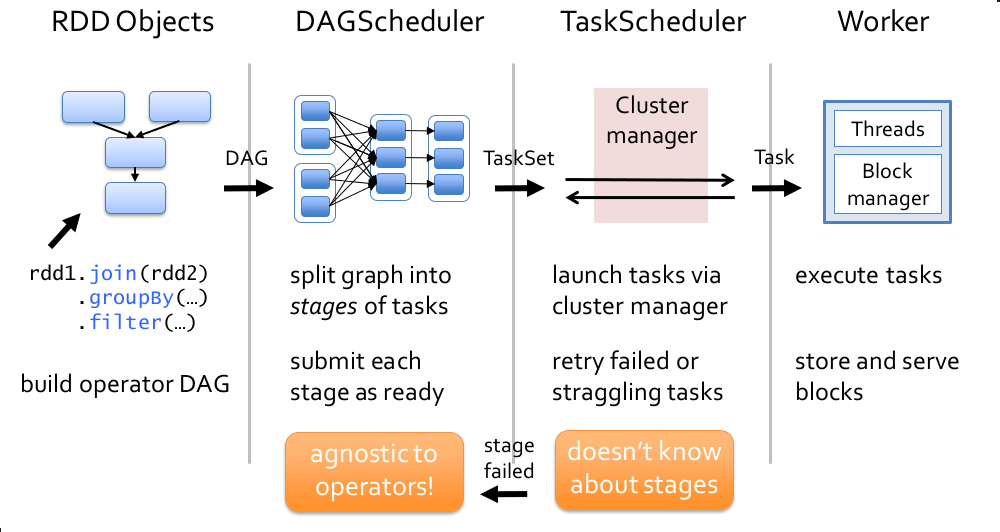
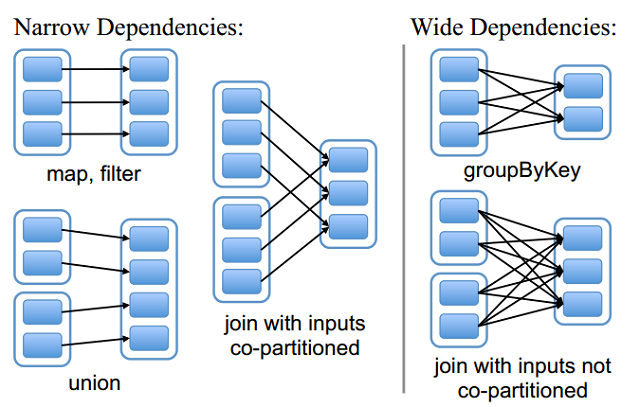
valMaxEvents = 100 valNumFeatures = 100 val random = newRandom() defgenerateRandomArray(n: Int) = Array.tabulate(n)(_ => random.nextGaussian()) val w = newDenseVector(generateRandomArray(NumFeatures)) val intercept = random.nextGaussian() * 10 defgenerateNoisyData(n: Int) = { (1 to n).map { i => val x = newDenseVector(generateRandomArray(NumFeatures)) // inner product val y: Double = w.dot(x) val noisy = y + intercept (noisy, x) } }
if (args.length < 4) { System.err.println("Usage: WindowCounter <master> <hostname> <port> <interval> \n" + "In local mode, <master> should be 'local[n]' with n > 1") System.exit(1) } val ssc = newStreamingContext(args(0), "ML Analysis", Seconds(args(3).toInt))
获取到发送过来的 源数据
1
val stream = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY_SER)
valNumFeatures = 100 val zeroVector = DenseVector.zeros[Double](NumFeatures) val model = newStreamingLinearRegressionWithSGD() .setInitialWeights(Vectors.dense(zeroVector.data)) .setNumIterations(1) .setStepSize(0.01) val labeledStream = stream.map { event => val split = event.split("\t") val y = split(0).toDouble val features = split(1).split(",").map(_.toDouble) LabeledPoint(label = y, features = Vectors.dense(features)) }
利用 模型 进行 train / predict
1 2 3 4 5 6 7 8
model.trainOn(labeledStream) val predictAndTrue = labeledStream.transform { rdd => val latest = model.latestModel() rdd.map { point => val predict = latest.predict(point.features) (predict - point.label) } }
// saveAsTextFile 方法的第二个参数可以指定压缩类型,可以覆盖全局配置中,已经存在的压缩配置 // 需要注意的是,压缩算法只支持 CompressionCodec 接口的实现子类,包括 DefaultCodec、BZip2Codec、GzipCodec、HadoopSnappyCodec、Lz4Codec、SnappyCodec etc. sc.parallelize(Seq(1 to 10), 1).coalesce(1, shuffle = true).saveAsTextFile("/user/yuzhouwan1", classOf[org.apache.hadoop.io.compress.GzipCodec])
无法判断 Spark session 中临时函数是否存在
描述
1 2 3 4
# 获取 session state 中判断临时函数 FunctionIdentifier 是否存在,但是仍然不行 if (!sparkSession.sessionState.catalog.functionExists(yuzhouwanIdentifier)) { sparkSession.sql("CREATE TEMPORARY FUNCTION yuzhouwan as 'org.apache.spark.sql.hive.udf.YuZhouWan'") }
解决
1 2 3
if (!sparkSession.catalog.functionExists("yuzhouwan")) { sparkSession.sql("CREATE TEMPORARY FUNCTION yuzhouwan as 'org.apache.spark.sql.hive.udf.YuZhouWan'") }
补充
目前,Spark SQL 中 IF NOT EXISTS 的语法只支持创建 DATABASE、TABLE(包括 临时表 和 外部表)、VIEW(不包括 临时视图)、SCHEMA 的时候使用,尚不支持临时函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
$ spark-shell --master local
scala> org.apache.spark.sql.SparkSession.builder().enableHiveSupport.getOrCreate.sql("CREATE TEMPORARY FUNCTION IF NOT EXISTS yuzhouwan as 'org.apache.spark.sql.hive.udf.YuZhouWan'")
== SQL == CREATE TEMPORARY FUNCTION IF NOT EXISTS yuzhouwan as 'org.apache.spark.sql.hive.udf.YuZhouWan' -----------------------------^^^ at org.apache.spark.sql.catalyst.parser.ParseException.withCommand(ParseDriver.scala:197) at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:99) at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:45) at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parsePlan(ParseDriver.scala:53) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:592) ... 48 elided
Caused by: kafka.common.OffsetOutOfRangeException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at java.lang.Class.newInstance(Class.java:374) at kafka.common.ErrorMapping$.exceptionFor(ErrorMapping.scala:86) at org.apache.spark.streaming.kafka.KafkaRDD$KafkaRDDIterator.handleFetchErr(KafkaRDD.scala:184) at org.apache.spark.streaming.kafka.KafkaRDD$KafkaRDDIterator.fetchBatch(KafkaRDD.scala:193) at org.apache.spark.streaming.kafka.KafkaRDD$KafkaRDDIterator.getNext(KafkaRDD.scala:208) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.storage.memory.MemoryStore.putIteratorAsValues(MemoryStore.scala:215) at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:957) at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:948) at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:888) at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:948) at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:694) at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:334) at org.apache.spark.rdd.RDD.iterator(RDD.scala:285) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323) at org.apache.spark.rdd.RDD.iterator(RDD.scala:287) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)