Algorithm
LeetCode 组队刷题活动
介绍
代码仓库
代码仓库的坐标:asdf2014 / algorithm
报名途径
只需要在《Algorithm》文末的评论区,或者在 issues#40 中留言,即可随时参与
参与方式
每位参与的小伙伴,都会获得代码仓库的 Collaborator 权限,可以自由地提交代码(不限制语种)。在 /Codes/${你的 Github 账号名} 目录下,每人都将拥有一个自己的代码库。留下 Github 名称后,将很快会收到邀请函,大家可以在 asdf2014 - algorithm - invitations 链接中认领(当然,也欢迎直接通过提交 Pull Request 参与进来)。随后,可以在任意目录下(不需要是空目录),使用如下命令,一键完成你的第一次代码提交:
1 | bash -c "$(curl -L https://raw.githubusercontent.com/asdf2014/algorithm/master/first_commit.sh)" |
刷题频率
考虑到可能大家的闲暇时间并不多,我们暂定刷题频率为“一周一题”
选题策略
选题机器人会在每周五晚八点,自动地随机选定一个题目,当前题目点击这里查看。
其他
操作 Git 时遇到问题的话,可以参考我的一篇博客《Git 高级玩法》
同时,为了大家更加方便地交流,也欢迎加入算法 QQ 群  或者 Gitter 聊天室
或者 Gitter 聊天室 
另外,因为大部分算法都会有很多实现思路,我们会尽可能地展现所有可能的解题方法。但为了文章的排版更加地紧凑,我们会将同一算法的不同实现,通过选项卡的形式展现。且默认展示的选项卡将会是最优解。这样的话,如果你想要快速阅读本文,则可以不用翻看其他的选项卡。实际效果如下:
迭代解
1 | def solution(n): |
递归解
1 | def solution(n): |
动态规划解
1 | def solution(n): |
进度
截止目前为止,活跃的小伙伴数量:



排行榜
排行榜的更新会在提交后自动执行,最新的榜单点击这里查看。
基础概念
复杂度

| 名称 | 运行时间 | 运行时间举例 | 算法举例 |
|---|---|---|---|
| 常数时间 | $O(1)$ | 10 | 判断一个二进制数的奇偶 |
| 反阿克曼时间 | $O(\alpha (n))$ | 并查集的单个操作的平摊时间 | |
| 迭代对数时间 | $O(\log ^{\ast}n)$ | 分布式圆环着色问题 | |
| 对数对数时间 | $O(\log \log n)$ | 有界优先队列的单个操作 | |
| 对数时间 | $O(\log n)$ | $\log n$,$\log n^{2}$ | 二分搜索 |
| 幂对数时间 | $(\log n)^{O(1)}$ | $(\log n)^{2}$ | |
| 幂时间(小于 1 次) | $O(n^{c})$,$0<c<1$ | $n^{\frac {1}{2}}$,$n^{\frac {2}{3}}$ | K-d 树的搜索操作 |
| 线性时间 | $O(n)$ | $n$ | 无序数组的搜索 |
| 线性迭代对数时间 | $O(n\log ^ {\ast}n)$ | 莱姆德·赛德尔的三角分割多边形算法 | |
| 线性对数时间 | $O(n\log n)$ | $n\log n$ | 最快的比较排序 |
| 二次时间 | $O(n^{2})$ | $n^{2}$ | 冒泡排序、插入排序 |
| 三次时间 | $O(n^{3})$ | $n^{3}$ | 矩阵乘法的基本实现 |
| 多项式时间 | $2^{O(\log n)}=n^{O(1)}$ | $n$,$n\log n$,$n^{10}$ | 线性规划中的卡马卡算法,AKS 质数测试 |
| 准多项式时间 | $2^{(\log n)^{O(1)}}$ | 关于有向斯坦纳树问题最著名的 $O(\log ^{2}n)$ 近似算法 | |
| 次指数时间(第一定义) | $O(2^{n^{\epsilon }})$,ε > 0 | $O(2^{(\log n)^{\log \log n}})$ | 假设复杂性理论推测,BPP 包含在 SUBEXP 中 |
| 次指数时间(第二定义) | $2^{o(n)}$ | $2^{n^{\frac1{3}}}$ | 用于整数分解与图形同构问题的著名算法 |
| 指数时间 | $2^{O(n)}$ | $1.1^n$,$10^n$ | 使用动态规划解决旅行推销员问题 |
| 阶乘时间 | $O(O!)$ | $n!$ | 通过暴力搜索解决旅行推销员问题 |
| 指数时间 | $2^{poly(n)}$ | $2^n, 2^{n^2}$ | |
| 双重指数时间 | $2^{2^{poly(n)}}$ | $2^{2^n}$ | 在预膨胀算术中决定一个给定描述的真实性 |
经典算法
String Matching
种类
朴素算法(Naive Algorithm)
Rabin-Karp 算法
有限自动机算法(Finite Automation)
KMP
KMP,Knuth-Morris-Pratt 匹配算法
Boyer-Moore 算法
Simon 算法
Colussi 算法
Galil-Giancarlo 算法
Apostolico-Crochemore 算法
Horspool 算法
Sunday 算法
实战
string-to-integer-atoi
正则匹配解
1 | import re |
letter-combinations-of-a-phone-number
算术解
1 | chars = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z" ] |
valid-parentheses
堆栈解
1 | def valid_parentheses(s: str) -> bool: |
zigzag-conversion
纯数学解
1 | def zigzag_conversion(s, num_rows): |
爬格子解
1 | def zigzag_conversion(s, num_rows): |
参考
Book
- 《柔性字符串匹配》
Sorting Algorithm
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | $O(n^2)$ | $O(n^2)$ | $O(n)$ | $O(1)$ | 稳定 |
| 选择排序 | $O(n^2)$ | $O(n^2)$ | $O(n)$ | $O(1)$ | 不稳定 |
| 插入排序 | $O(n^2)$ | $O(n^2)$ | $O(n)$ | $O(1)$ | 稳定 |
| 堆排序 | $O(n \log n)$ | $O(n \log n)$ | $O(n \log n)$ | $O(1)$ | 不稳定 |
| 归并排序 | $O(n \log n)$ | $O(n \log n)$ | $O(n \log n)$ | $O(n)$ | 稳定 |
| 快速排序 | $O(n \log n)$ | $O(n^2)$ | $O(n \log n)$ | $O(\log n)$ | 不稳定 |
| 希尔排序 | $O(n \log^2 n)$ | $O(n^2)$ | $O(n)$ | $O(1)$ | 不稳定 |
| 计数排序 | $O(n + m)$ | $O(n + m)$ | $O(n + m)$ | $O(n + m)$ | 稳定 |
| 基数排序 | $O(k \times n)$ | $O(n^2)$ | $O(k \times n)$ | $O(n)$ | 稳定 |
- 均按从小到大排列
- k:数值中的“数位”个数
- n:数据规模
- m:数据的最大值减最小值
参考
Dynamic Programming
定义
动态规划(DP,Dynamic Programming),是一种通过把原问题分解为相对简单的子问题,以求解复杂问题的方法
关键概念
状态
用来描述该问题的子问题的解
状态转移方程
状态和状态之间的关系式
例如,可以将斐波那契数列表示为:
递推
每个阶段只有一个状态
贪心
每个阶段的最优状态,都是由上一个阶段的最优状态得到的
搜索
每个阶段的最优状态,是由之前所有阶段的状态的组合得到的
动态规划
每个阶段的最优状态,可以从之前某个阶段的某个或某些状态直接得到,而不管之前这个状态是如何得到的
最优子结构
每个阶段的最优状态,可以从之前某个阶段的某个或某些状态直接得到
无后效性
不管之前这个状态是如何得到的
实战
longest-palindromic-substring
S(n) = $O(1)$ 解
1 | def longest_palindromic_substring(s): |
regular-expression-matching
动态规划解
1 | def regular_expression_matching(s, p): |
generate-parentheses
动态规划解
1 | def generate_parentheses(n: int) -> [str]: |
参考
Hash
哈希冲突
开放式寻址
线性探测法
从发生冲突的地址起,依次判断下一个地址是否为空,直到碰到空闲的地址
直接定址法
取关键字 $k$ 或者 $k$ 的某个线性函数值($a \cdot k + b$)作为哈希地址
二次探测法
以关键字 $k$ 或者 $k$ 加上某个常数的平方($k + 1^2$、$k + 2^2$、$k + 3^2$ $\dots$)作为哈希地址
伪随机数法
采用一个伪随机数当作哈希函数
双重哈希法
双重哈希是用于开放寻址最好的方法之一,散列函数如下:
为了能查找整个散列表,值 $h_2(k)$ 需要与表的大小 $T$ 互质。为确保这一条件成立,可采用以下两种方法
- 取 $T$ 为 2 的幂,并设计一个总产生奇数的 $h_2$
- 取 $T$ 为质数,并设计一个总是产生较 $T$ 小的正整数的 $h_2$
关键字分析
数字分析法
提取关键字中,取值比较均匀的数字作为哈希地址
平方取中法
如果关键字各个部分的分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址
分段叠加法
按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果,即可作为该关键字的哈希地址
冲突转移
拉链法
拉链法,又称链接地址法,是将哈希值相同的元素构成一个同义词的单链表
公共溢出区
将哈希表分为公共区和溢出区,当发生溢出时,将所有溢出数据统一写入到溢出区
实战
two-sum
T(n) = S(n) = $O(n)$ 解
1 | def two_sum(nums, target): |
参考
Linked List
种类
单向链表

快慢指针法
该方法常用于解决查找单向链表的中点、判断链表是否存在环等问题。大体思路便是,设计一快一慢两个指针,记做 fast 和 slow。同时,控制 fast 的速度是 slow 的两倍(如,fast = fast.next.next; slow = slow.next)。这样,可以保证当 fast 到达链表尾部的时候,slow 刚好在链表中间
双向链表

循环链表

性能对比
| Linked list | Array | Dynamic array | Balanced tree | Random access list | Hashed array tree | |
|---|---|---|---|---|---|---|
| Indexing | $O(n)$ | $O(1)$ | $O(1)$ | $O(\log n)$ | $O(\log n)$ | $O(1)$ |
| Insert/delete at beginning | $O(1)$ | N/A |
$O(n)$ | $O(\log n)$ | $O(1)$ | $O(n)$ |
| Insert/delete at end | $O(1)$ when last element is known; $O(n)$ when last element is unknown |
N/A |
$O(1)$ amortized | $O(\log n)$ | $O(\log n)$ updating | $O(1)$ amortized |
| Insert/delete in middle | search time + $O(1)$ | N/A |
$O(n)$ | $O(\log n)$ | $O(\log n)$ updating | $O(n)$ |
| Wasted space (average) | $O(n)$ | 0 |
$O(n)$ | $O(n)$ | $O(n)$ | $O(\sqrt{n})$ |
实战
add-two-numbers
T(n) = $O(n)$ 解
1 | def add_two_numbers(left, right): |
remove-nth-node-from-end-of-list
遍历解
1 | def remove_nth_node_from_end_of_list(head: ListNode, n: int) -> ListNode: |
merge-two-sorted-lists
遍历解
1 | def merge_two_sorted_lists(l1: ListNode, l2: ListNode) -> ListNode: |
Sliding Window
说明
滑动窗口算法,主要用于解决数组或者字符串的子元素问题。它可以将嵌套的循环问题,转换为单循环问题,从而降低时间复杂度
实战
longest-substring-without-repeating-characters
T(n) = S(n) = $O(n)$ 解
1 | def longest_substring_without_repeating_characters(s): |
Math
实战
reverse-integer
纯数学的方式
1 | def reverse_integer(x): |
字符串切片
1 | def reverse_integer(x): |
palindrome-number
纯数学的方式
1 | def palindrome_number(x): |
字符串反转
1 | def palindrome_number(x): |
roman-to-integer
纯数学的方式
1 | d = {"I": 1, "V": 5, "X": 10, "L": 50, "C": 100, "D": 500, "M": 1000} |
字符串替换
1 | d = {"I": 1, "V": 5, "X": 10, "L": 50, "C": 100, "D": 500, "M": 1000} |
3sum
基于 2sum 的思路
1 | def sum3(nums): |
预测算法
简易平均法
算术平均值
加权平均值
移动平均法
指数平滑法
参考
- 指数平滑
- Elasticsearch Holt-Winters
- 外卖订单量预测异常报警模型实践
- Holt-Winters 模型原理分析及代码实现(python)
- 时间序列挖掘 - 预测算法 - 三次指数平滑法(Holt-Winters)
线性回归法
分类算法
贝叶斯(Bayes)
描述
其中,$P(A \mid B)$ 是在 $B$ 发生的情况下 $A$ 发生的可能性,称为 $A$ 的后验概率。相应的,$P(B \mid A)$ 则称为 $B$ 后验概率;$P(A)$ 是不考虑任何 $B$ 方面的因素下 $A$ 发生的可能性,称为 $A$ 的先验概率(或边缘概率)。相应的,$P(B)$ 则称为 $B$ 的先验概率
种类
特征独立性
按照特征之间独立性的强弱,可以分为 朴素贝叶斯、半朴素贝叶斯、(一般的)贝叶斯 等
分布情况
按照属性和特征的分布情况,又可以分为 高斯贝叶斯、多项式贝叶斯、伯努利贝叶斯 等
离散程度
按照训练集的离散程度,还可以分为 离散型贝叶斯、连续型贝叶斯、混合型贝叶斯 等
编码实战
The set A contains 30 a and 10 b, and the set B contains 20 a and 20 b, then what is the value of P(A|a)?
1 | situations = dict() |
补充
当存在多个特征变量时,表达式可扩展为
其中,$\frac{1}{Z}$ 是一个只与 $F_i$ 相关的缩放因子,且当特征变量的值固定时,$\frac{1}{Z}$ 为常量
支持向量机(SVM)
- 感知机追求最大程度正确划分,最小化错误,但相对容易造成过拟合
- 支持向量机追求在大致正确分类的同时,最大化 margin,一定程度上避免了过拟合。但是由于 SVM 是借助二次规划来求解支持向量,而求解二次规划将涉及 m 阶矩阵的计算(m 为样本的个数)。所以当 m 的数目很大时,该矩阵的存储将消耗大量的机器资源,且运算的时间成本也会很高
聚类算法
K-means
介绍
输入聚类个数 k,以及包含 n 个数据对象的数据库,输出满足方差最小标准 k 个聚类的一种算法
步骤
- 从 n 个数据对象任意选择 k 个对象作为初始聚类中心
- 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分
- 重新计算每个(有变化)聚类的均值(中心对象)
- 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到第二步
基数估算
非概率算法
BitMap
Roaring Bitmap
Bloom filter
双层字典码
概率算法
Count-Mean-Min Sketch
LogLog Counting
Linear Counting
LogLog Counting
Adaptive Counting
HyperLogLog Counting
1 | m = 2 ^ b # with b in [4...16] |
HyperLogLog++
MinHash
HyperLogLog++ & Inclusion-exculsion principle
HyperLogLog++ & MinHash
参考
Blog
- Bitmap 的原理和实现
- EWAHCompressedBitmap 数据结构及原理
- Roaring Bitmap 数据结构及原理
- Using Bitmaps to Perform Range Queries
- JVM 上最快的 Bloom filter 实现
- 解读 Cardinality Estimation 算法
- Sketch of the Day:HyperLogLog — Cornerstone of a Big Data Infrastructure
- Sketch of the Day:Probabilistic Counting with Stochastic Averaging(PCSA)
- 分布式缓存 Redis 之 HyperLogLog
- Top K 频繁项
Github
- A compressed alternative to the Java BitSet class
- RoaringBitmap:A better compressed bitset in Java
- Sketches Library from YAHOO
- Stream summarizer and cardinality estimator
- The following estimating results is calculated using bitmap with length of 2^16 (64k) bytes
数据库相关
Binary Search
二分查找(Binary Search,也称折半搜索、对数搜索),是一种在有序数组中查找某一特定元素的搜索算法
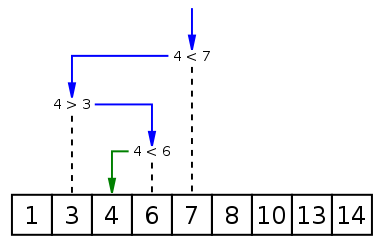
| 时间复杂度 | T(n) / S(n) |
|---|---|
| 平均 | $O(\log n)$ |
| 最优 | $O(1)$ |
| 最坏 | $O(\log n)$ |
| 最坏 | 迭代:$O(1)$;递归:$O(\log n)$(无尾调用消除) |
实战
median-of-two-sorted-arrays
Merge Sort 解
1 | def median_of_two_sorted_arrays(nums1, nums2): |
二叉查找树
平衡二叉树
AVL 树
红黑树
B 树
B+ 树
参考
- AVL 树,红黑树,B 树,B+ 树,Trie 树都分别应用在哪些现实场景中?
- 平衡二叉树、B 树、B+ 树、
B*树,理解其中一种你就都明白了 - 二叉查找树、平衡二叉树、红黑树、B- / B+ 树 性能对比
SnapTreeMap
参考
- nbronson / snaptree
- use SnapTreeMap instead of ConcurrentSkipListMap #6719
- Cassandra 2.1: now over 50% faster
LSM tree
参考
- 深入理解 HBase 的系统架构
- HBase 优化案例分析:Facebook Messages 系统问题与解决方案
- TokuDB 数据结构 Fractal-Trees 与 LSM-Trees 对比
- WiscKey: Separating Keys from Values in SSD-conscious Storage
- B+ Tree、LSM、Fractal tree index 读写放大分析
前缀树
Tire Tree + Double Array + Aho-Corasick
参考
- Trie 树分词
- 双数组 Trie 树(DoubleArrayTrie)Java 实现
- Aho-Corasick 算法的 Java 实现与分析
- Aho-Corasick 自动机结合 DoubleArrayTrie 极速多模式匹配
Patricia Tree
SlimTire
参考
- SlimTrie: 单机百亿文件的极致索引
- openacid / slim
- wikipedia: SlimTrie
图论
图计算
概念
图计算是以图论为基础的对现实世界的一种图结构的抽象表达,以及在这种数据结构上的计算模式。通常,在图计算中,基本的数据结构表达就是:
$G = (V, E, D)$,其中,V = vertex(顶点或者节点),E = edge(边),D = data(权重)
比如说:对于一个消费者的原始购买行为,有两类节点:用户和产品,边就是购买行为,权重是边上的一个数据结构,可以是购买次数和最后购买时间。对于许多我们面临的物理世界的数据问题,都可以利用图结构的来抽象表达:比如社交网络,网页链接关系,用户传播网络,用户网络点击、浏览和购买行为,甚至消费者评论内容,内容分类标签,产品分类标签等等
加密
GPG
1 | # 安装 |
压缩算法
ZSTD
参考
遗传算法
参考
- A Genetic Selection Algorithm for OLAP Data Cubes
- Towards reducing the multidimensionality of OLAP cubes using the Evolutionary Algorithms and Factor Analysis Methods
人工智能
详见,我的另一篇博客《人工智能》
Index
| 序号 | 标题 | 分类 |
|---|---|---|
| 1 | Two Sum | Hash |
| 2 | Add Two Numbers | Linked List |
| 3 | Longest Substring Without Repeating Characters | Sliding Window |
| 4 | Median of Two Sorted Arrays | Binary Search |
| 5 | Longest Palindromic Substring | Dynamic Programming |
| 6 | ZigZag Conversion | String |
| 7 | Reverse Integer | Math |
| 8 | String to Integer (atoi) | Math & String |
| 9 | Palindrome Number | Math |
| 10 | Regular Expression Matching | String & Dynamic Programming & Backtracking |
| 11 | Container With Most Water | Array & Two Pointers |
| 12 | Integer to Roman | Math & String |
| 13 | Roman to Integer | Math & String |
| 14 | Longest Common Prefix | String |
| 15 | 3Sum | Array & Two Pointers |
| 16 | 3Sum Closest | Array & Two Pointers |
| 17 | Letter Combinations of a Phone Number | String & Backtracking |
| 18 | 4Sum | Array & Hash Table & Two Pointers |
| 19 | Remove Nth Node From End of List | Linked List & Two Pointers |
| 20 | Valid Parentheses | String & Stack |
| 21 | Merge Two Sorted Lists | Linked List |
| 22 | Generate Parentheses | String & Dynamic Programming & Backtracking |
Tips: 出于文章篇幅的考虑,更多题解详见:https://github.com/asdf2014/algorithm/tree/master/Codes/asdf2014
资源
Blog
Book
- Data Structures and Algorithms with Python
- Data Structures and Algorithms in Python
- 背包九讲
Paper
Github
Tool
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| BigData | |
| 算法 |