人工智能
什么是人工智能
人工智能(Artificial Intelligence, AI)亦称机器智能,是指由人工制造出来的系统所表现出来的智能。 — wikipedia.org
从深蓝到 AlphaZero,再到 StyleGAN 和 GPT,人工智能的智力水平、学习能力和普适性,正在以爆炸式地速度快速发展;
从棋类到医学,再到绘画和聊天,人工智能开始在各类应用领域大展身手;
从 CPU 到 GPU,再到 TPU 和 IPU,人工智能的计算能力正向着无法穷举的极限不断逼近 …
但是,我们并不浮躁,踏踏实实地点亮 AI 知识树的每个枝叶,才是我们每位富有科学精神的人所应该做的
关于本文
我们将分为三块对 AI 进行诠释
首先,将介绍人工智能的主流思想和实用技巧,通过一些耳熟能详的有趣定理,我们可以对人工智能有些直观、初步的认识;随后,言归正传,我们将开始接触 AI 领域的几大理论支柱,由浅入深地学习 统计学、微积分、线性代数、概率论 等知识体系;最后,落地到实践,我们需要紧跟人工智能的技术发展前沿,对重大的突破性项目进行了解、学习,以及运用。如此,对人工智能领域进行横向分层,可以很方便地找到我们学习的突破点
不过,出于文章编排的考虑,可能部分编码就要放在其他博文中了,如有不便,还望见谅(Python、Prolog、R、Java)。本文持续更新中,若有不妥之处,还请不吝赐教哈 (^o^)/
主流思想
演绎法 & 溯因法 & 归纳法

实用技巧
Occam 剃刀原理
奥卡姆剃刀(Occam´s Razor),意为简约之法,是由 14 世纪逻辑学家、圣方济各会修士奥卡姆的威廉提出的一个解决问题的法则,即"切勿浪费较多资源,去做'用较少的资源,同样可以做好'的事情",相同思想见于郑板桥的删繁就简三秋树
在机器学习中的解释,就是 在所有可能选择的模型中,能够很好地解释已知数据且十分简单的才是最好的模型。并由此引入了正则化的理念。正则化方法的思想是,处理最优化函数问题时,在目标函数中加入对参数的约束惩罚项,从而达到简化模型的目的。其中,L0,L1 和 L2 范数 指的就是三种不同惩罚函数的形式,用数学公式来表达就是 $L_p$ = $\mid\mid\beta\mid\mid_p$ = $(\mid \beta_1 \mid ^p + \mid \beta_2 \mid^p$ $+ \ldots +$ $\mid\,\beta_n \mid^p)^{\frac1p}$
- L0 范数 是指向量中非 0 元素的个数(如果我们用 L0 范数来规则化一个参数矩阵 W 的话,就是希望 W 的大部分元素都是 0,即让参数矩阵 W 是稀疏的)
- L1 范数 是指向量中各系数绝对值之和(又称为 LASSO)
- L2 范数 是指向量中各系数平方和的平方根(在计量经济学里面,它又被称为岭回归)
大数定律
大数定律又称大数法则、大数律,是描述相当多次数重复实验的结果的定律。根据这个定律知道,样本数量越多,则其平均就越趋近期望值
在概率论中,细分为弱大数定律和强大数定律
前要定义
独立同分布的随机变量序列:$X_1, X_2, \dots, X_n$
样本均值:$M_n = \frac{ \sum_{i=1}^nX_i }n$
当样本量很大的时候,从 $X$ 抽取的样本平均值:$E[X]$(可得,$E[M_n] = \mu$)
设在某一试验中,$A$ 是一个事件,满足条件 $P(A) > 0$,又设 $X$ 和 $Y$ 是在同一个试验中的两个随机变量。若 $X$ 和 $Y$ 相互独立,则 $var(X + Y) =$ $var(X) + var(Y)$(可得,$var(M_n) = \frac{ \sigma^2 }n$)
弱大数定律
设 $X_1, X_2, \dots, X_n$ 独立同分布,其公共分布的均值为 $\mu$,则对任意的 $\epsilon \gt 0$,当 $n \to +\infty$ 时,$P(\mid M_n - \mu \mid \ge \epsilon) = $ $P(\mid \frac{ \sum_{i=1}^n{X_i} }n - \mu\,\mid$ $ \ge \epsilon) \to 0$
弱大数定律出给的结论是,$M_n$ 落在 $[\mu - \epsilon, \mu + \epsilon]$ 区间(即 $\mu$ 的 $\epsilon$ 邻域)内的概率会非常大(也可以表述为 “$M_n$ 收敛于 $\mu$”)。同时可以看出,随着 $n$ 值的增大,$M_n$ 落在 $\mu$ 邻域内的概率也会变大
强大数定律
设 $X_1, X_2, \dots, X_n$ 是均值为 $\mu$ 的独立同分布随机变量序列,则样本均值 $M_n$ 以概率 $1$ 收敛于 $\mu$,即 $P(\lim_{n \to +\infty}M_n = \mu) = 1$
在无穷序列中,弱大数定律无法给出到底存在多少元素显著性偏离了 $\mu$。而利用强大数定律则可得出,$M_n$ 以概率 $1$(即几乎处处)收敛于 $\mu$ 的结论,意味着对于任何 $\epsilon \gt 0$,偏离 $\mid M_n - \mu\mid$ 超过 $\epsilon$ 的元素只会存在有限多个
统计学
什么是统计学
统计学(Statistics)是一套用以收集数据、分析数据和由数据得出结论的概念、原则和方法。 — Gudmund R.Iversen
主要思想
随机性 & 规律性
随机性,指不能预测某一特定事件的结果
规律性,指从大量的收集数据中发现的模式
可以说,统计就是在随机性中寻找规律性
数据集描述
数据分布中心
均值(Mean)
算术平均值:$\mu = \frac{ \Sigma X }N$ 或 $\bar x = \frac{ \sum_{i=1}^n X_i }n$
中位数(Median)
高偏斜分布(存在异常值)的情况下,中位数则能更好地反映数据的集中趋势
众数(Mode)
平均分布的情况下,则无法得出众数
另外,在正太分布的数据集中,均值、中位数、众数均相等
稳健统计
值域(Range)
函数的值域(Range)是由定义域中一切元素所能产生的所有函数值的集合(也被称为函数的像)
四分位数(Quartile)
统计学中分位数的一种,即把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数
数学表达式:$L_p = n \frac{ p }{100}$,其中,$p$ 为四分位的百分比值,$n$ 为样本总量
四分位距(IQR, Interquartile Range)
第三四分位数和第一四分位数的差距,即 $Q_3 - Q_1$
可以使用 $Q_1-1.5 \cdot IQR$ 和 $Q_3+1.5 \cdot IQR$ 区间,来判断离群值(Outlier)
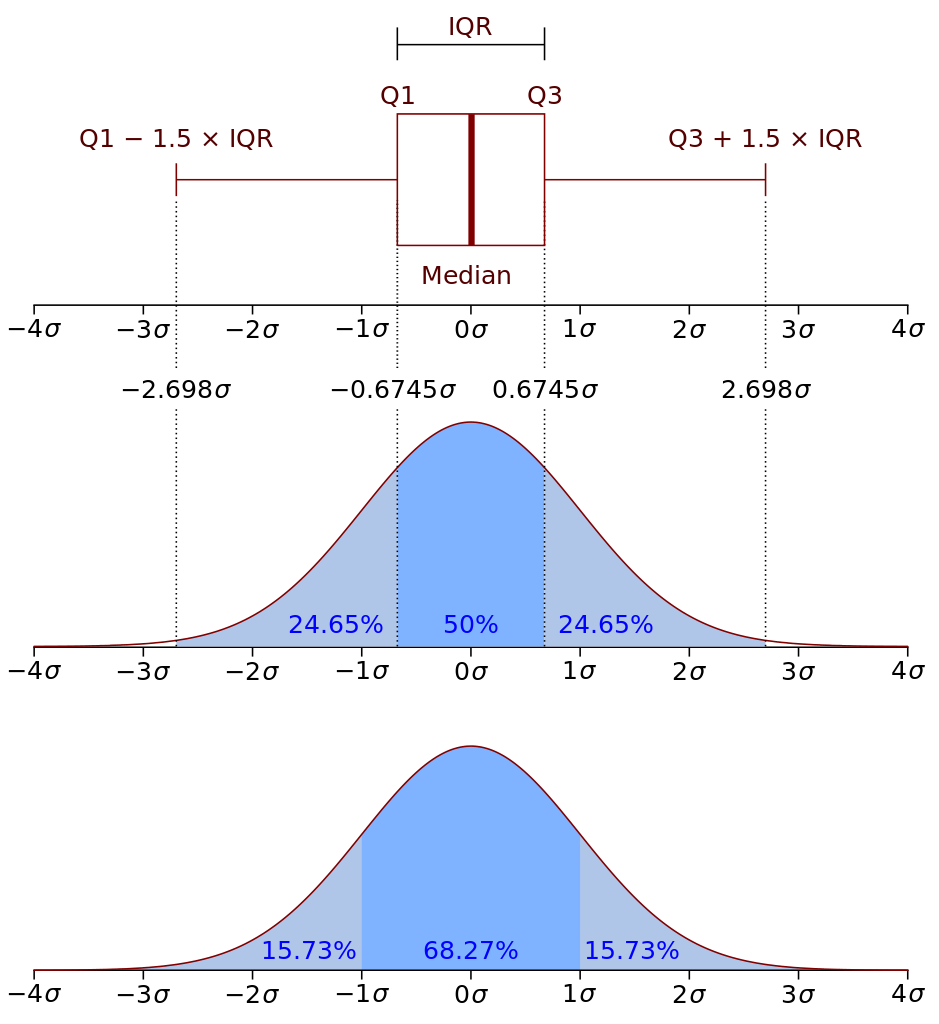
四分位差(QD, Quartile Deviation)
四分位差是指 $Q_1$ 和 $Q_3$ 的差距,即 $QD = Q_3 - Q_1$(这里单独提出来,是因为旧版教材中的公式为 $QD = \frac{ Q_3 - Q_1 }2$)
偏差
离均差(Deviation from Average)
$x_i - \bar x$
平均偏差(Average Deviation)
$\frac{ \sum_{i = 1}^n (x_i - \bar x) }n$
标准偏差(Standard Deviation)
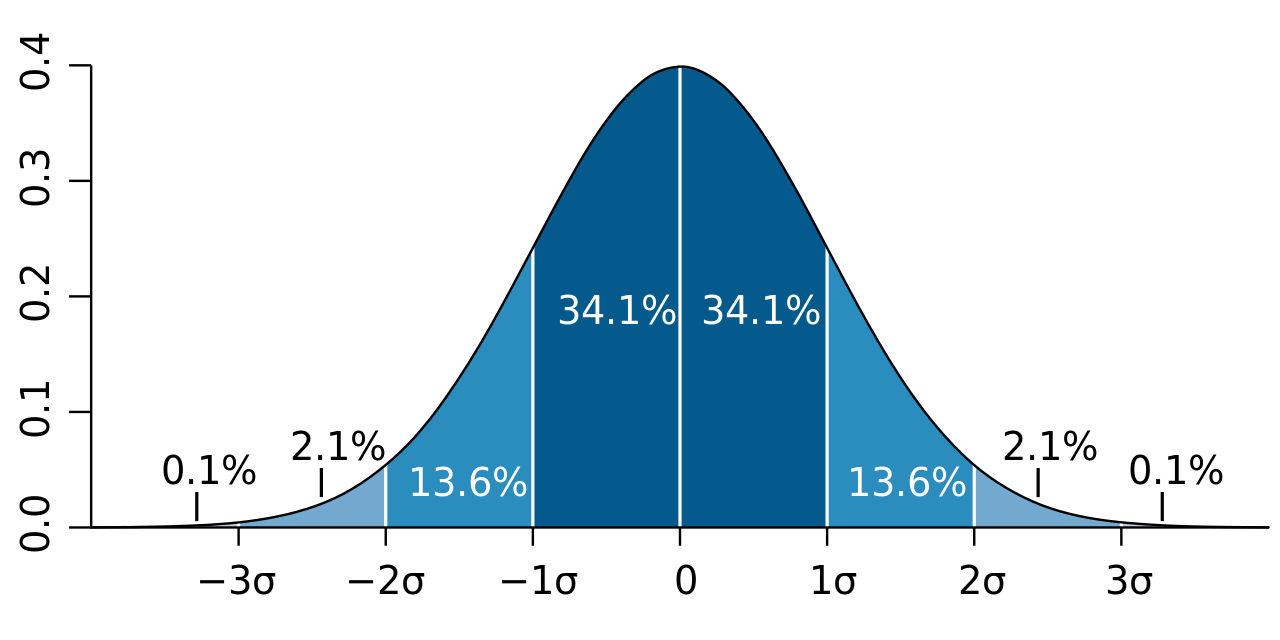
标准差的概念,由卡尔·皮尔逊引入到概率统计中,是测量离散程度最为常用的方法。公式是 $\sigma = \sqrt{\frac{ \sum_{i=1}^n(x_i - \bar x)^2 }n}$ = $\sqrt{\frac{ (x_1 - \bar x)^2 + (x_2 - \bar x)^2 + \ldots + (x_i - \bar x)^2 }n}$。该方法避免了负值的出现,并且能够保证得到的结果,具备和被测量数据一样的度量单位,方便进行比对
标准差还可以用于判断数据集是否属于正态分布。若其符合正态概率分布,则如下图所示,约68.3% 的数值会分布在距离 平均值$\bar x$ 的 1个 标准差$\sigma$ 范围之内,约95.4% 的数值分布在距离 平均值$\bar x$ 的 2个 标准差$\sigma$ 范围之内,以及 约99.73% 的数值分布在距离 平均值$\bar x$ 的 3个 标准差$\sigma$ 范围之内。这一现象我们称之为 “68-95-99.7法则” 或 “经验法则”
贝塞尔校正
又因为样本抽选的数据,很容易落入平均值附近,导致低估了整体数据集的偏差。因此引入了贝塞尔校正,使得标准差的值变大,来更好地表达样本标准差(Sample Standard Deviation)
$s = \sqrt {\frac{ \sum_{i=1}^n(x_i - \bar x)^2 }{n - 1}}$
回归分析
定义
回归分析(Regression Analysis)是一种确定两种或多个变量间相互依赖的定量关系的统计分析方法
组成
包括未知参数 $\beta$(表示一个标量或者向量)、自变量 $X$ 和 因变量 $Y$
回归模型则是将三者关联起来,表示为 $Y \approx f(X, \beta)$
种类
分类方式
按照涉及的变量的多少,分为一元回归和多元回归分析
按照因变量的多少,分为简单回归分析和多重回归分析
按照自变量和因变量之间的关系类型,分为线性回归分析和非线性回归分析
常见类型
一元线性回归
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析
多重线性回归
如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多重线性回归分析
多元线性回归
多元线性回归可表示为 $Y = a + b_1 X_1 + b_2 X_2 + e$,其中 $a$ 表示截距,$b$ 表示直线的斜率,$e$ 是误差项。多元线性回归可以根据给定的预测变量 $s$ 来预测目标变量的值
微积分
基本概念
增量
点 $(x_1, y_1)$ 移动到 点 $(x_2, y_2)$,其坐标的增量为 $\Delta x = x_2 - x_1$ 和 $\Delta y = y_2 - y_1$
平行线 & 垂直线
斜率 $m$ = $\frac{ \Delta y }{ \Delta x }$,直线 $L_1$ 和 $L_2$ 的斜率分别记作 $m_1$ 和 $m_2$
如果 $m_1 = m_2$,则 $L_1$ 与 $L_2$ 平行或重合,记作 $L_1 \mid \mid L_2$;如果 $m_1m_2 = -1$,则两者互相垂直,记作 $L_1$ ⊥ $L_2$
函数
定义
函数是将一个对象转化为另一个对象的规则 $f$。函数必须要给每个有效输入指定唯一的输出。这里我们输入的集合 $x$ 称之为定义域、输出的集合 $f(x)$ 称之为值域
常用集合
$Z$ 整数集,$N$ 非负数集,$Q$ 有理数集
常用函数的定义域和值域
| 函数 | 定义域 | 值域 | 图形 |
|---|---|---|---|
| $y = \frac{ 1 }{ x }$ | $(-\infty, +\infty)$ | $(-\infty, 0) \,\bigcup\, (0, +\infty)$ | 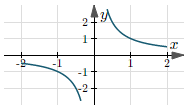 |
| $y = \sqrt{x}$ | $[0, +\infty)$ | $[0, +\infty)$ | 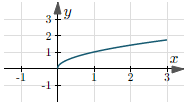 |
| $y = x$ | $(-\infty, +\infty)$ | $(-\infty, +\infty)$ | 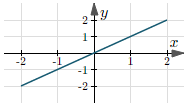 |
| $y = x^2$ | $(-\infty, +\infty)$ | $[0, +\infty)$ | 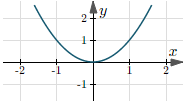 |
| $y = \sin(x)$ | $(-\infty, +\infty)$ | $[-1, 1]$ | 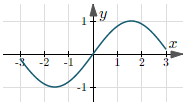 |
| $y = \cos(x)$ | $(-\infty, +\infty)$ | $[-1, 1]$ | 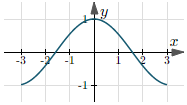 |
| $y = \tan(x)$ | $(-\frac{ \pi }{ 2 } + 2k\pi,$ $\frac{ \pi }{ 2 } + 2k\pi)$, $k \in Z$ | $(-\infty, +\infty)$ | 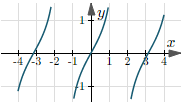 |
反函数
对于 $y = f(x)$,如果将其逆转变换后,仍然满足 $f(x) = y$,则称新函数为 $f$ 的反函数,并记作 $f^{-1}$
函数复合
$f(x) = h(g(x)) = h \circ g$
奇偶性
奇函数
$f(x) = -f(-x)$
偶函数
$f(x) = f(-x)$
线性函数
$f(x) = mx + b$
点斜式
直线通过一个点 $(x_0, y_0)$,斜率为 $m$,则方程可表示为 $y - y_0 = m (x - x_0)$
直线通过两个点 $(x_1, y_1)$ 和 $(x_2, y_2)$,则斜率为 $m$ = $\frac{ y_2 - y_1 }{ x_2 - x_1 }$ = $\frac{ \Delta y }{ \Delta x }$,则方程式表示为 $y - y_1$= $\frac{ \Delta y }{ \Delta x }$ $(x - x_1)$
已知斜率 $m$ 和截距 $b$,可以直接求得直线方程式 $y = m(x - 0) + b = mx + b$
多项式
$p(x)$ = $a_nx^n + \ldots + a_2x^2 + a_1x + a_0$
二次函数
二次函数是一个最高次为 $2$ 的多项式,表示为 $p(x) = ax^2 + bx + c$
依据 $\Delta = b^2 - 4ac$ 判别式,可知:
- 当 $\Delta \gt 0$ 时,$p(x)$ 有两个不同解,且解为 $\frac{ -b \pm \sqrt{b^2 - 4ac} }{ 2a }$;
- 当 $\Delta = 0$ 时,$p(x)$ 有两个相同的解,即只有一个解;
- 当 $\Delta \lt 0$ 时,$p(x)$ 无解
实例
求解 $3x^2 -5x + 7 = 0$
因为 $\Delta = (-5)^2 - 4 \cdot 3 \cdot 7$ $= -59 \lt 0$,所有该方程无解
可以将方程拆解组合,进行证明:
可见等式左边是恒为非负数的,因此,是不可能存在 $x$ 使等式成立的,即方程无解
有理函数
若 $p$ 和 $q$ 均为多项式,则形如 $\frac{ p(x) }{ q(x) }$ 的函数,我们称之为 有理函数
指数函数
$y = a^x$
对数函数
将 指数函数 以 $y = x$ 做镜像,则得到 $y = \log_a(x)$ 指数函数
带绝对值的函数
求导
分数求导
$f(x) = \frac{ g(x) }{ h(x) }$ 的导数为 $f^\prime(x) = \frac{ g^\prime(x)h(x)-h^\prime(x)g(x) }{ h(x)^2 }$
复合函数求导
$(f \circ g)(x)$ 的导数为 $(f \circ g)^\prime(x) = f^\prime(g(x))g^\prime(x)$
极限
定义
邻域
以点 $x_0$ 为中心的任何开区间,称之为点 $x_0$ 的邻域,记做 $U(x_0)$
$\delta$ 邻域
设 $\delta$ 为正数,则称开区间 $(x_0 - \delta, \, x_0 + \delta)$ 为点 $x_0$ 的 $\delta$ 邻域,记做 $U(x_0, \, \delta)$ = $\{x \mid x_0 - \delta \lt x \lt x_0 + \delta\}$。其中,点 $x_0$ 称为邻域的中心,$\delta$ 为邻域的半径
$\delta$ 去心邻域
$\mathring{U}(x_0, \delta)$ = $\{ x \mid 0 \lt \mid x - x_0 \mid \lt \delta \}$
二维 $\delta$ 邻域
设 $P_0(x_0, \, y_0)$ 为 $xOy$ 平面上的一个点,$\delta$ 为某个正数,与点 $P_0(x_0, \, y_0)$ 距离小于 $\delta$ 的点 $P(x, \, y)$ 的全体,称之为点 $P_0$ 的 $\delta$ 邻域,记做 $U(P_0, \delta)$ = $\{ x \mid \sqrt{(x - x_0)^2 + (y - y_0)^2} \lt \delta \}$
函数极限
设函数 $f(x)$ 在点 $x_0$ 的某一去心邻域内有定义,若存在常数 $A$,对于任意给定的 $\epsilon \gt 0$(无论 $\epsilon$ 有多小),总存在正数 $\delta$,使得当 $0 \lt \mid x - x_0 \mid \lt \delta$ 时,对应函数的值 $f(x)$ 都满足不等式 $\mid f(x) - A \mid \lt \epsilon$,则 $A$ 就叫做函数 $f(x)$ 当 $x \to x_0$ 的极限,记做 $\lim_{x \to x_0}f(x)=A$,或 $f(x) \to A$(当 $x \to x_0$)
换一种说法是,$\lim_{x \to x_0}f(x) = A \Leftrightarrow \forall \epsilon \gt 0$,$\exists \delta \gt 0$,当 $0 \lt \mid x - x_0 \mid \lt \delta$ 时,$\mid f(x) - A \mid \lt \epsilon$
线性代数
基本概念
行列式
行列式(Determinant)是数学中的一个将 $n \cdot n$ 的矩阵 $A$ 映射到一个标量的函数,记作 $det(A)$ 或 $\mid A \mid$。行列式可以看做是有向面积或体积的概念,在欧几里得空间中的推广。或者说,在 $n$ 维欧几里得空间中,行列式描述的是一个线性变换对体积所造成的影响
单位矩阵
单位矩阵 是主对角线为 $1$,其余元素为 $0$ 的方形矩阵,记作 $I$ 或 $E$
$I_n = \begin{bmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \\ \end{bmatrix}$
初等矩阵
初等矩阵(又称为基本矩阵)是由一个 $n$ 阶单位矩阵 $E$,经过一次初等行列变换所得的矩阵。我们称之为 $n$ 阶初等矩阵
增广矩阵
增广矩阵是由系数矩阵的右边,添上线性方程组等号右边的常数列 得到的矩阵
方程 $AX=b$ 系数矩阵为 $A$,常数列为 $b$,则它的增广矩阵表示为 $(A \mid b)$,形式如下
通过对增广矩阵进行初等行变换,可判断线性方程组是否有解,以及化简原方程组,方便求解
实用技巧
消元法
高斯-约当(Gauss-Jordan)消元法
直接上一个例子,会比较直观一些
化简到上三角形式方程组后,就可以一眼看出,当自由列取值为 $0$ 时,能得到一个特解:
克拉默法则(Gramer´s Rule)
可以通过消元代入法,得到 $x_1 = \frac{ b_1a_{22} - b_2a_{12} }{a_{11}a_{22} - a_{12}a_{21}}$,$x_2 = \frac{b_2a_{11} - b_1a_{21}}{a_{11}a_{22} - a_{12}a_{21}}$,换成行列式表达式形式,则可表示为
概率论
集合
将一些研究对象放在一起,形成集合,而这些对象就称为集合的元素
概率模型
概率模型是对不确定现象的一种数学描述
主要构成
样本空间
用 $\Omega$ 表示一个试验中所有可能结果的集合
概率律
用一个非负数 $P(A)$ 表示某一个事件 $A$ 在试验结果中出现的概率
公理
- 非负性
对于一切事件 $A$,满足 $P(A) \geq 0$ - 可加性
对于 $A_1, A_2, \ldots, A_n$ 互不相交的集合,满足 $P(A_1 \bigcup A_2 \bigcup \ldots \bigcup A_n)$ = $P(A_1) + P(A_2) + \ldots + P(A_n)$ - 归一化
$P(\Omega) = 1$
综合推导,可得 $P(\emptyset)$ = $1- P(\Omega) + P(\emptyset)$ = $1 - P(\Omega \bigcup \emptyset)$ = $1 - P(\Omega) = 0$
性质
- 若 $A \subset B$,则 $P(A) \leq P(B)$
- $P(A \bigcup B)$ = $P(A) + P(B) - P(A \bigcap B)$
- $P(A \bigcup B)$ $\leq$ $P(A) + P(B)$
- 由上式推广,可得 $P(A_1 \bigcup A_2 \bigcup \ldots \bigcup A_n)$ $\leq \sum_{i=1}^nP(A_i)$
- $P(A \bigcup B \bigcup C)$ = $P(A) + P(A^c \bigcap B)$ $+ P(A^c \bigcap B^c \bigcap C)$
技术发展史
机器学习发展总图
深度学习发展总图
graph TD
start[Start] --> nerve_cell(生物神经元)
nerve_cell --> mp_model(MP 模型)
mp_model --> weight{自主学习权重}
weight --> |No| non_perceptron[参数权重需要人为设定]
weight --> |Yes| perceptron(感知器)
perceptron --> bp{BP 反向传播}
bp --> |No| non_mlp[无法解决最简单的线性不可分问题]
bp --> |Yes| mlp(多层感知器)
mlp --> pre_train{预训练 + 激活函数}
pre_train --> |No| no_dnn[局部最优解 + 指数梯度衰减]
pre_train --> |Yes| dnn(深度神经网络)
dnn --> kernal{卷积核}
kernal --> |No| non_cnn[过拟合 + 运算时间成本高]
kernal --> |Yes| cnn(卷积神经网络)
cnn --> directed{神经元间链成有向图}
directed --> |No| non_rnn[无法对事件序列建模]
directed --> |Yes| rnn(递归神经网络)
rnn --> cell{细胞状态}
cell --> |No| non_lstm[无法捕获间隔太长的事件间关系]
cell --> |Yes| lstm(长短期记忆网络)
lstm --> transformer{是否支持 Transformer}
transformer --> |No| non_transformer[无法实现并行处理序列]
transformer --> |Yes| llm(大语言模型)
llm --> e[End?]
麦卡洛克-皮茨神经元模型(McCulloch - Pitts Neuron Model)
麦卡洛克-皮茨神经元模型(McCulloch - Pitts Neuron Model)是模仿生物学神经元功能的简单线性模型,由心理学家 Warren McCulloch 和 数学家 Walter Pitts 在 1943 年提出。该模型针对输入的 $x_1, x_2, \dots, x_n$,分别赋予不同的权重 $w_1, w_2, \dots, w_n$,形成 $f(x, w) = \sum_{i = 1}^nx_iw_i$ 检验函数用以模仿生物神经元的膜电位,再通过 $o_j(t + 1)$ = $f\{[\sum_{i=1}^nw_{ij}x_i(t)] - T_j\}$ 模仿在每个 $t$ 时刻神经元细胞的输出(信号空间的求和与神经元阀值 $T_j$ 差值的正负),完成分类。同时 MP 模型也存在不足之处,即权重需要人为给定,一旦权重分配不合理,将无法得出期望的分类结果
感知器(Perceptron)
感知器(Perceptron)是 Frank Rosenblatt 在 1957 年就职于 Cornell 航空实验室(Cornell Aeronautical Laboratory)时所发明的一种人工神经网络。它可以被视为一种最简单形式的前馈神经网络,是一种二元线性分类器。感知器,解决了 MP 模型的无法自主学习的问题,成为第一个能根据每个类别的输入样本来学习权重的模型。此外,Frank Rosenblatt 给出了相应的感知器学习算法,常用的有 感知器学习、最小二乘法和梯度下降法。譬如,感知器利用梯度下降法对损失函数进行极小化,求出可将训练数据进行线性划分的分离超平面,从而求得感知器模型。感知器也被称为 单层人工神经网络,以区别于较复杂的多层感知器(Multilayer Perceptron)。尽管结构简单,感知器却能学习并解决相当复杂的问题。不过,感知器存在本质上的缺陷,就是无法处理线性不可分问题
多层感知器(MLP, Multilayer Perceptron)
多层感知器(MLP, Multilayer Perceptron)是一种前馈神经网络(Feedforward Neural Network),映射一组输入向量到一组输出向量。MLP 可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。另外,MLP 是(单层)感知器的推广,摆脱了早期离散传输函数的束缚,使用 激活函数(Sigmoid / Tanh / ReLU / …)模拟神经元对激励的响应,在训练算法上则使用反向传播算法,解决了感知器不能对线性不可分数据进行处理的问题
深度神经网络(DNN, Deep Neural Networks)
深度神经网络(DNN, Deep Neural Networks)是一种判别模型,可以使用反向传播算法进行训练。DNN 通过 “预训练” 和 “ReLU、Maxout 等激活函数” 解决了 多层感知器 中的 “局部最优解” 和 “梯度衰减” 问题。不过,与其他神经网络模型类似,如果仅仅是简单地训练,深度神经网络可能会存在很多问题。常见的两类问题是过拟合(Overfiting)和过长的运算时间
因为增加了隐藏层,会使得模型对训练数据中较为罕见的依赖关系进行建模,所以深度神经网络很容易出现过拟合现象。对此,可以利用 稀疏($L_1$ 正则化)或者 权重递减($L_2$ 正则化) 等方法在训练过程中减少过拟合现象。另外,还有一种叫做丢弃法(Dropout)的正则化方法,即在训练中随机丢弃一部分隐层单元,来避免对较为罕见的依赖进行建模
反向传播算法和梯度下降法由于其实现简单,并且相比其他方法,能够收敛到更好的局部最优值,因而成为神经网络训练的通行方法。但是,这些方法的计算代价很高,尤其是在训练 DNN 时,因为其规模(即层数和每层的节点数)、学习率、初始权重等众多参数都需要考虑。考虑到时间代价,想要扫描所有的参数是不可行的,因而考虑将多个训练样本组合进行 小批量训练(mini-batching),而非每次只使用一个样本进行训练,从而加速模型训练。而最显著地速度提升来自 GPU,因为矩阵和向量计算非常适合使用 GPU 实现。但使用大规模集群进行 DNN 训练仍然存在瓶颈,因而在并行化方面仍有很大的提升空间
卷积神经网络(CNN, Convolutional Neural Network)
卷积神经网络(CNN, Convolutional Neural Network)是一种前馈神经网络,由哈弗医学院生理学家 Hubel 和 Wiesel 通过对猫视觉皮层细胞的研究,在 1962 年提出了感受野(Receptive Field)的概念,随后在 1984 年日本学者 Fukushima 基于 RF 的概念,设计出了神经感知机(Neocognitron)。其人工神经元可以响应一部分覆盖范围内的周围单元,对于图像处理和语音识别有着出色的表现
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(Pooling Layer)。这一结构使得 CNN 能够利用输入数据的二维结构,也可以使用反向传播算法进行训练。相比较其他的前馈神经网络,CNN 通过卷积核控制只在同一个核内的神经元进行全连接,使得需要估计的参数很少,从而在根本上解决了 DNN 的参数膨胀的问题。但是,CNN 仍然存在无法对时间序列进行建模的缺陷
递归神经网络(RNN, Recurrent Neural Networks)
递归神经网络(RNN, Recurrent Neural Networks)是两种人工神经网络的总称。一种是时间递归神经网络(Recurrent Neural Network),另一种是结构递归神经网络(Recursive Neural Network)。前者的神经元间连接构成有向图,而后者利用相似的 神经网络结构 递归构造更为复杂的深度网络。RNN 一般指代 时间递归神经网络。单纯递归神经网络因为无法处理随着递归,权重指数级爆炸或消失的问题(Vanishing Gradient Problem),所以难以捕捉长期时间的关联;而结合不同变种的 LSTM 网络 可以很好解决这个问题
长短期记忆网络(LSTM, Long Short Term Memory Networks)
长短期记忆(LSTM, Long Short Term Memory Networks)是 时间递归神经网络(RNN) 的一种,论文首次发表于 1997 年。由于巧妙的设计结构,LSTM 适合于处理和预测时间序列中间隔和延迟非常长的重要事件。因为 时间递归神经网络 和 前馈神经网络(Feedforward Neural Network)接受较特定结构的输入不同,RNN 将状态(Cell State) 在自身网络中循环传递,使得 LSTM 可以接受更广泛的时间序列结构的输入,进而更好地描述动态时间行为
一般的,LSTM 的表现会比 时间递归神经网络(RNN)及隐马尔科夫模型(HMM)更好,比如用在不分段连续手写识别上。在 2009 年,用 LSTM 构建的人工神经网络模型就赢过了 ICDAR 手写识别比赛冠军。同时,LSTM 还普遍应用于自主语音识别,2013 年运用 TIMIT 自然演讲数据库达成 17.7% 错误率的纪录。而作为非线性模型,LSTM 又可当作复杂的非线性单元用于构造更庞大的深度神经网络
机器学习
其实将机器学习和深度学习分为两个章节来讲,会容易让人产生错觉,误以为机器学习和深度学习是两个不相干的领域。实际上,后者只是前者的一个子集。针对两者关系,更详细的描述可以参见后面 “AI 到底是什么” 部分
基础概念
分类与回归
机器学习任务中,预测值为离散类型的,则称该任务为分类任务(Classification);反之,预测值为连续类型的,则称该任务为回归任务(Regression)
贝叶斯定理
描述
其中,$P(A \mid B)$ 是在 $B$ 发生的情况下 $A$ 发生的可能性,称为 $A$ 的后验概率。相应的,$P(B \mid A)$ 则称为 $B$ 后验概率;$P(A)$ 是不考虑任何 $B$ 方面的因素下 $A$ 发生的可能性,称为 $A$ 的先验概率(或边缘概率)。相应的,$P(B)$ 则称为 $B$ 的先验概率
种类
特征独立性
按照特征之间独立性的强弱,可以分为 朴素贝叶斯、半朴素贝叶斯、(一般的)贝叶斯 等
分布情况
按照属性和特征的分布情况,又可以分为 高斯贝叶斯、多项式贝叶斯、伯努利贝叶斯 等
离散程度
按照训练集的离散程度,还可以分为 离散型贝叶斯、连续型贝叶斯、混合型贝叶斯 等
编码实战
The set A contains 30 a and 10 b, and the set B contains 20 a and 20 b, then what is the value of P(A|a)?
1 | situations = dict() |
补充
当存在多个特征变量时,表达式可扩展为
其中,$\frac{1}{Z}$ 是一个只与 $F_i$ 相关的缩放因子,且当特征变量的值固定时,$\frac{1}{Z}$ 为常量
深度学习
深度网络概要
激活函数(Activation Function)
定义
激活函数 就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。主要解决线性不可分问题,如 XOR 异或 等
种类
Sigmoid
Sigmoid 激活函数的表达式为 $f(x)$ = $\frac{e^x}{e^x + 1}$ = $\frac{1}{1 + e^{-x}}$
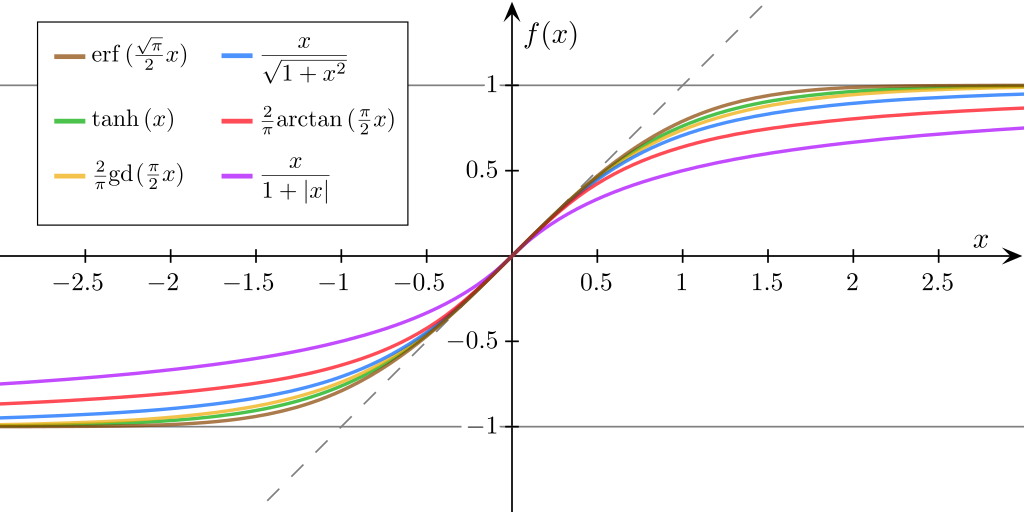
TanHyperbolic(Tanh)
Tanh 激活函数的表达式为 $f(x)$ = $\frac{e^x - e^{-x}}{e^x + e^{-x}}$,属于双曲正切函数,如下图表示
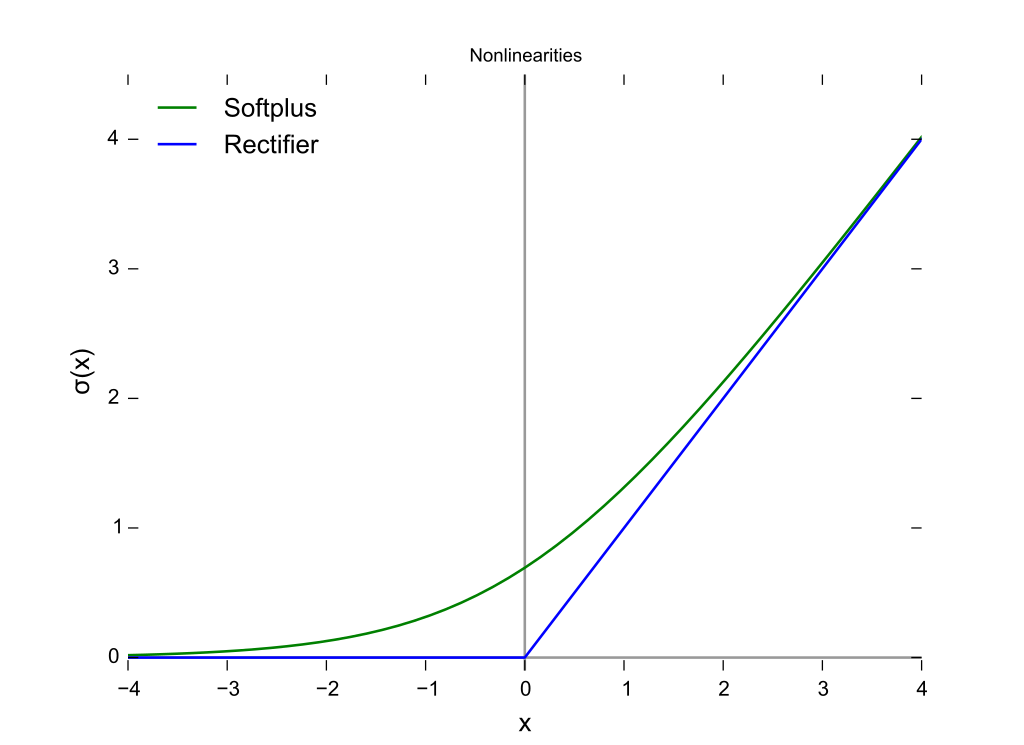
ReLU & Softplus
ReLU 激活函数表达式为 $f(x)$ = $max(0, x)$
Softplus 激活函数表达式为 $f(x)$ = $\log(1+e^x)$
LReLU & PReLU & RReLU
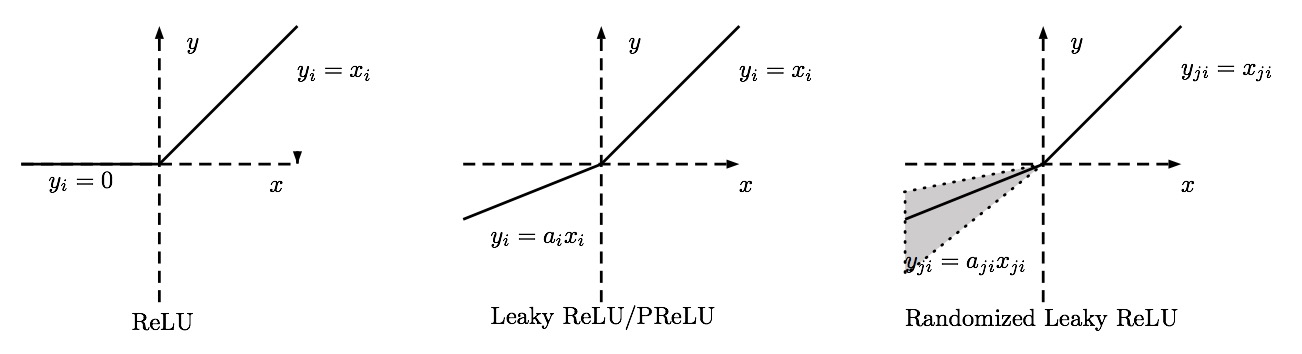
Maxout
Maxout 激活函数表达式为 $f(x)$ = $max_{j\in[1, k]}z_{ij}$,其中,$x \in R$,$z_{ij}$ = $x^TW_{\dots ij} + b_{ij}$,$W \in R^{d \cdot m \cdot k}$,$b \in R^{m \cdot k}$
Swish
Swish 激活函数表达式为 $f(x)$ = $x \cdot sigmoid(x)$
代价函数(Cost Function)
定义
代价函数(又称为 损失函数 或 成本函数)用来估量模型预测值 $f(x)$ 与 真实值 $Y$ 的偏差程度,通常表示为 $L(Y, f(x))$。代价函数的值越小,说明模型的鲁棒性越好。在特定的领域中,代价函数又会被称为 回报函数,利润函数,效用函数,适应度函数 等
种类
二次代价函数(Quadratic Cost)
二次代价函数表达式为 $C$ = $\frac{1}{2n}\sum\mid\mid y(x)$ - $a^L(x)\mid\mid^2$,其中 $x$ 代表样本,$y$ 代表实际值,$a$ 代表输出值,$n$ 代表样本的总量
当 $n = 1$ 时,样本集中只有一个样本,则二次代价函数可表示为 $C = \frac{1}{2}(((y - a)^1)^{\frac{1}1})^2$ = $\frac{(y - a)^2}{2}$,其中信号总量表示为 $z = \sum{W_jX_j} + b$, 激活函数表示为 $a = \sigma(z)$,则 $C = \frac{(y - \sigma(\sum{W_jX_j} + b))^2}{2}$。此时,我们对 $C$ 分别求 权重值 $w$ 和 偏置量 $b$ 的偏导,则得到 $\frac{\partial C}{\partial w}$ = $(a - y)\sigma^\prime(z) x$ 和 $\frac{\partial C}{\partial b}$ = $(a - y)\sigma^\prime(z)$。由此可见,$w$ 和 $b$ 的梯度和 $\sigma$ 的梯度成正比,$\sigma$ 的梯度越大,$w$ 和 $b$ 的调整速度越快,训练收敛便越快(推导过程相对比较简单,只用到了 度量空间求向量距离 和 复合函数求偏导)
交叉熵(Cross Entropy)
交叉熵代价函数表达式为 $C = -\frac{1}{n}\sum_{x=1}^{n}[y\ln a + (1 - y)\ln(1 - a)]$,其中 $x$ 代表样本,$y$ 代表实际值,$a$ 代表输出值,$n$ 代表样本的总量
和二次代价函数一样,不改变其激活函数,信号总量表示为 $z = \sum{W_jX_j} + b$, 激活函数表示为 $a = \sigma(z)$,则 $\sigma^\prime(z) = \sigma(x)(1 - \sigma(z))$。再次对 $C$ 求 $w$ 和 $b$ 的偏导分别为 $\frac{\partial C}{\partial w_j} = \frac{1}n\sum_{x=1}^nx_j(\sigma(z)-y)$ 和 $\frac{\partial C}{\partial b} = \frac{1}n\sum_{x=1}^n(\sigma(z) - y)$。由此可见,$w$ 和 $b$ 的调整与 $\sigma^\prime(z)$ 无关,并且,当 $\sigma(z) - y$ 预测值与实际值误差越大,$C$ 的梯度(求导)也就越大,训练的收敛速度也就越大。因此,$sigmoid$ 此类 $S$ 形激活函数,则不适合使用上文中介绍的二次代价函数;不过如果激活函数是线性的,则可能二次代价函数的表现更佳
对数似然代价函数(Log-likelihood Cost)
对数似然代价函数常用于 Softmax 归一化指数函数,可以有效地解决学习速度变慢的问题;但是,如果输出层神经元是 Sigmoid,则建议采用交叉熵代价函数
优化器(Optimizer)
SGD, Momentum, NAG, Adagrad, Adadelta, RMSprop
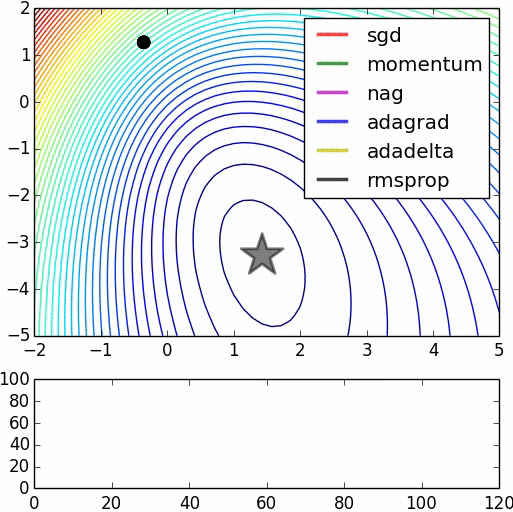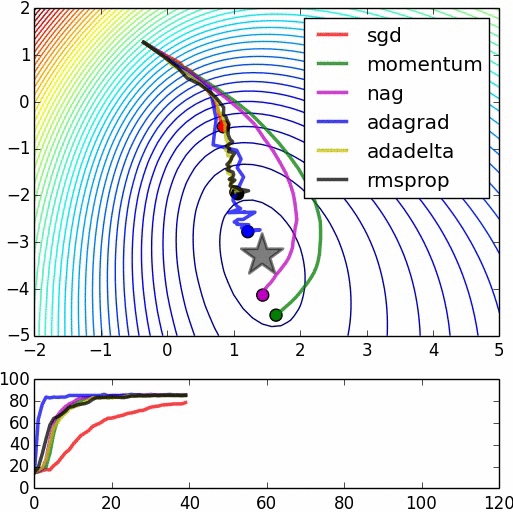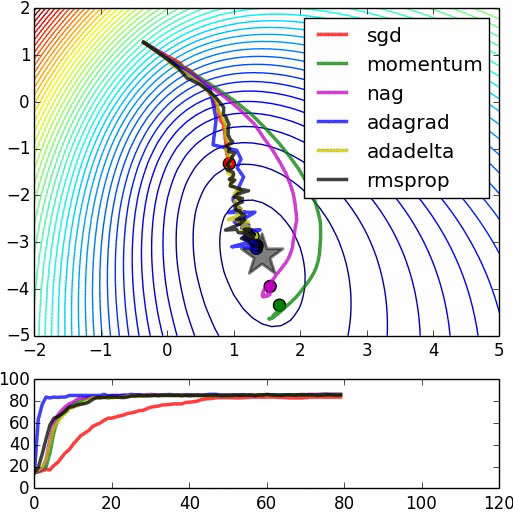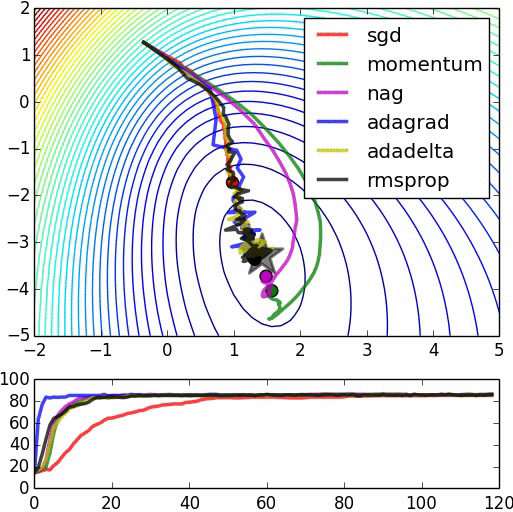
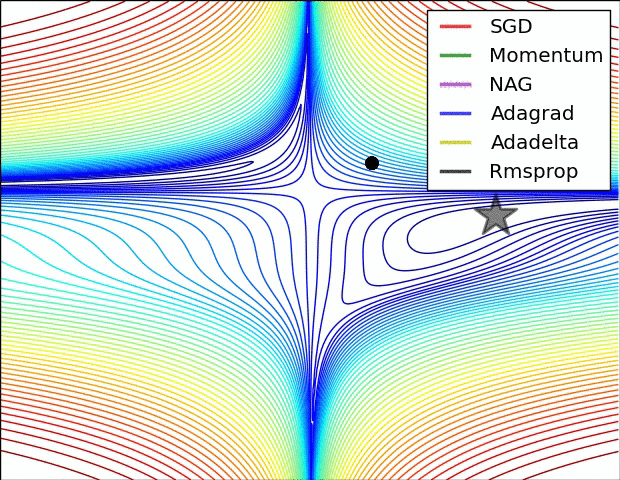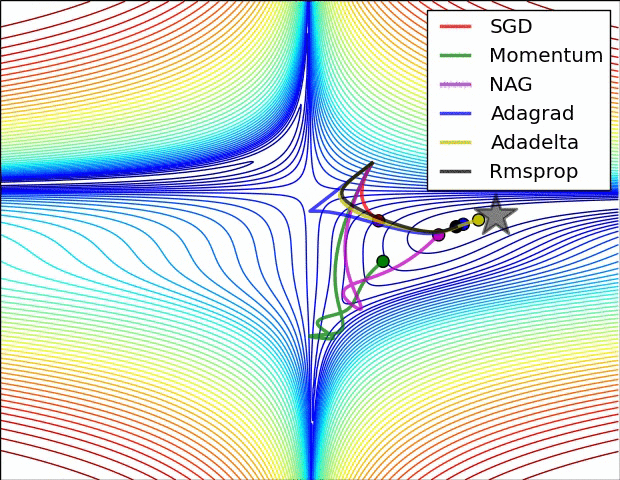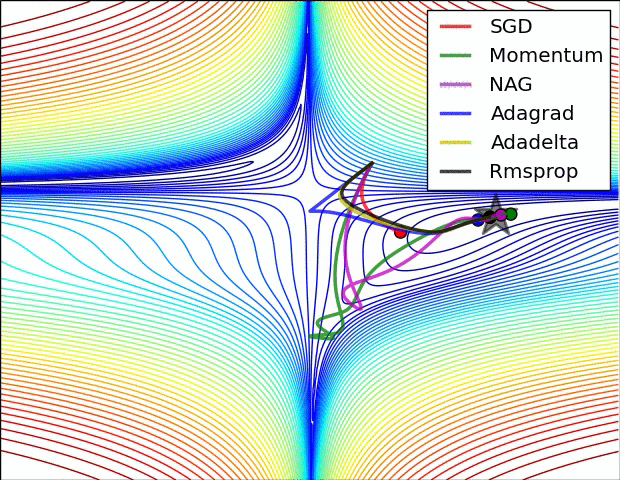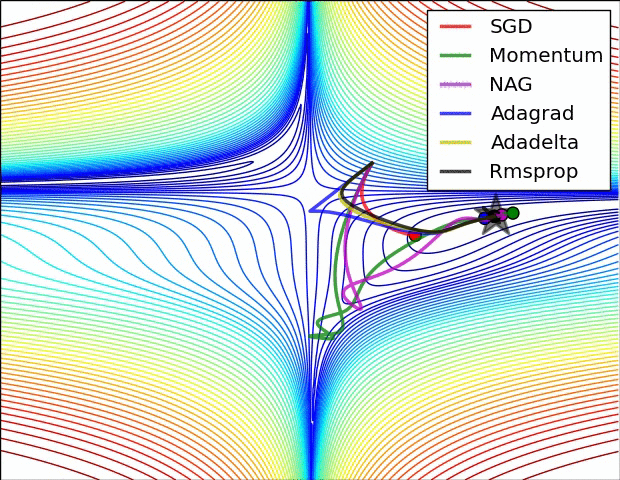
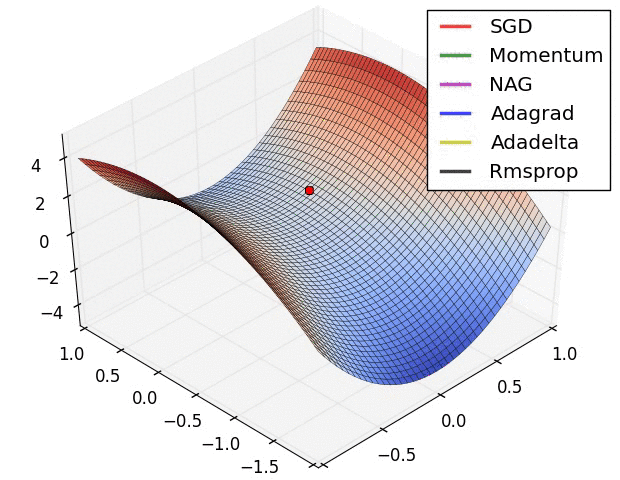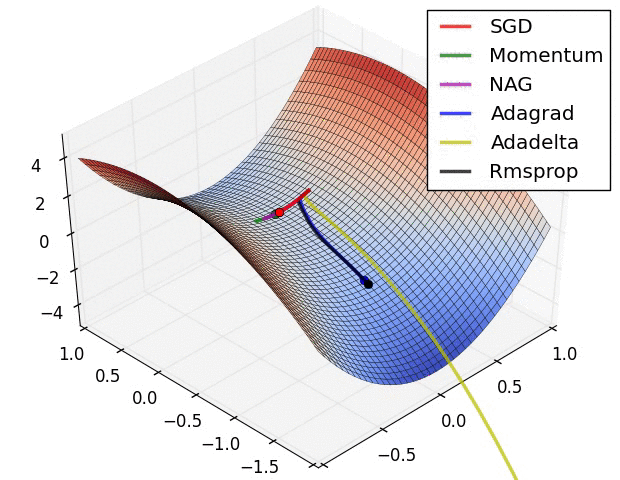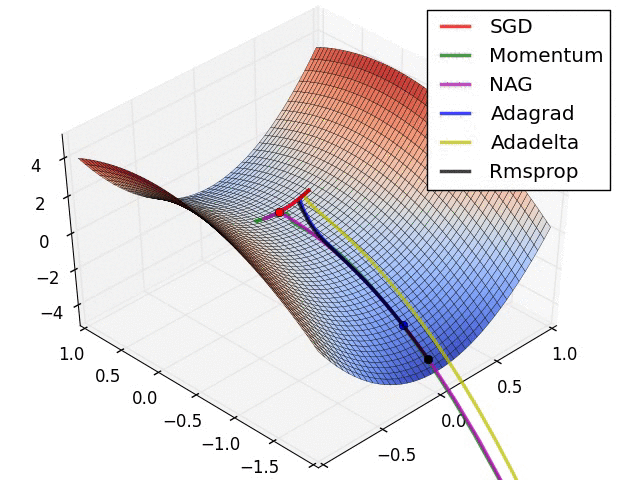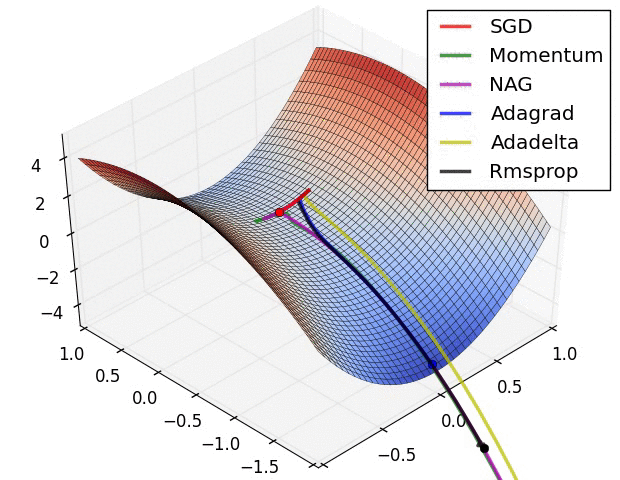
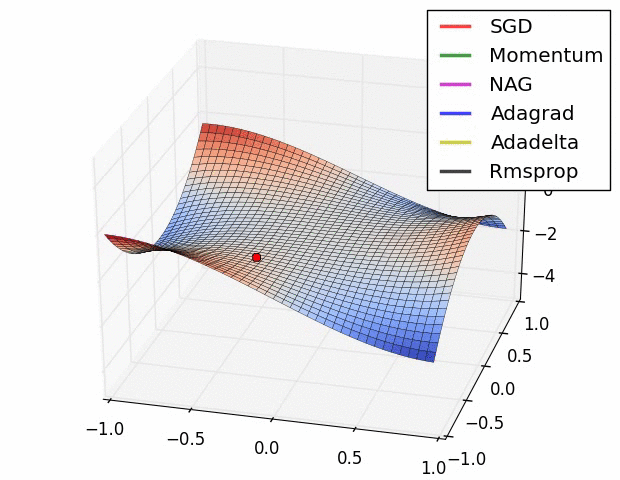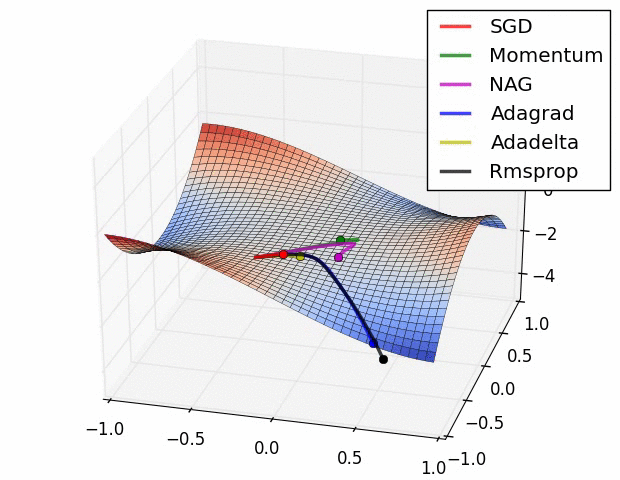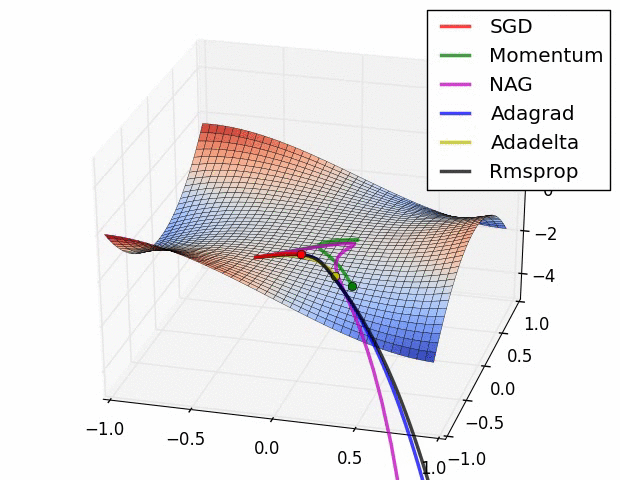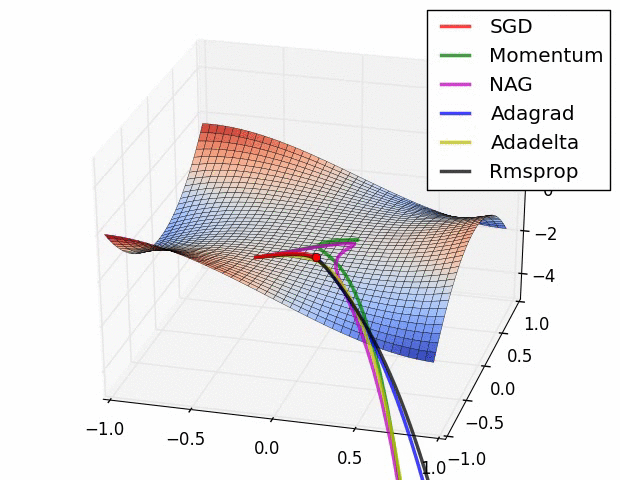
卷积神经网络
卷积
池化
常见类型
Max Pooling
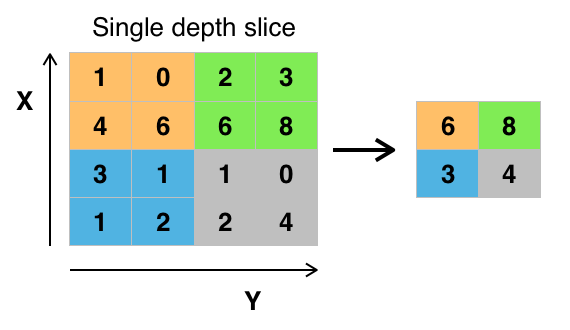
Mean Pooling
L2-norm pooling
Down Pooling
Padding
Same Padding
给采样平面外部补 $0$,使得卷积窗口采样之后,可以得到一个与被采样平面,大小一样的结果平面
Valid Padding
不会超出采样平面,卷积窗口采样之后,会到得到一个比原来平面小的结果平面
开源项目
Tensorflow / Tensorflow
介绍
TensorFlow™ 是一个端到端开源机器学习平台。它拥有一个全面而灵活的生态系统,其中包含各种工具、库和社区资源,可助力研究人员推动先进机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用。 — tensorflow.org
特性
基本概念
- 使用 图(Graph)来表示计算任务
- 在被称之为 会话(Session)的上下文(Context)中执行图
- 使用 Tensor 表示数据
- 通过 变量(Variable)维护状态
- 使用
feed和fetch可以为任意的操作(Arbitrary Operation)赋值或从中获取数据
安装
Python
需要注意的是,如果是在 Windows 环境下,只能安装 Python3.5+ 版本。详细安装步骤见《Python - 环境部署》
Anaconda3
下载地址:Download Page
启动程序的快捷链接,都自动创建在了 C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Anaconda3 (64-bit) 目录下
在运行 Jupyter 之前,需要简单设置下,文件的存放路径(如果只想使用 Jupyter,相关安装步骤见《Python - 科学分析工具》)
1 | $ jupyter notebook --generate-config |
TensorFlow
1 | ## 安装 |
Tips: 当然还有其他的方式,可以帮助我们更方便地使用这些科学分析库,包括 WinPython、Enthought Canopy etc.
编程实战
变量
加减
1 | import tensorflow as tf |
累计
1 | # Counter |
Tips: Full code is here.
矩阵积
1 | import tensorflow as tf |
Tips: Full code is here.
Fetch & Feed
Fetch
1 | # Fetch |
Feed
1 | # Feed |
Tips: Full code is here.
二次代价函数 & 梯度下降
1 | import tensorflow as tf |
Tips: Full code is here.
非线性回归
1 | import tensorflow as tf |
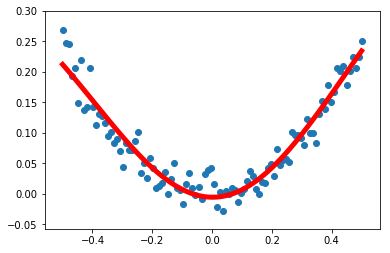
Tips: Full code is here.
手写数字识别
1 | # Download MNIST datasource |
Tips: Softmax 公式为:$softmax(x)_i$ = $\frac{exp(x_i)}{\sum_j{exp(x_j)}}$ = $\frac{e^{x_i}}{\sum_j{e^{x_j}}}$
Tips: Full code is here.
TensorBoard 可视化
Scalar & NameScope & Embedding
1 | import tensorflow as tf |
Tips: Full code is here.
启动
1 | # 执行完,会在程序中指定的目录下生成文件 events.out.tfevents.1502692143.BENEDICT_JIN |
Scalars
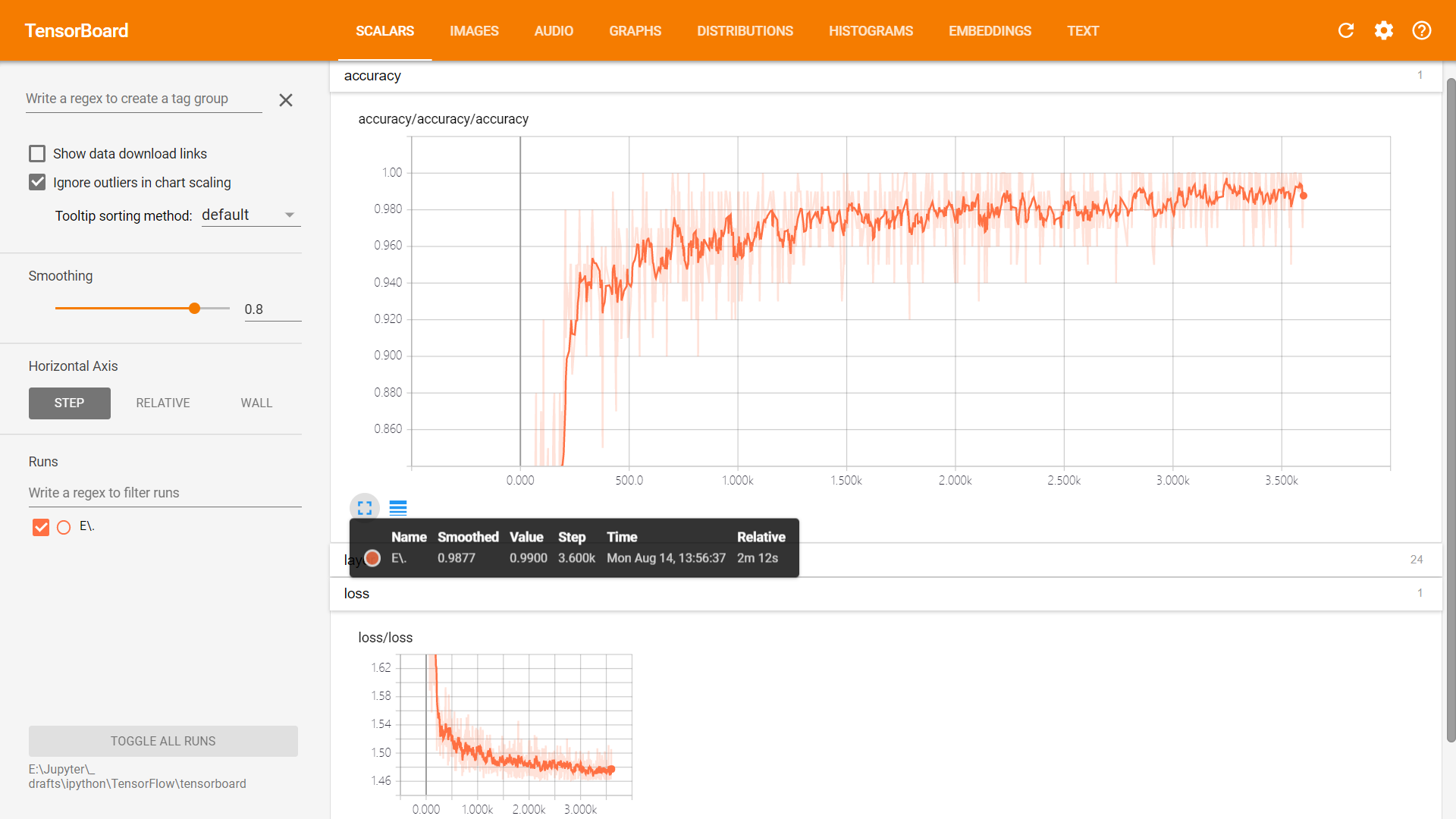
Graphs
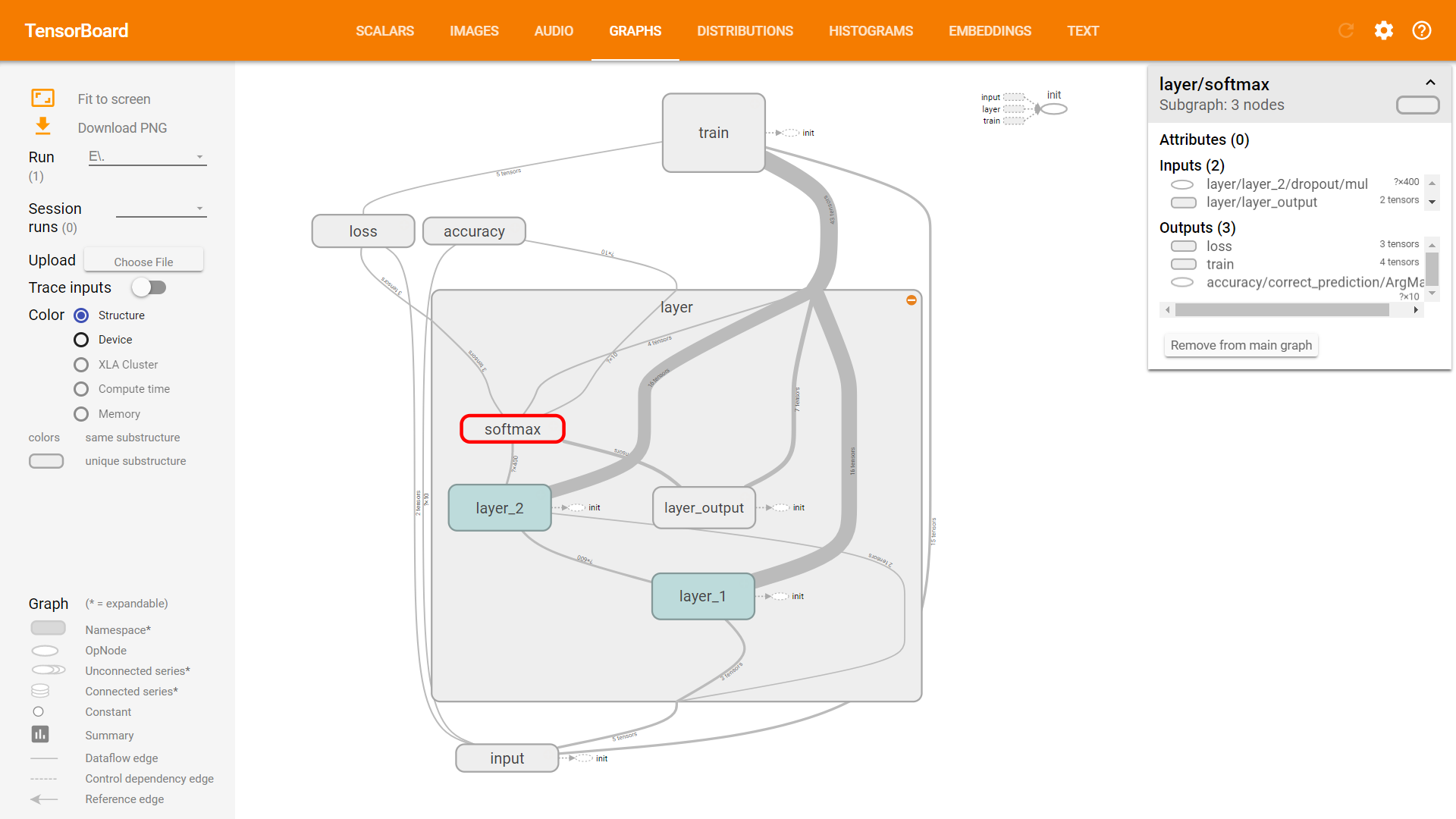
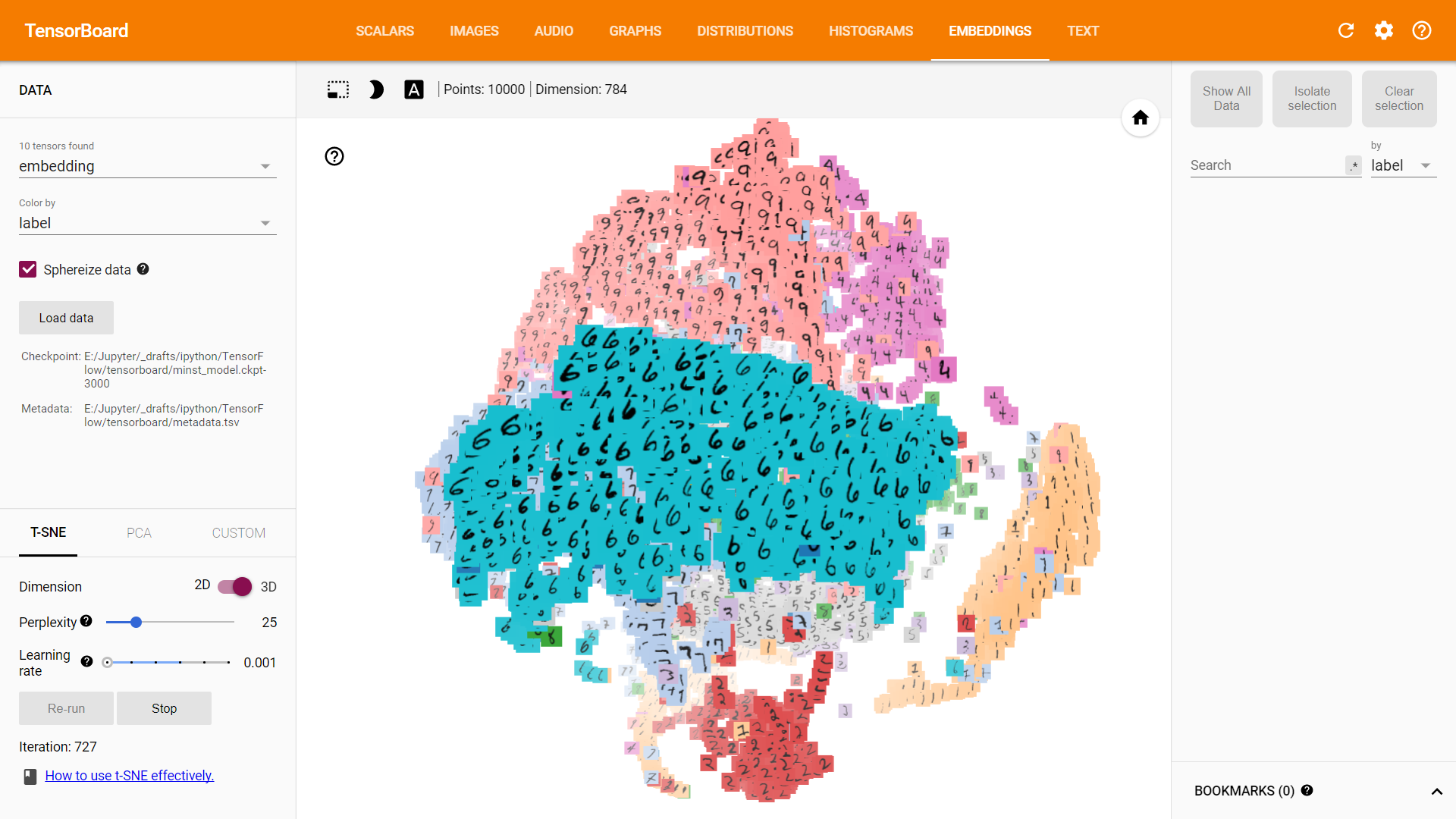
Embedding
GPU 加速
准备 NVIDIA 显卡
1 | 显卡2详情 |
CUDA(Compute Unified Device Architecture)
在 下载地址 找到系统对应的版本进行下载安装(Windows - x86_64 - 10 - exe - cuda_8.0.61_win10.exe)
安装成功后,将 bin 和 lib/x64 添加到系统 PATH 环境变量中
cuDNN
在 登陆页面 注册好 Nvidia 的账户后,下载对应 CUDA 版本的 cuDNN 即可(cudnn-8.0-windows10-x64-v5.1.zip)
将压缩包中 bin / include / lib 中的文件,拷贝到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0 下对应目录中。最后,将 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\extras\CUPTI\libx64\cupti64_80.dll 文件复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin 下
tensorflow-gpu
1 | $ pip uninstall tensorflow |
nvidia-smi 命令
1 | # nvidia-smi 可以查看 GPU 的资源、监控 GPU 运行状态、设置 GPU 超频 等等 |
CNN
CNN 版手写数字识别
1 | import tensorflow as tf |
Tips: Full code is here, and Kaggle competition is here.
RNN
LSTM 版手写数字识别
1 | import tensorflow as tf |
Tips: Full code is here.
pyTorch / pyTorch
介绍
PyTorch™ is a Python package that provides two high-level features: Tensor computation (like NumPy) with strong GPU acceleration and Deep neural networks built on a tape-based autograd system
安装
到 pytorch-scripts 项目中,下载当前最新的 release 版本 torch-0.3.0b0+591e73e-cp35-cp35m-win_amd64.whl,并安装
1 | $ pip install "torch-0.3.0b0+591e73e-cp35-cp35m-win_amd64.whl" |
Tips: Full code is here.
编程实战
Hello-world
1 | import torch |
BVLC / Caffe
介绍
Caffe™ (Convolutional Architecture for Fast Feature Embedding) is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license.
dmlc / xgboost
介绍
XGBoost™ is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way. The same code runs on major distributed environment (Hadoop, SGE, MPI) and can solve problems beyond billions of examples.
Apache / PredictionIO
介绍
Apache PredictionIO™ is an open source Machine Learning Server built on top of a state-of-the-art open source stack for developers and data scientists to create predictive engines for any machine learning task.
Numenta / NuPIC
介绍
NuPIC™(Numenta Platform for Intelligent Computing, Numenta 智能计算平台) 是一个与众不同的开源人工智能平台,它基于一种脑皮质学习算法,即 “层级实时记忆”(Hierarchical Temporal Memory, HTM)。该算法旨在模拟新大脑皮层的工作原理,将复杂的问题转化为模式匹配与预测,而传统的 AI算法大多是针对特定的任务目标而设计的
NuPIC 聚焦于分析实时数据流,可以通过学习数据之间基于时间的状态变化,对未知数据进行预测,并揭示其中的非常规特性
特性
- 持续的在线学习(根据快速变化的数据流进行实时调整)
- 时间和空间分析(可以同时模拟时间和空间的变化)
- 通过通用性的大脑皮层算法,进行预测和建模
- 强大的异常检测能力(实时检测数据流的扰动,不依靠僵化的阈值设置和过时的算法)
- 层级实时存储算法
安装
Windows
1 | $ yum install glibc-devel.i686 gcc -y |
Linux
可能部分版本不支持,需要结合 Nupic 的 Release 和 PyPi 平台找到合适的版本
1 | $ pip install https://s3-us-west-2.amazonaws.com/artifacts.numenta.org/numenta/nupic.core/releases/nupic.bindings/nupic.bindings-0.4.5-cp27-none-linux_x86_64.whl |
openai / gpt-3
介绍
GPT-3 是一种由 OpenAI 开发的大规模语言模型,它拥有 1750 亿个参数,是目前最大的自然语言处理模型之一。GPT-3 使用了深度学习技术,通过训练来学习自然语言的语法、语义和逻辑等特征。该模型可以用于自然语言生成、文本分类、机器翻译、对话系统等各种自然语言处理任务
GPT-3 模型采用了 Transformer 模型结构,通过使用大规模的数据集进行训练,使其可以产生高质量的文本生成结果,并且在许多自然语言处理任务中都取得了令人瞩目的表现。它可以生成各种类型的文本,如新闻报道、小说、诗歌、代码和对话等。同时,GPT-3 也引发了对于自然语言处理技术的更多讨论和探索,尤其是对于大型预训练语言模型的可解释性和伦理问题的关注
-- 来源:ChatGPT 的回答
如何训练一个大语言模型
数据收集:
- 来源选择:确定从哪里获取数据,例如开放的文本数据库、互联网抓取、社交媒体等。
- 数据清洗:去除重复、错误或不相关的信息。例如,可能要删除由网页抓取中产生的 HTML 标签。
- 数据选择:确保数据代表了各种语言风格和领域,以实现广泛的覆盖。
数据预处理:
- 标记化:使用工具(如 Spacy 或 Tokenizers 库)将文本分割成词、子词或字符级别的标记。
- 序列化:转化标记为整数或其他表示形式,方便模型处理。
- 创建数据批次:将数据分组成大小适中的批次,以便于模型进行并行计算。
模型架构:
- 选择架构:决定使用哪种模型架构,如 Transformer、LSTM 等。GPT 系列使用的是 Transformer 架构。
- 定义超参数:设置模型的大小、层数、注意力头数等。
模型初始化:
- 权重初始化:使用方法(如 Xavier 或 He 初始化)随机设定模型权重的初始值,确保不会过大或过小。
模型训练:
- 损失函数:定义损失函数,例如交叉熵损失,以衡量模型的预测与真实数据之间的差距。
- 优化器选择:如 Adam、SGD 等,它决定了如何基于损失更新模型权重。
- 正则化:可能使用如 Dropout、权重衰减等技术来避免过拟合。
- 学习率调整:如学习率衰减、余弦退火或使用学习率调度器。
评估和验证:
- 分割数据:确保有一个独立的验证集或测试集,用于评估模型性能。
- 指标计算:计算诸如困惑度、准确率等指标。
- 早停:如果在验证集上的性能停止提高,则可能提前结束训练。
微调(可选):
- 选择微调数据:针对特定任务收集数据。
- 微调训练:在微调数据上进行训练,但通常使用更小的学习率,以避免大幅改变原始模型。
部署:
- 模型压缩:使用技术如模型剪枝、知识蒸馏等,以减小模型大小或提高推理速度。
- 部署环境:将模型部署到服务器、边缘设备或云服务上。
Error from OpenAI: You exceeded your current quota
1 | Error from OpenAI: You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors. |
如果出现这样的报错,需要访问 https://platform.openai.com/settings/organization/billing/overview 进行充值
facebookresearch / llama
介绍
LLaMA 是一组具有 70 亿到 650 亿参数规模的基础语言模型集合。其使用了数万亿的标记对模型进行训练,并证实了仅使用公开可用的数据集的情况下,就可以训练出最先进的大语言模型。根据 Meta 论文所声称的,LLaMA-13B 在大多数基准测试中已经优于 GPT-3(175B)模型,而 LLaMA-65B 与最佳模型 Chinchilla70B 和 PaLM-540B 也旗鼓相当
ollama / ollama
介绍
Get up and running with large language models locally.
安装
MacOS
1 | $ ollama run llama3 |
1 | pulling 00e1317cbf74... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB |
使用
帮助手册
1 | >>> /? |
1 | Available Commands: |
1 | >>> /show |
1 | Available Commands: |
1 | >>> /show info |
1 | Model details: |
1 | >>> /show system |
1 | No system message was specified for this model. |
1 | >>> show template |
1 | Here is a basic template for creating a conversation: |
对话
1 | >>> What is AI? |
1 | AI stands for Artificial Intelligence, which refers to the development of computer systems that can perform tasks that would typically require human intelligence, such as: |
1 | >>> Yes |
1 | Let's dive deeper into AI! |
DeepSeek 蒸馏小模型
AI 到底是什么?
套娃
从体系组成成分的角度来讲,人工智能,包含机器学习。而机器学习,又包含了深度学习
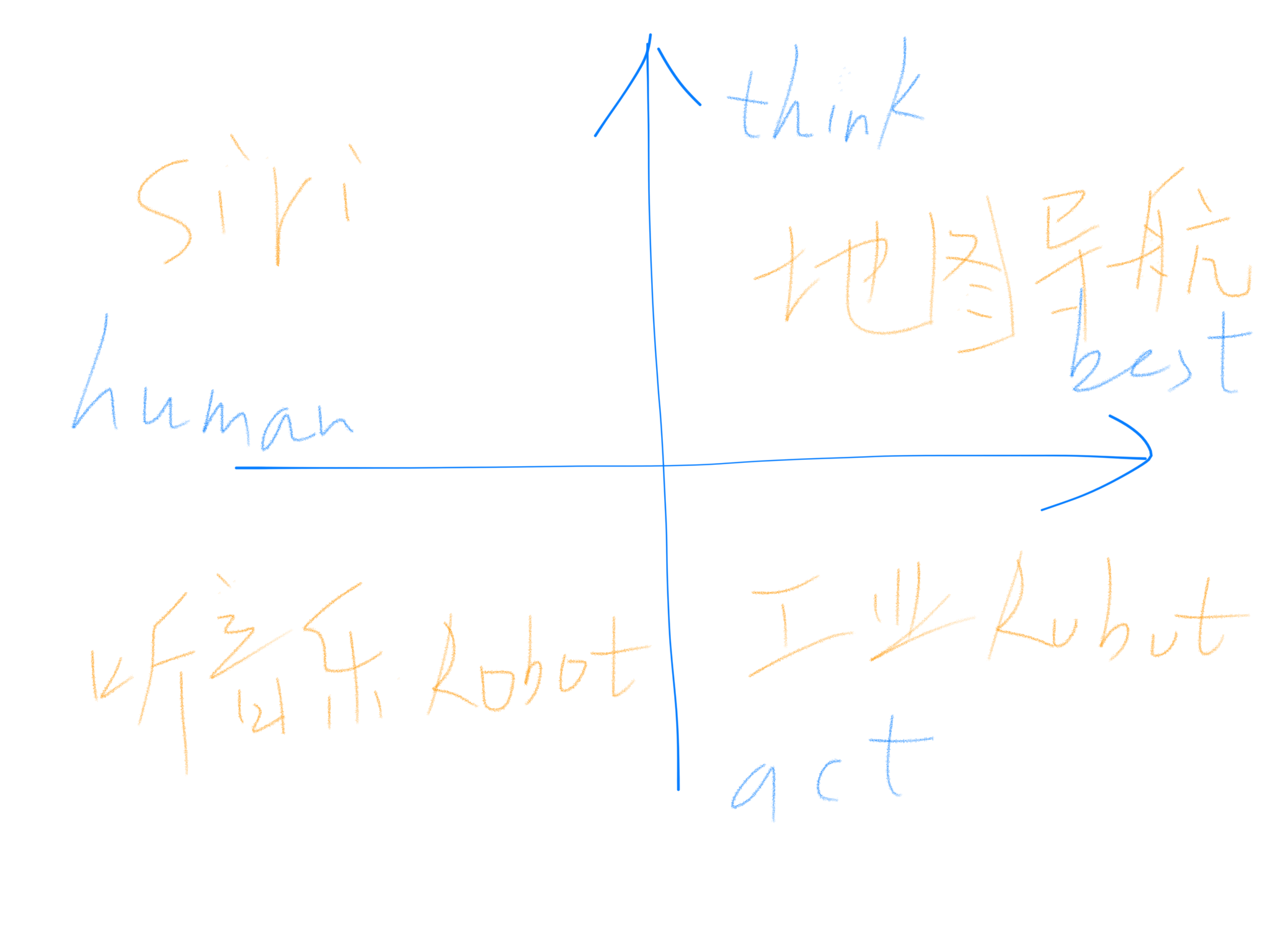
四象限
从 “是否类人类”、“是否产生动作” 两个方向,又可以将人工智能化分为四个象限
在 $x$ 轴正方向上,我们希望 AI 系统只需给出某类问题的最优解,并不用考虑是否会和人类一样去思考这个问题,例如地图导航系统,只需要算出两点的最佳路径即可。而 $x$ 轴的负方向上,则希望 AI 系统能表现出人类的思想活动,比如能听着音乐点头、摇摆的机器人,能去享受旋律;另一方面,在 $y$ 轴的正方向上,AI 系统更侧重于思考,譬如 类似 Siri™ 助理系统,可以处理人们通过语音输入的指令,并能思考出最为合理的反应。而 $y$ 轴的负方向上,则会偏向于动作的产生,比方说流水线上完成材料加工、处理工作的工业机器人
常见误区
OverSampling 和 Data Augmentation 的区别
Transfer Learning 和 Fine-tuning 的区别
资料
Doc
Blog
机器学习
人工智能
- 有哪些 AI 开源框架可供开发者使用?
- 理解 LSTM 网络
- Deep Learning-TensorFlow(14)CNN 卷积神经网络:深度残差网络 ResNet
- Using Artificial Intelligence to Write Self-Modifying/Improving Programs
- CNN 浅析和历年 ImageNet 冠军模型解析
- 变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作。
- Exploring LSTMs
- Calculus on Computational Graphs: Backpropagation
- Convolutional neural networks for artistic style transfer
强化学习
- 深度强化学习导引
- 深度强化学习 强化学习概述
- 走向通用人工智能之路
- DQN 从入门到放弃系列
- 强化学习(reinforcement learning)有什么好的开源项目、网站、文章推荐一下?
- Deep Reinforcement Learning: Pong from Pixels
- Train Your Reinforcement Learning Agents at the OpenAI Gym
- David silve’s tutorial on ICML’16
胶囊网络
- Dynamic Routing Between Capsules
- Part I: Intuition
- Part II: How Capsules Work
- Part III: Dynamic Routing Between Capsules
- Part IV: CapsNet Architecture
Book
统计学
微积分
概率论
机器学习
- 机器学习(周志华 著)
又名"西瓜书"
人工智能
- 人工智能的未来
- Deep Learning(Yoshua Bengio 著)
又名"花书" - Tensorflow:实战 Google 深度学习框架
- 深度学习:21 天实战 Caffe
- 深度学习:Caffe 之经典模型详解与实战
强化学习
- Reinforcement Learning: An Introduction
- Reinforcement Learning: With Open AI, TensorFlow and Keras Using Python
- Algorithms for Reinforcement Learning
- Reinforcement Learning State-of-the-Art
Code
Course
Data
- Your Home for Data Science
- The home of the U.S. Government´s open data
- NASA + ImageNet + Google + 新闻 + 自动驾驶 + 图像 + 生物 数据集
(加群后免费获取)
Resource
Markdown
Paper
- HIERARCHICAL TEMPORAL MEMORY including HTM Cortical Learning Algorithms
- AlphaGo: Mastering the Game of Go with Deep Neural Networks and Tree Search
- AlphaZero: Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
- Deep Reinforcement Learning Papers
- Awesome Reinforcement Learning
Video
- 麻省理工公开课:线性代数
- CS229: Machine Learning
- CS224n: Natural Language Processing with Deep Learning
- CS188: Artificial Intelligence
- CS294: Deep Reinforcement Learning
- CMU10703: Deep Reinforcement Learning and Control
- UCL Course on RL
- Andrew Ng: Neural Networks and Deep Learning
- Beginner´s Guide to NuPIC
- HTM School
- One Hot Gym Anomaly Tutorial
- Introduction to Reinforcement Learning
Tool
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| 大数据 | |
| 算法 | |
| 数据库 |