/' : No such file or directorycp : cannot create regular file `bin/../lib/tomcat/webapps/eagle-service/WEB-INF/classes/': No such file or directory Starting eagle service ... Eagle service started.
解决 可能是没有将 apache-eagle-0.4.0-incubating-src\eagle-webservice\target 中的 eagle-service.war 正常解压eagle-service 拷贝到 /home/eagle/software/eagle/lib/tomcat/webapps/ 中
BootStrap Invalid message received with signature 18245 描述 1 2 3 4 $ tail -f logs/eagle-service.2017-04-07.log Apr 07, 2017 10:59:25 AM org.apache.coyote.ajp.AjpMessage processHeader SEVERE: Invalid message received with signature 18245
解决 1 2 3 4 5 $ vim /home/eagle/software/eagle/lib/tomcat/conf/server.xml <Connector port="9009" protocol="AJP/1.3" address="0.0.0.0" redirectPort="9443" />
参考
MySQL Host eagle01 is not allowed to connect to this MySQL server 解决 远程连接 MySQL 服务实例的时候,如果当前主机没有响应权限,需要对其赋权
1 2 3 4 5 6 $ su - mysql $ mysql -uroot -p -S /home/mysql/data/mysql.sock CREATE USER 'eagle' @'192.168.1.30' IDENTIFIED BY 'eagle' ; GRANT ALL PRIVILEGES ON eagle.* TO 'eagle' @'192.168.1.30' IDENTIFIED BY 'eagle' WITH GRANT OPTION; FLUSH PRIVILEGES;
参考
Table ‘eagle.eagleapplicationdesc_eagleapplicationdesc’ doesn’t exist 解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 $ show tables; +---------------------------------------------------+ | Tables_in_eagle | +---------------------------------------------------+ | alertexecutor_alertexecutor | | alertstream_alertstream | | eagle_metadata_generic_resource | | eagle_metadata_topologyoperation | | eagle_metric | | eaglefeaturedesc_eaglefeaturedesc | | eaglesiteapplication_eaglesiteapplication | | eaglesitedesc_eaglesitedesc | | filesensitivity_filesensitivity | | hbaseresourcesensitivity_hbaseresourcesensitivity | | hdfsusercommandpattern_hdfsusercommandpattern | | hiveresourcesensitivity_hiveresourcesensitivity | | ipzone_ipzone | | mlmodel_mlmodel | | oozieresourcesensitivity_oozieresourcesensitivity | | serviceaudit_serviceaudit | | unittest_entityut | | unittest_testtsentity | | userprofile_schedule_command | +---------------------------------------------------+ $ cp eagle-examples/eagle-cassandra-example/bin/init.sh /home $ su - mysql $ mysql -uroot -p -S /home/mysql/data/mysql.sock use eagle; create table alertnotifications_alertnotifications( `uuid` varchar(254) COLLATE utf8_bin NOT NULL, `timestamp` bigint(20) DEFAULT NULL, `notificationType` varchar(30000), `enabled` tinyint(1) DEFAULT NULL, `description` mediumtext, `className` mediumtext, `fields` mediumtext, PRIMARY KEY (`uuid`), UNIQUE KEY `uuid_UNIQUE` (`uuid`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; create table eagle_metadata_topologydescription( `uuid` varchar(254) COLLATE utf8_bin NOT NULL, `timestamp` bigint(20) DEFAULT NULL, `topology` varchar(30000), `description` mediumtext, `exeClass` mediumtext, `type ` mediumtext, `version` mediumtext, PRIMARY KEY (`uuid`), UNIQUE KEY `uuid_UNIQUE` (`uuid`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; create table eagle_metadata_topologyexecution( `uuid` varchar(254) COLLATE utf8_bin NOT NULL, `timestamp` bigint(20) DEFAULT NULL, site varchar(1024), application varchar(1024), topology varchar(1024), environment varchar(1024), status varchar(1024), description varchar(1024), lastmodifieddate bigint(20), fullname varchar(1024), url varchar(1024), mode varchar(1024), PRIMARY KEY (`uuid`), UNIQUE KEY `uuid_UNIQUE` (`uuid`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; create table eagle_metric_dmeta( `uuid` varchar(254) COLLATE utf8_bin NOT NULL, `timestamp` bigint(20) DEFAULT NULL, drillDownPaths mediumtext, aggFunctions mediumtext, defaultDownSamplingFunction mediumtext, defaultAggregateFunction mediumtext, resolutions mediumtext, downSamplingFunctions mediumtext, storeType mediumtext, displayName mediumtext, PRIMARY KEY (`uuid`), UNIQUE KEY `uuid_UNIQUE` (`uuid`) )ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
ZooKeeper 1 2 3 4 5 6 $ bin/zkServer.sh start-foreground ZooKeeper JMX enabled by default Using config: /home/eagle/software/zookeeper/bin/../conf/zoo.cfg Error: Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain
Hadoop 端口冲突 解决 1 2 3 4 5 6 7 8 $ vim ~/software/hadoop/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.namenode.http-address</name> <value>0.0.0.0:50070</value> </property> </configuration>
参考
HBase FAILED LOOKUP: Can’t get master address from ZooKeeper; znode data == null 描述 1 2 3 hbase(main):001:0> zk_dump HBase is rooted at /hbase Active master address: <<FAILED LOOKUP: Can't get master address from ZooKeeper; znode data == null>>
解决 1 2 3 4 5 6 7 8 9 10 11 12 13 /home/eagle/software/hbase/bin/../logs/hbase-eagle-master-federation01.out $ vim ~/software/hbase/conf/hbase-env.sh export HBASE_MANAGES_ZK=false $ ~/software/zookeeper/bin/zkCli.sh -server eagle01:2181 [zk: localhost:2181(CONNECTED) 0] ls /hbase [recovering-regions, splitWAL, rs, backup-masters, region-in-transition, draining, table, table-lock]
The node /hbase-unsecure is not in ZooKeeper 解决 1 2 3 4 5 $ vim conf/hbase-site.xml <property> <name>zookeeper.znode.parent</name> <value>/hbase-unsecure</value> </property>
Storm ResourceManager : unable to find resource ‘templates/ALERT_DEFAULT.vm’ in any resource loader 描述 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ vim ~/software/storm/logs/worker-6703.log 2017-04-13T11:21:36.481+0800 o.a.velocity [ERROR] ResourceManager : unable to find resource 'templates/ALERT_DEFAULT.vm' in any resource loader. 2017-04-13T11:21:36.487+0800 o.a.e.c.e.EagleMailClient [INFO] Send mail failed, got an AddressException: Illegal whitespace in address javax.mail.internet.AddressException: Illegal whitespace in address at javax.mail.internet.InternetAddress.checkAddress(InternetAddress.java:926) ~[stormjar.jar:na] at javax.mail.internet.InternetAddress.parse(InternetAddress.java:819) ~[stormjar.jar:na] at javax.mail.internet.InternetAddress.parse(InternetAddress.java:555) ~[stormjar.jar:na] at javax.mail.internet.InternetAddress.<init>(InternetAddress.java:91) ~[stormjar.jar:na] at org.apache.eagle.common.email.EagleMailClient._send(EagleMailClient.java:101) [stormjar.jar:na] at org.apache.eagle.common.email.EagleMailClient.send(EagleMailClient.java:171) [stormjar.jar:na] at org.apache.eagle.common.email.EagleMailClient.send(EagleMailClient.java:192) [stormjar.jar:na] at org.apache.eagle.common.email.EagleMailClient.send(EagleMailClient.java:198) [stormjar.jar:na] at org.apache.eagle.notification.email.AlertEmailSender.run(AlertEmailSender.java:162) [stormjar.jar:na] at java.util.concurrent.Executors$RunnableAdapter .call(Executors.java:471) [na:1.7.0_80] at java.util.concurrent.FutureTask.run(FutureTask.java:262) [na:1.7.0_80] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [na:1.7.0_80] at java.util.concurrent.ThreadPoolExecutor$Worker .run(ThreadPoolExecutor.java:615) [na:1.7.0_80] at java.lang.Thread.run(Thread.java:745) [na:1.7.0_80]
解决 从编译好的 eagle-core 组件中,找到 eagle-alert/eagle-alert-notification-plugin/target/classes 目录,将 ALERT_DEFAULT.vm 文件 copy 到 部署环境的 /home/eagle/software/eagle/lib/tomcat/webapps/eagle-service/templates 目录下
参考
LogStash ArgumentError: The “sincedb_path” argument must point to a file, received a directory 解决 Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member 描述 1 WARN Auto offset commit failed for group console-consumer-87542: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records. (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
解决 1 2 3 4 5 6 kafka { codec => plain { format => "%{message}" } bootstrap_servers => "eagle01:9092" topic_id => "hbase_security_log" batch_size => "1000" }
参考
Eagle java.lang.Exception: Exception When browsing Files in HDFS .. Message : java.net.UnknownHostException: sandbox.hortonworks.com 解决 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 $ vim conf/sandbox-hadoopjmx-pipeline.conf { config { envContextConfig { "topologyName" : "sandbox-hadoopjmx-pipeline" } eagleProps { "site" : "sandbox" "application" : "HADOOP" } } dataflow { KafkaSource.hadoopNNJmxStream { parallism = 1000 topic = "nn_jmx_metric_sandbox" zkConnection = "localhost:2181" zkConnectionTimeoutMS = 15000 consumerGroupId = "Consumer" fetchSize = 1048586 transactionZKServers = "localhost" transactionZKPort = 2181 transactionZKRoot = "/consumers" transactionStateUpdateMS = 2000 deserializerClass = "org.apache.eagle.datastream.storm.JsonMessageDeserializer" } Alert.hadoopNNJmxStreamAlertExecutor { upStreamNames = [hadoopNNJmxStream] alertExecutorId = hadoopNNJmxStreamAlertExecutor } hadoopNNJmxStream -> hadoopNNJmxStreamAlertExecutor{} } }
解决 1 2 3 4 5 6 classification.fs.defaultFS=hdfs://eagle01:9000
Topology with name sandbox-hdfsAuditLog-topology already exists on cluster 解决 1 2 3 $ bin/eagle-topology.sh stop $ bin/eagle-topology.sh start
Error:(22, 38) java: 程序包 org.apache.eagle.service.hbase 不存在 解决 本地运行单元测试 TestHBaseWriteEntitiesPerformance 的时候,报错 import 的某些包不存在
这里可能需要设置 Maven 的 Proxy 代理,详见我的另一篇博客《Maven 高级玩法 》
社区跟进
详见:《如何成为 Apache 的 PMC 》
资源 Doc
群名称
群号
人工智能(高级)
人工智能(进阶)
BigData
算法