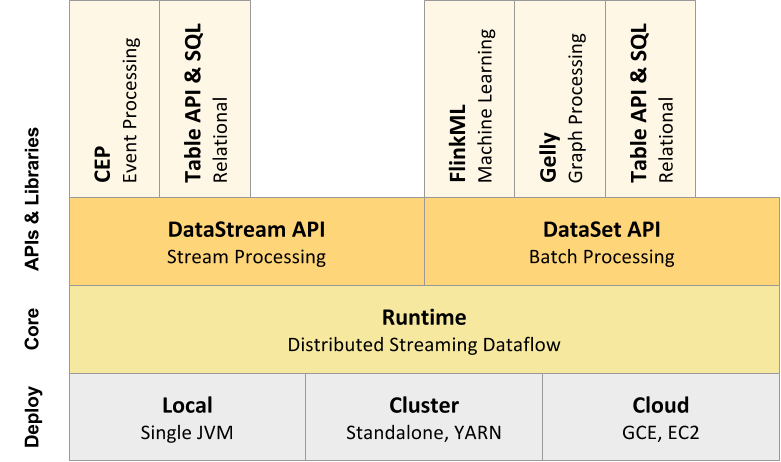
Apache Flink™ is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
还有一种方法,可以将程序提交至远程集群上,通过 ExecutionEnvironment.getExecutionEnvironment() 方法 获取执行环境,并通过 maven-assembly-plugin 插件,将程序打包成单个可执行的 jar 包,并在 Web UI 上找到 Submit new Job 模块,完成上传、展示执行和最终提交任务至集群
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(ServerLogProcess.java:46)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface. at org.apache.flink.streaming.api.transformations.StreamTransformation.getOutputType(StreamTransformation.java:374) at org.apache.flink.streaming.api.graph.StreamGraphGenerator.transform(StreamGraphGenerator.java:159) at org.apache.flink.streaming.api.graph.StreamGraphGenerator.generateInternal(StreamGraphGenerator.java:129) at org.apache.flink.streaming.api.graph.StreamGraphGenerator.generate(StreamGraphGenerator.java:121) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:1526) at org.apache.flink.streaming.api.environment.LocalStreamEnvironment.execute(LocalStreamEnvironment.java:87) at com.yuzhouwan.hbase.monitor.server.log.process.ServerLogProcess.main(ServerLogProcess.java:58) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147) Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Either' are missing. It seems that your compiler has not stored them into the .classfile. Currently, only the Eclipse JDT compiler preserves the type information necessary to use the lambdas feature type-safely. See the documentation for more information about how to compile jobs containing lambda expressions. at org.apache.flink.api.java.typeutils.TypeExtractor.validateLambdaGenericParameter(TypeExtractor.java:1503) at org.apache.flink.api.java.typeutils.TypeExtractor.validateLambdaGenericParameters(TypeExtractor.java:1489) at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:426) at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:379) at org.apache.flink.api.java.typeutils.TypeExtractor.getMapReturnTypes(TypeExtractor.java:164) at org.apache.flink.streaming.api.datastream.DataStream.map(DataStream.java:527) at com.yuzhouwan.hbase.monitor.server.log.process.ServerLogProcess.main(ServerLogProcess.java:46) ... 5 more
java.lang.IllegalStateException: Cannot retrieve Left value on a Right at org.apache.flink.types.Either$Right.left(Either.java:172) ~[flink-core-1.3.1.jar:1.3.1] at com.yuzhouwan.hbase.monitor.server.log.store.StoreData2ES.lambda$createEsSinkFunction$8bb6efc1$1(StoreData2ES.java:102) ~[classes/:na] at org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase.invoke(ElasticsearchSinkBase.java:282) ~[flink-connector-elasticsearch-base_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:41) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator(OperatorChain.java:528) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:503) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:483) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:891) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:869) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:51) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.cep.PatternStream$PatternFlatSelectTimeoutWrapper$RightCollector.collect(PatternStream.java:374) ~[flink-cep_2.11-1.3.1.jar:1.3.1] at com.yuzhouwan.hbase.monitor.server.log.analyse.func.select.SelectFunctionWarn.lambda$flatSelect$0(SelectFunctionWarn.java:39) ~[classes/:na] at java.util.ArrayList.forEach(ArrayList.java:1249) ~[na:1.8.0_111] at com.yuzhouwan.hbase.monitor.server.log.analyse.func.select.SelectFunctionWarn.flatSelect(SelectFunctionWarn.java:37) ~[classes/:na] at org.apache.flink.cep.PatternStream$PatternFlatSelectTimeoutWrapper.flatMap(PatternStream.java:341) ~[flink-cep_2.11-1.3.1.jar:1.3.1] at org.apache.flink.cep.PatternStream$PatternFlatSelectTimeoutWrapper.flatMap(PatternStream.java:320) ~[flink-cep_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.api.operators.StreamFlatMap.processElement(StreamFlatMap.java:50) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:206) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:262) ~[flink-streaming-java_2.11-1.3.1.jar:1.3.1] at org.apache.flink.runtime.taskmanager.Task.run(Task.java:702) ~[flink-runtime_2.11-1.3.1.jar:1.3.1] at java.lang.Thread.run(Thread.java:745) [na:1.8.0_111]
java.lang.IllegalArgumentException: The implementation of the provided ElasticsearchSinkFunction is not serializable. The object probably contains or references non-serializable fields. at org.apache.flink.util.Preconditions.checkArgument(Preconditions.java:139) ~[flink-core-1.3.0.jar:1.3.0] at org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase.<init>(ElasticsearchSinkBase.java:195) ~[flink-connector-elasticsearch-base_2.11-1.3.0.jar:1.3.0] at org.apache.flink.streaming.connectors.elasticsearch5.ElasticsearchSink.<init>(ElasticsearchSink.java:95) ~[flink-connector-elasticsearch5_2.11-1.3.0.jar:1.3.0] at org.apache.flink.streaming.connectors.elasticsearch5.ElasticsearchSink.<init>(ElasticsearchSink.java:78) ~[flink-connector-elasticsearch5_2.11-1.3.0.jar:1.3.0] at com.yuzhouwan.hbase.monitor.server.log.store.StoreData2ES.initEsSink(StoreData2ES.java:89) ~[classes/:na] at com.yuzhouwan.hbase.monitor.server.log.store.StoreData2ES.init(StoreData2ES.java:85) ~[classes/:na] at com.yuzhouwan.hbase.monitor.server.log.store.StoreData2ES.<init>(StoreData2ES.java:50) ~[classes/:na] at com.yuzhouwan.hbase.monitor.server.log.process.ServerLogProcess.main(ServerLogProcess.java:52) ~[classes/:na]
org.apache.flink.api.common.InvalidProgramException: The implementation of the IterativeCondition is not serializable. The object probably contains or references non serializable fields.
java.lang.RuntimeException: Could not extract key from null at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:104) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:83) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:41) at org.apache.flink.streaming.runtime.tasks.OperatorChain$BroadcastingOutputCollector.collect(OperatorChain.java:575) at org.apache.flink.streaming.runtime.tasks.OperatorChain$BroadcastingOutputCollector.collect(OperatorChain.java:536) at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:891) at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:869) at org.apache.flink.streaming.api.operators.StreamMap.processElement(StreamMap.java:41) at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator(OperatorChain.java:528) at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:503) at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:483) at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:891) at org.apache.flink.streaming.api.operators.AbstractStreamOperator$CountingOutput.collect(AbstractStreamOperator.java:869) at org.apache.flink.streaming.api.operators.StreamSourceContexts$NonTimestampContext.collect(StreamSourceContexts.java:103) at org.apache.flink.streaming.connectors.kafka.internals.AbstractFetcher.emitRecord(AbstractFetcher.java:228) at org.apache.flink.streaming.connectors.kafka.internals.SimpleConsumerThread.run(SimpleConsumerThread.java:385) Caused by: java.lang.RuntimeException: Could not extract key from null at org.apache.flink.streaming.runtime.partitioner.KeyGroupStreamPartitioner.selectChannels(KeyGroupStreamPartitioner.java:61) at org.apache.flink.streaming.runtime.partitioner.KeyGroupStreamPartitioner.selectChannels(KeyGroupStreamPartitioner.java:32) at org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit(RecordWriter.java:88) at org.apache.flink.streaming.runtime.io.StreamRecordWriter.emit(StreamRecordWriter.java:85) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:101) ... 15 more Caused by: org.apache.flink.types.NullKeyFieldException: Unable to access field java.lang.Integer com.yuzhouwan.hbase.monitor.server.log.data.model.HBaseServerLog.flumeId on object null at org.apache.flink.api.java.typeutils.runtime.PojoComparator.accessField(PojoComparator.java:181) at org.apache.flink.api.java.typeutils.runtime.PojoComparator.extractKeys(PojoComparator.java:329) at org.apache.flink.streaming.util.keys.KeySelectorUtil$ComparableKeySelector.getKey(KeySelectorUtil.java:185) at org.apache.flink.streaming.util.keys.KeySelectorUtil$ComparableKeySelector.getKey(KeySelectorUtil.java:162) at org.apache.flink.streaming.runtime.partitioner.KeyGroupStreamPartitioner.selectChannels(KeyGroupStreamPartitioner.java:59) ... 19 more